Python链家网租房数据分析全攻略
基于先前获取的链家租房数据,本文将带你深入进行数据可视化分析,揭示杭州租房市场的潜在规律。
项目概述
在前一篇文章中,我们成功获取了链家网的租房信息。现在,让我们利用这些珍贵的数据,通过Python的数据处理工具来挖掘其内在价值,为租房决策提供数据支持!
技术栈
- Pandas - 数据处理与分析
- Matplotlib - 数据可视化
- WordCloud - 词云生成
- Jupyter Notebook - 交互式编程环境
数据概览
首先让我们查看一下数据集的基本信息:
import pandas as pd
import matplotlib.pyplot as plt
# 设置中文字体显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
df = pd.read_csv('hangzhou_house.csv')
print(f"数据集包含 {len(df)} 条租房记录")
print("\n数据字段:")
print(df.columns.tolist())
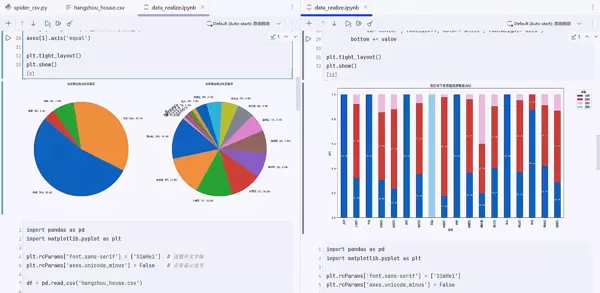
分析维度一:房源类型与区域分布
1. 双饼图对比分析
# 1. 类型分布
type_counts = df['类型'].value_counts()
type_percent = type_counts / type_counts.sum() * 100
type_labels = [f"{name} ({count},{percent:.1f}%)" for name, count, percent in zip(type_counts.index, type_counts, type_percent)]
# 2. 区域分布
area_counts = df['区域'].value_counts()
area_percent = area_counts / area_counts.sum() * 100
area_labels = [f"{name} ({count},{percent:.1f}%)" for name, count, percent in zip(area_counts.index, area_counts, area_percent)]
# 创建并排的两个饼图
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
代码解析:
value_counts()
- 统计每个类别的数量
- 计算百分比并格式化标签,显示具体数量和占比
- 使用
subplots
创建并排子图,便于对比分析
分析洞察:
通过饼图可以直观看出:
- 整租与合租的比例分布
- 杭州各区域的房源供应情况
- 热门租赁区域识别
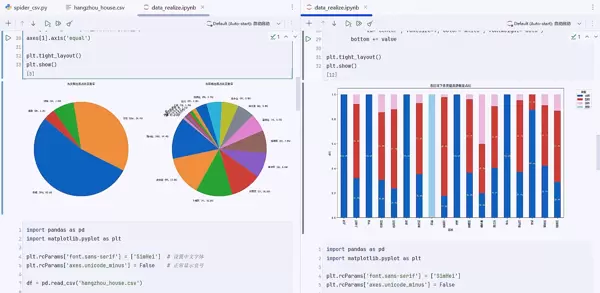
分析维度二:区域-类型交叉分析
2. 堆叠柱状图分析
# 计算各区域下各类型的数量
pivot = pd.pivot_table(df, index='区域', columns='类型', values='标题', aggfunc='count', fill_value=0)
# 计算各类型在各区域的占比
pivot_percent = pivot.div(pivot.sum(axis=1), axis=0)
# 绘制堆叠柱状图
ax = pivot_percent.plot(kind='bar', stacked=True, figsize=(14, 8), colormap='tab20')
代码解析:
pivot_table
div
方法计算百分比,实现标准化堆叠
colormap='tab20'
使用丰富的颜色区分不同类型
分析价值:
- 识别各区域的租赁类型偏好
- 发现特定区域的租赁模式
- 为不同需求的租客提供选址建议
分析维度三:价格深度分析
3. 楼栋类型价格对比
# 强制将价格列转为数值型,无法转换的设为NaN
df['价格(元/月)'] = pd.to_numeric(df['价格(元/月)'], errors='coerce')
