在监督学习中,人类扮演着“教师”的角色,而机器则如同“学生”,通过接收带有明确答案的数据来学习规律。这种学习方式类似于课堂教学:老师提供标准答案,学生据此掌握知识。例如,将一张苹果的图片标注为“苹果”,把桔子的图片标注为“桔子”,机器便能从这些标注样本中学习如何识别不同水果。
总体而言,监督学习主要分为两大类:回归任务与分类任务。
1. 分类任务
分类任务的目标是判断输入样本属于哪一个预定义的类别。比如,识别图像中的动物是“猫”还是“狗”;判断语音片段发出的是“啊”还是“哦”;分辨手写数字是“1”还是“9”;或是判断一张表情包传达的情绪是“愤怒”还是“高兴”。执行此类任务的模型通常会输出一个类别标签作为预测结果,有时还会附带一个表示预测可信程度的数值——即“置信度”。
显然,这类任务的核心目标是提升分类的准确性。

2. 回归任务
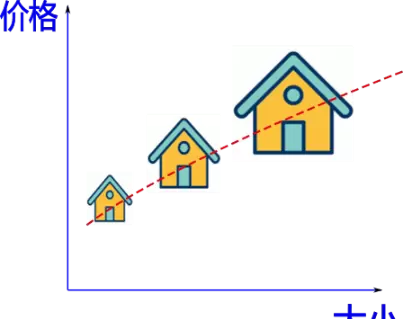
与分类任务不同,回归任务关注的是预测一个连续的数值结果。例如,给定一组房屋面积与对应价格的历史数据,机器可以学习面积和价格之间的关系,并据此预测新房屋的价格。另一个例子是天气预测:利用卫星云图、气温、湿度、气压以及地理位置等数据,模型可推断未来几天的温度或降雨量等连续变量。
关于数据标注的重要性
在监督学习过程中,高质量的数据标注是成功的关键。正如练习题中的标准答案帮助学生巩固知识点一样,正确的标签使机器能够从中归纳出有效的模式。不同的任务对标注的要求也各不相同:图像识别任务中,通常只需框选出物体并标明其类别,操作相对直接;而语音识别则需要逐字转录音频内容,过程更为复杂且耗时。
尽管数据标注是一项繁琐且劳动密集型的工作,但它构成了机器学习的基础,堪称训练模型不可或缺的“养料”。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





