经管之家App
让优质教育人人可得
立即打开


在自动化数据分析产品中,数据对接扮演着连接业务系统与人工智能模型的重要角色。根据《中国数字经济发展报告(2023)》,超过41%的企业在数据对接与整合过程中花费的时间超出预期,这直接影响了后续的分析与决策过程。目前,主要的数据对接方法包括数据库直接连接、API接口调用以及文件同步等,每种方法都有其独特的技术实现和应用场景。
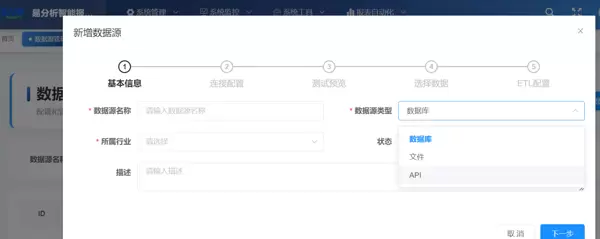
数据库直连是最常见的企业数据接入方式之一,它利用JDBC、ODBC等标准化协议直接与主流数据库建立连接。该技术能够支持超过20种数据库的直接连接,包括MySQL、Oracle、SQL Server、PostgreSQL等。以下是数据库直连的技术架构示例:
// JDBC连接示例
String url = "jdbc:mysql://localhost:3306/sales_data?useSSL=false";
String user = "data_analyst";
String password = "EncryptedPassword123!";
Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM monthly_sales WHERE region='华东'");直接连接数据库存在一定的安全风险,例如,某电商平台因为测试环境中数据库账户信息泄露,导致300万条用户数据被盗。为解决这一问题,可以采取以下措施:
API接口调用已经成为SaaS服务和云计算应用集成的标准途径,支持RESTful和SOAP等多种协议。采用API-first的设计理念,其关键技术实现包括以下几个方面:
// 销售数据API响应示例
{
"code": 200,
"message": "success",
"data": {
"total_sales": 1568900.50,
"order_count": 3245,
"region_distribution": [
{"region": "华北", "amount": 456200.80},
{"region": "华东", "amount": 621500.30},
{"region": "华南", "amount": 491200.40}
],
"update_time": "2025-11-18T08:30:15Z"
}
}例如,一家互联网金融公司通过API调用第三方信用评估数据,采取以下优化措施后,响应时间从3秒降低到了200毫秒:
文件同步适用于大批量数据交换的场景,通常通过FTP、SFTP或OSS等协议完成数据传输。在技术实现上,需要注意以下几个关键点:
# Airflow DAG配置示例
default_args = {
'owner': 'data_team',
'depends_on_past': False,
'start_date': datetime(2025, 1, 1),
'email_on_failure': True,
'email': ['data@company.com']
}
dag = DAG('sales_data_sync', default_args=default_args, schedule_interval='0 1 * * *')
sync_task = BashOperator(
task_id='sftp_sync',在Airflow中配置了一个数据同步任务,该任务负责从远程服务器下载销售数据CSV文件到本地指定目录。具体命令如下:
bash_command='sftp -i /keys/sftp_key data_user@192.168.1.100:/data/sales_*.csv /local/data/', dag=dag
随后,定义了一个Python操作任务用于处理这些数据:
process_task = PythonOperator(task_id='data_process', python_callable=process_sales_data, dag=dag)
为了确保数据同步和处理的连续性,设置了同步任务完成后触发数据处理任务的流程:sync_task >> process_task
针对物联网设备数据及日志数据等高频次实时数据,推荐使用流式数据接入技术。一种常见的架构是结合Kafka和Flink,例如一个智能工厂项目中,利用此技术实现了设备传感器数据的即时分析:
// Flink流处理示例
val sensorData = env.addSource(new FlinkKafkaConsumer[String]("sensor_topic", new SimpleStringSchema(), properties))
.map(json => {
val obj = new JSONObject(json)
(obj.getString("device_id"), obj.getDouble("temperature"), obj.getLong("timestamp"))
})
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.reduce((a, b) => (a._1, (a._2 + b._2)/2, b._3))
sensorData.addSink(new RedisSink(redisConfig))
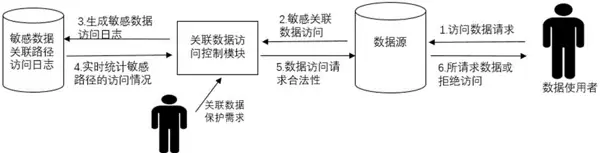
数据安全是人工智能自动化分析中的关键挑战之一,涉及数据传输、存储和访问等多个环节的安全防护。根据IBM发布的《2024年数据泄露成本报告》,企业因数据泄露而面临的平均成本已高达488万美元,而建立完善的数据安全体系则能显著降低这一风险,减少超过60%的数据泄露可能性。
为确保数据在传输和存储过程中的安全性,建议采取以下措施:

