经管之家App
让优质教育人人可得
立即打开


# 整形和浮点型
a = 10
b = 10.2
# 复数
c = complex(1, 2)'''
int(x) 将x转换为一个整数。
float(x) 将x转换到一个浮点数。
complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
'''
a = 1.0
b = int(a) # 将a转成整形print(2 + 2)
print(10 / 3) # 总是返回一个浮点数,不同的计算机上得到的结果可能不同,是由于精度问题name = 'python'
gender = "male"res=str({'a':1})
print(res,type(res))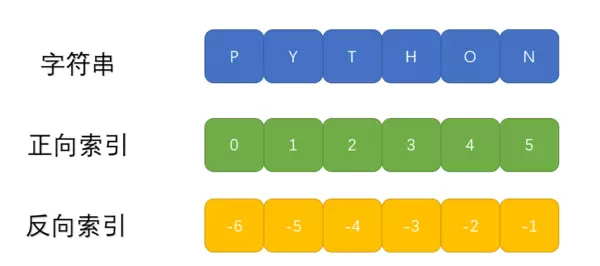 若需提取某个特定位置的字符,可通过索引方式进行访问,支持正向和反向取值。
若需提取某个特定位置的字符,可通过索引方式进行访问,支持正向和反向取值。
my_str = 'python'
# 正向取值
str1 = my_str[0] # P
str2 = my_str[5] # n
# 反向取值
str3 = my_str[-1] # n
str4 = my_str[-6] # P'''
变量[起始索引:结束索引:步长]
注意:[]取值顾头不顾尾,取出的子字符串不包括结束索引对应的值,可以通过控制步长操作输出的子字符串
'''
my_str = 'python'
# 正向切片
str1 = my_str[0: 5] # pytho
str2 = my_str[0: 5] # 等价于my_str[0: 5: 1] ,步长是1
str3 = my_str[0: 5: 2] # 步长等于2,相当于从第一个字符开始每隔一个取一个值,所以结果是 pto
str4 = my_str[5: 0: -1] # 步长可以为负数,表示从倒序取子字符串,结果是 nohty
str5 = my_str[:] # 表示取字符串中的所有字符, python
str6 = my_str[::] # 表示取字符串中的所有字符, python
str7 = my_str[::-1] # 表示将字符串反转,nohtyp
# 反向切片
str6 = my_str[-1: -3: -1] # nomy_str = 'python'
print(len(my_str)) # 6# in 判断hello 是否在 str1里面
>>> 'hello' in str1
True
# not in:判断tony 是否不在 str1里面
>>> 'tony' not in str1
Truemy_str = 'python'
# 字符串是可迭代对象,依次取出字符串中的每个字符
for i in my_str:
print(i)a = hello
b = world
# + 字符串拼接操作
print(a + b) # helloworld
# * 重复输出字符串
print(a * 2) # hellohellostr1 = '**tony***'
# 括号内不指定字符,默认移除空白字符,比如空格 制表符tab
str1.strip('*') # 移除左右两边的指定字符
str1.lstrip('*') # 只移除左边的指定字符
str1.rstrip('*') # 只移除右边的指定字符split() rsplit()# 括号内不指定字符,默认以空格作为切分符号
str3 = 'hello world'
b = str3.split()
print(b) # ['hello', 'world']
# split会按照从左到右的顺序对字符串进行切分,可以指定切割次数
str5='C:/a/b/c/d.txt'
print(str5.split('/',1)) # ['C:', 'a/b/c/d.txt']
# rsplit刚好与split相反,从右往左切割,可以指定切割次数
str5='a|b|c'
print(str5.rsplit('|',1)) # ['a|b', 'c']lower() upper()>>> str2 = 'My nAme is tonY!'>>> str2.lower() # 将英文字符串全部变小写my name is tony!>>> str2.upper() # 将英文字符串全部变大写MY NAME IS TONY!startswith() endswith()>>> str3 = 'tony jam'# startswith()判断字符串是否以括号内指定的字符开头,结果为布尔值True或False>>> str3.startswith('t') True>>> str3.startswith('j')False# endswith()判断字符串是否以括号内指定的字符结尾,结果为布尔值True或False>>> str3.endswith('jam')True>>> str3.endswith('tony') Falsejoin()>>> '%'.join('hello') # 从字符串'hello'中取出多个字符,然后按照%作为连接符进行拼接'h%e%l%l%o'>>> '|'.join(['tony','18','read']) # 从列表中取出多个字符,然后按照|作为连接符进行拼接'tony|18|read'replace()方法>>> str7 = 'my name is tony, my age is 18!' # 将tony的年龄由18岁改成73岁>>> str7 = str7.replace('18', '73') # 语法:replace('旧内容', '新内容')>>> str7my name is tony, my age is 73!# 可以指定修改的个数>>> str7 = 'my name is tony, my age is 18!'>>> str7 = str7.replace('my', 'MY',1) # 只把一个my改为MY>>> str7'MY name is tony, my age is 18!'isdigit()>>> str8 = '5201314'>>> str8.isdigit()True>>> str8 = '123g123'>>> str8.isdigit()Falsecenter() ljust() rjust() zfill()>>> name='tony'>>> name.center(30,'-') # 总宽度为30,字符串居中显示,不够用-填充-------------tony------------->>> name.ljust(30,'*') # 总宽度为30,字符串左对齐显示,不够用*填充tony**************************>>> name.rjust(30,'*') # 总宽度为30,字符串右对齐显示,不够用*填充**************************tony>>> name.zfill(50) # 总宽度为50,字符串右对齐显示,不够用0填充0000000000000000000000000000000000000000000000tonycaptalize(),swapcase(),title()# captalize:首字母大写>>> message = 'hello everyone nice to meet you!'>>> message.capitalize()Hello everyone nice to meet you! # swapcase:大小写翻转>>> message1 = 'Hi girl, I want make friends with you!'>>> message1.swapcase() hI GIRL, i WANT MAKE FRIENDS WITH YOU! # title:每个单词的首字母大写>>> msg = 'dear my friend i miss you very much'>>> msg.title()Dear My Friend I Miss You Very Much