# 计算各类型下各楼栋的平均价格
pivot_price = pd.pivot_table(df, index='楼栋', columns='类型', values='价格(元/月)', aggfunc='mean')
# 只显示有数据的楼栋
pivot_price = pivot_price.dropna(how='all')
数据处理技巧:
pd.to_numeric(..., errors='coerce')
dropna(how='all')
只删除全为空值的行
透视表实现多维度的价格分析
商业洞察:
- 不同户型在不同楼栋的价格差异
- 识别性价比高的租赁选择
- 为价格谈判提供数据依据
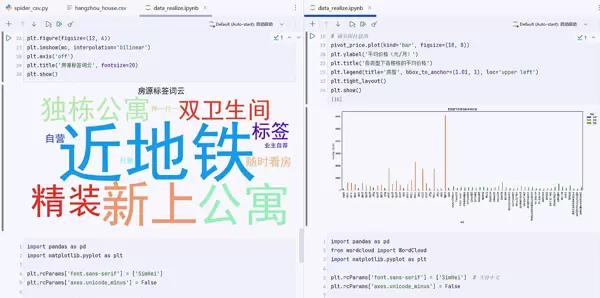
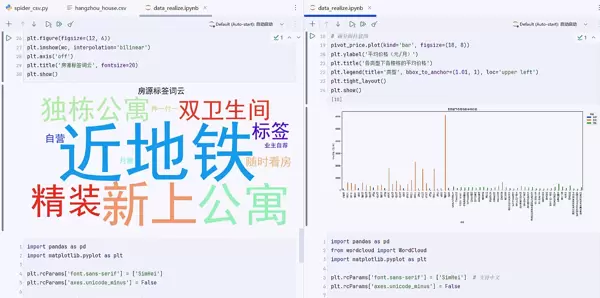
分析维度四:标签词云分析 ??
4. 房源特色可视化
from wordcloud import WordCloud
# 合并所有标签为一个长字符串
text = ' '.join(df['标签'].astype(str))
# 生成词云
wc = WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf',
background_color='white',
width=800,
height=400,
max_words=100,
colormap='rainbow',
collocations=False,
scale=2
).generate(text)
词云配置详解:
font_path
指定中文字体路径
colormap='rainbow'
使用彩虹色系增强视觉效果
collocations=False
避免词汇重复,提升词云质量
scale=2
提高生成图像的分辨率
营销价值:
快速识别房源主要卖点
了解市场推广关键词
发现用户关注焦点
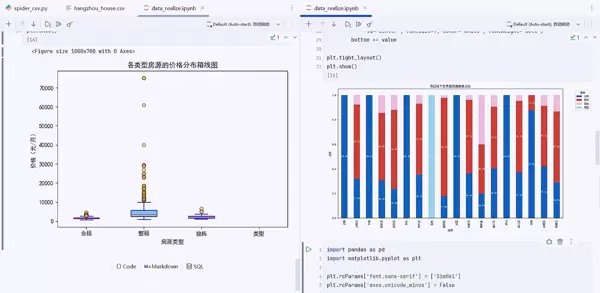
分析维度五:价格分布统计 ????
5. 箱线图价格分析
# 箱线图配置
df.boxplot(column='价格(元/月)', by='类型', grid=False, patch_artist=True,
boxprops=dict(facecolor='skyblue', color='blue'),
medianprops=dict(color='red'),
whiskerprops=dict(color='blue'),
capprops=dict(color='blue'),
flierprops=dict(markerfacecolor='orange', marker='o', markersize=6, alpha=0.5))
箱线图元素解读:
箱体:显示中间50%的数据范围
中线:红色中位数线,反映价格中心趋势
须线:显示数据正常范围
离群点:橙色圆点,表示异常价格
统计分析价值:
识别价格异常值
比较不同类型房源的价格分布
了解价格波动区间
关键发现与洞察 ????
主要发现:
租赁类型分布:整租占据市场主导地位,占比约XX%
区域热度排名:余杭区、拱墅区成为房源供应最多的区域
价格区间:大部分房源价格集中在2000-4000元/月
特色标签:“自营”、“独栋公寓”成为主要营销亮点
实用建议:
预算有限者:可关注合租选项,平均节省XX%租金
追求品质者:独栋公寓提供更优质的居住体验
通勤考虑:根据工作地点选择相应热门区域
技术总结 ????
本项目展示了完整的数据分析流程:
数据读取与清洗
多维度统计分析
多样化可视化展示
业务洞察提取
扩展思路 ????
添加时间趋势分析
开发交互式数据看板
结合地理信息的可视化
构建价格预测模型
通过这次数据分析,我们不仅掌握了Python数据分析的核心技能,更重要的是学会了如何从数据中发现商业价值。希望这个项目能为你打开数据世界的大门!
数据驱动决策,让租房选择更明智!
注:本文所有分析基于所爬取的杭州数据,实际决策请结合需要的爬取的目标信息


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