数据脱敏技术是保护敏感信息的重要手段,特别适用于开发测试环境和数据分析场合。腾讯云智能运营分析助手提供了多级别的脱敏策略,包括但不限于:
技术实现上,通过SQL重写技术实现在查询时对敏感字段进行动态脱敏:
-- 动态脱敏策略定义
CREATE MASKING POLICY phone_mask ON customer.phone USING ('*-*-' || SUBSTRING(phone, 8, 4)) FOR ROLES analyst;
-- 查询时自动脱敏
SELECT name, phone FROM customer WHERE region='北京';
-- 结果:张三,*-***-5678
据某银行的实际应用案例,动态数据脱敏技术有效降低了开发测试环境中90%的数据泄露风险,并且符合《个人信息保护法》的相关规定。
基于零信任原则的访问控制体系是确保数据安全的核心,其核心理念是“永不信任,始终验证”。常用的权限管理模型结合了RBAC(基于角色的访问控制)和ABAC(基于属性的访问控制):
# ABAC权限判断逻辑
def is_allowed(user, data, action):
# 用户部门与数据部门匹配
if user.department != data.department and not user.is_admin:
return False
# 工作时间限制
if not is_work_time() and action == 'download':
return False返回 False
# IP地址限制
if not is_office_ip(user.ip) and action == 'modify':
return False
return True
ISO 27001 是国际上公认的信息安全标准,它为 AI 数据分析产品提供了全面的安全管理框架。该标准的核心要求包括:

《数据安全法》对 AI 数据分析产品提出了明确的合规要求,企业应重点关注以下几个方面:
某互联网企业因未能履行数据安全义务而被罚款 500 万元,这一案例为企业敲响了警钟。建议企业建立数据合规自查清单,并每季度进行合规检查。
选择合适的数据对接技术需要综合考虑数据特性、业务需求和资源限制。以下是一个决策参考框架:
| 因素 | 数据库直连 | API 调用 | 文件同步 | 流式接入 |
|---|---|---|---|---|
| 数据量 | 中-大 | 小-中 | 大 | 极大 |
| 实时性 | 高 | 中-高 | 低 | 最高 |
| 复杂度 | 低 | 中 | 低 | 高 |
| 成本 | 低 | 中 | 低 | 高 |
| 适用场景 | 业务报表 | SaaS 集成 | 批量数据 | IoT/日志 |
企业数据安全体系建设应分阶段实施,建议的路线图如下:
AI 自动化数据分析产品的数据对接与安全保障是一项系统工程,需要技术、流程和管理的协同配合。随着《数据安全法》等法规的实施和技术的发展,未来将出现以下趋势:
对于企业而言,建议从实际业务需求出发,选择合适的数据对接方案,同时构建多层次的安全体系,在确保数据安全的前提下充分发挥 AI 分析的价值。如有需要,可以搜索“易分析 AI 生成 PPT 软件”。通过技术创新和最佳实践,实现数据“可用不可见,可控可计量”,为业务决策提供安全可靠的数据支持。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




