广东省旅游景点数据分析全攻略
在上一篇文章中,我们已经完成了广东省旅游景点数据的收集,现在让我们一起深入了解这些数据背后的故事!
数据准备与清洗
首先,让我们加载数据并进行必要的清理:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
df = pd.read_csv('attractions_data.csv')
# 数据清洗
df['commentScore'] = pd.to_numeric(df['commentScore'], errors='coerce')
df['heatScore'] = pd.to_numeric(df['heatScore'], errors='coerce')
df_cleaned = df[(df['commentScore'] > 0) & (df['heatScore'] > 0)].dropna(subset=['commentScore', 'heatScore'])
数据清洗重点:
- 将评分列转为数值类型
- 过滤掉评分为零或缺失的数据
- 确保分析数据的质量
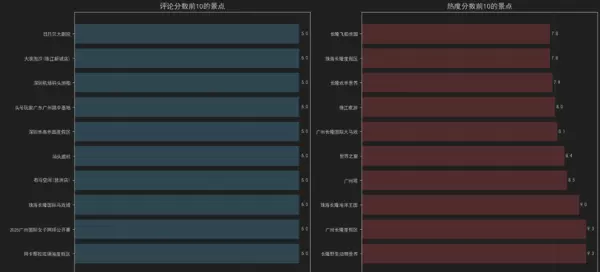
景点评分TOP10分析
评论分数 vs 热度分数
# 获取各类TOP10数据
top_comment = df_cleaned.nlargest(10, 'commentScore')[['poiName', 'commentScore', 'districtName']]
top_heat = df_cleaned.nlargest(10, 'heatScore')[['poiName', 'heatScore', 'districtName']]
通过对比分析,我们发现:
- 评论分数反映了游客的满意度
- 热度分数体现了景点的受欢迎程度
- 两者排名可能有差异,揭示了不同维度的受欢迎情况
可视化展示
我们使用并排条形图直观展示TOP10景点:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 8))
# 左侧:评论分数TOP10
bars1 = ax1.barh(range(len(top_comment)), top_comment['commentScore'], color='skyblue', alpha=0.7)
# 右侧:热度分数TOP10
bars2 = ax2.barh(range(len(top_heat)), top_heat['heatScore'], color='lightcoral', alpha=0.7)
图表特点:
- 水平条形图方便阅读长景点名称
- 不同颜色区分评分类型
- 网格线提升可读性
- 数值标签直接显示具体分数
服务设施词云分析
数据处理流程
def process_service_data(service_text):
if pd.isna(service_text) or service_text == '未提供':
return []
# 分割服务项目
services = re.split(r'[,,、\s]+', str(service_text))
services = [s.strip() for s in services if s.strip()]
return services
词云生成
wordcloud = WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf',
width=800,
height=600,
background_color='white',
colormap='viridis',
max_words=50
).generate_from_frequencies(service_counter)
分析价值:
- 快速识别景区提供的核心服务
- 发现服务设施分布规律
- 为游客提供设施预期参考

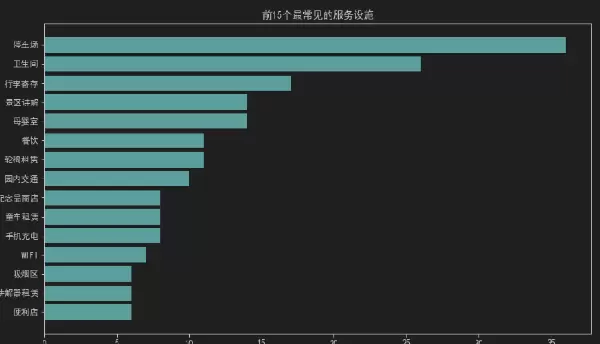
服务设施排行榜
通过条形图展示前15个最常见的服务设施:
plt.barh(services, counts, color='lightseagreen')
plt.xlabel('出现次数')
plt.title('前15个最常见的服务设施')
实用发现:
- 停车场、餐厅、WiFi成为基本服务
- 特殊服务设施展示了景区的独特性
- 服务完善程度与景区级别呈正比关系
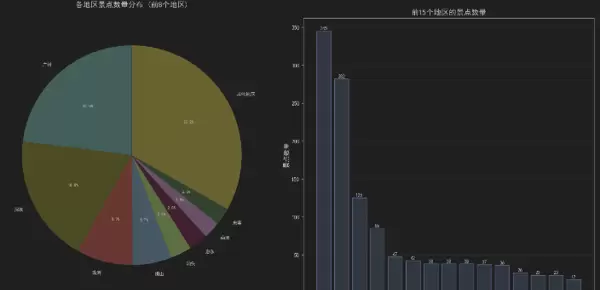
地区分布分析
数据统计
district_counts = df['districtName'].value_counts()
total_attractions = len(df)
district_percentages = (district_counts / total_attractions * 100).round(2)
可视化方案
采用饼图加条形图的双重展示:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 8))
# 左侧饼图 - 展示分布比例
wedges, texts, autotexts = ax1.pie(...)
# 右侧条形图 - 精确数量对比
bars = ax2.bar(range(len(top_15)), top_15.values, color='lightsteelblue')
????
地区分布洞察:
广州、深圳等核心城市景点集中
粤东粤西地区旅游资源丰富
区域分布反映经济发展与旅游资源的关系
???? 核心发现总结
- 评分双维度分析 ????
评论分数与热度分数从不同角度反映景点品质,为游客提供全面参考。
- 服务设施标准化 ????
基本服务设施趋于标准化,特色服务成为景区差异化竞争的关键。
- 区域集中效应显著 ????
经济发达地区景点密度更高,旅游资源分布与经济发展水平紧密相关。
- 数据驱动旅游决策 ????
通过多维度数据分析,为游客提供科学的出行参考依据。
实用建议
对游客:
- 参考双维度评分选择目的地
- 根据服务设施需求筛选景区
- 结合地区特色规划旅行路线
对景区管理者:
- 完善基础服务设施
- 提升游客体验以获得更高评分
- 挖掘特色服务增强竞争力
通过这份数据分析,我们不仅看到了数字背后的旅游格局,更为智慧旅游提供了数据支持。下次旅行前,不妨先看看数据怎么说!


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