# 整形和浮点型
a = 10
b = 10.2
# 复数
c = complex(1, 2)'''
int(x) 将x转换为一个整数。
float(x) 将x转换到一个浮点数。
complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
'''
a = 1.0
b = int(a) # 将a转成整形print(2 + 2)
print(10 / 3) # 总是返回一个浮点数,不同的计算机上得到的结果可能不同,是由于精度问题name = 'python'
gender = "male"res=str({'a':1})
print(res,type(res))my_str = 'python'
# 正向取值
str1 = my_str[0] # P
str2 = my_str[5] # n
# 反向取值
str3 = my_str[-1] # n
str4 = my_str[-6] # P'''
变量[起始索引:结束索引:步长]
注意:[]取值顾头不顾尾,取出的子字符串不包括结束索引对应的值,可以通过控制步长操作输出的子字符串
'''
my_str = 'python'
# 正向切片
str1 = my_str[0: 5] # pytho
str2 = my_str[0: 5] # 等价于my_str[0: 5: 1] ,步长是1
str3 = my_str[0: 5: 2] # 步长等于2,相当于从第一个字符开始每隔一个取一个值,所以结果是 pto
str4 = my_str[5: 0: -1] # 步长可以为负数,表示从倒序取子字符串,结果是 nohty
str5 = my_str[:] # 表示取字符串中的所有字符, python
str6 = my_str[::] # 表示取字符串中的所有字符, python
str7 = my_str[::-1] # 表示将字符串反转,nohtyp
# 反向切片
str6 = my_str[-1: -3: -1] # nomy_str = 'python'
print(len(my_str)) # 6# in 判断hello 是否在 str1里面
>>> 'hello' in str1
True
# not in:判断tony 是否不在 str1里面
>>> 'tony' not in str1
Truemy_str = 'python'
# 字符串是可迭代对象,依次取出字符串中的每个字符
for i in my_str:
print(i)a = hello
b = world
# + 字符串拼接操作
print(a + b) # helloworld
# * 重复输出字符串
print(a * 2) # hellohellostrip() lstrip() rstrip()str1 = '**tony***'
# 括号内不指定字符,默认移除空白字符,比如空格 制表符tab
str1.strip('*') # 移除左右两边的指定字符
str1.lstrip('*') # 只移除左边的指定字符
str1.rstrip('*') # 只移除右边的指定字符split() rsplit()# 括号内不指定字符,默认以空格作为切分符号
str3 = 'hello world'
b = str3.split()
print(b) # ['hello', 'world']
# split会按照从左到右的顺序对字符串进行切分,可以指定切割次数
str5='C:/a/b/c/d.txt'
print(str5.split('/',1)) # ['C:', 'a/b/c/d.txt']
# rsplit刚好与split相反,从右往左切割,可以指定切割次数
str5='a|b|c'
print(str5.rsplit('|',1)) # ['a|b', 'c']lower() upper()>>> str2 = 'My nAme is tonY!'>>> str2.lower() # 将英文字符串全部变小写my name is tony!>>> str2.upper() # 将英文字符串全部变大写MY NAME IS TONY!startswith() endswith()>>> str3 = 'tony jam'# startswith()判断字符串是否以括号内指定的字符开头,结果为布尔值True或False>>> str3.startswith('t') True>>> str3.startswith('j')False# endswith()判断字符串是否以括号内指定的字符结尾,结果为布尔值True或False>>> str3.endswith('jam')True>>> str3.endswith('tony') Falsejoin()>>> '%'.join('hello') # 从字符串'hello'中取出多个字符,然后按照%作为连接符进行拼接'h%e%l%l%o'>>> '|'.join(['tony','18','read']) # 从列表中取出多个字符,然后按照|作为连接符进行拼接'tony|18|read'replace()方法>>> str7 = 'my name is tony, my age is 18!' # 将tony的年龄由18岁改成73岁>>> str7 = str7.replace('18', '73') # 语法:replace('旧内容', '新内容')>>> str7my name is tony, my age is 73!# 可以指定修改的个数>>> str7 = 'my name is tony, my age is 18!'>>> str7 = str7.replace('my', 'MY',1) # 只把一个my改为MY>>> str7'MY name is tony, my age is 18!'isdigit()>>> str8 = '5201314'>>> str8.isdigit()True>>> str8 = '123g123'>>> str8.isdigit()Falsecenter() ljust() rjust() zfill()>>> name='tony'>>> name.center(30,'-') # 总宽度为30,字符串居中显示,不够用-填充-------------tony------------->>> name.ljust(30,'*') # 总宽度为30,字符串左对齐显示,不够用*填充tony**************************>>> name.rjust(30,'*') # 总宽度为30,字符串右对齐显示,不够用*填充**************************tony>>> name.zfill(50) # 总宽度为50,字符串右对齐显示,不够用0填充0000000000000000000000000000000000000000000000tonycaptalize(),swapcase(),title()# captalize:首字母大写>>> message = 'hello everyone nice to meet you!'>>> message.capitalize()Hello everyone nice to meet you! # swapcase:大小写翻转>>> message1 = 'Hi girl, I want make friends with you!'>>> message1.swapcase() hI GIRL, i WANT MAKE FRIENDS WITH YOU! # title:每个单词的首字母大写>>> msg = 'dear my friend i miss you very much'>>> msg.title()Dear My Friend I Miss You Very Much
 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




