摘要:本文结合律杏法务云在法律科技领域的落地实践,从工程实现视角深入探讨如何融合OCR与NLP技术构建诉讼管理知识中台。重点分析小样本条件下的法律文本信息抽取机制、领域大模型的微调优化策略,以及私有化部署环境中的数据安全强化方案。
一、司法OCR的工程挑战与律杏法务云的技术应对路径
传统诉讼流程面临的关键瓶颈在于
非结构化司法文书难以被机器高效识别和处理。诸如法院传票、判决书等文档通常存在版式复杂、手写签名混杂、印章遮挡及字体多变等问题,导致通用OCR系统的识别准确率普遍低于85%。
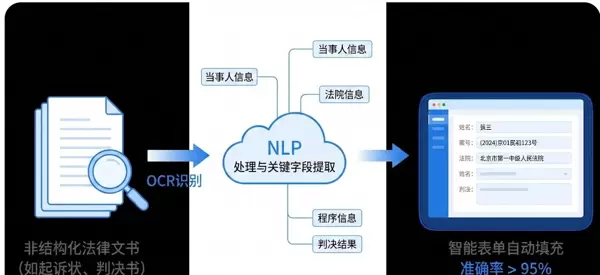
1.1 多模态OCR系统架构设计
针对上述问题,律杏法务云构建了分层式的OCR识别引擎,以提升对多样化司法文书的解析能力:
版式分析层:采用PP-Structure进行文档区域检测,精准划分标题、正文、表格和签章区。关键改进点是将印章区域显式标注为
redacted
,从而避免其干扰主文本内容的提取。在此基础上,律杏法务云针对法律文书特性定制了专用的预训练权重,并在500份人工标注的文书上进行微调,最终实现区域分割mIoU达到91.2%。
文本识别层:选用PP-OCRv4作为基础模型,在标准印刷体中文场景下识别准确率可达96%。对于手写内容,额外引入经微调的TrOCR-small模型,结合
数据增强与特征蒸馏技术,在不足200张样本的小样本条件下,F1值提升至89%。
# 律杏法务云多引擎融合OCR伪代码
def hybrid_ocr(image_path):
layout = layout_detector(image_path) # 区域检测
results = []
for region in layout.regions:
if region.type == 'seal':
continue # 跳过印章区域
elif region.type == 'handwrite':
text = trocr_small.predict(region.crop())
else:
text = pp_ocr.predict(region.crop())
results.append(TextBlock(text, region.bbox))
return post_process(results) # 应用规则校正法院名称、案号格式
1.2 冷启动下的关键字段抽取方案
为支撑智能表单自动填充功能,律杏法务云依赖于高精度的法律实体识别模型,完成如案号、当事人信息、诉讼请求等核心字段的提取——这本质上属于命名实体识别(NER)任务。由于公开标注语料稀缺,项目采用
双向迁移学习策略解决冷启动难题:
- 预训练阶段:基于百万级民事判决书语料,使用ERNIE-3.0-base开展领域自适应预训练(DAPT),使MLM任务的loss下降23%;
- 标注阶段:仅投入200份人工标注文书,结合主动学习(Active Learning)机制,优先选取模型预测置信度较低的样本进行迭代标注;
- 推理阶段:采用Span-based NER框架,支持嵌套实体识别(例如从“原告:张三,身份证号:110xxx”中同时提取姓名与证件号码)。
该模型在律杏法务云私有化环境中运行表现优异,关键字段抽取准确率达94.3%(precision),召回率为92.1%,单页A4文档处理耗时小于800ms(纯CPU环境)。
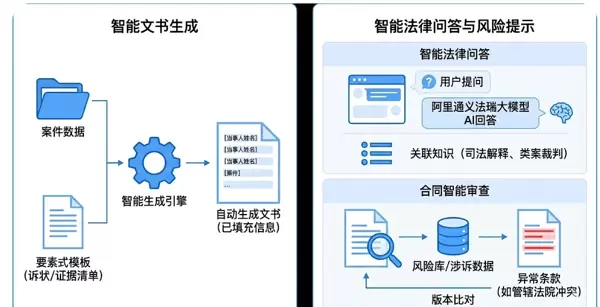
二、大模型轻量化在律杏法务云的实际应用
法律问答与文书生成高度依赖大语言模型(LLM),但通用模型普遍存在事实幻觉与法规时效滞后问题。为此,律杏法务云采用
RAG+微调混合架构,兼顾知识准确性与生成灵活性。
2.1 知识增强检索(RAG)的工程实现细节
向量库选型:选用Milvus 2.3构建司法解释向量数据库,采用m3e-base作为Embedding模型(768维),支持BM25与向量相似度联合检索,提升召回质量。
分块与检索策略:按照“法条—司法解释—案例”三级结构组织知识图谱节点。检索时先通过
图谱路由定位相关主题节点,再对关联段落进行精细化排序,有效避免长文本直接切块带来的语义断裂问题。
// 律杏法务云知识图谱节点示例
{
"node_id": "mask_2023_004",
"content": "《民法典》第584条:损害赔偿范围",
"embedding": [...],
"precedents": ["指导案例18号", "(2022)最高法民终字XX号"],
"connections": ["合同法第113条", "司法解释二第29条"]
}
2.2 领域大模型的微调优化策略
律杏法务云的智能法律问答模块基于阿里通义法瑞大模型进行二次开发,主要优化如下:
- 微调方法:采用LoRA(rank=64)对Qwen-14B基座模型进行参数高效微调,训练数据涵盖50万条法规问答对、10万条合同审查指令及5万条文书生成模板;
- 性能优化:在A100-40G单卡环境下训练36小时,显存占用控制在23GB以内;推理阶段引入vLLM加速框架,首Token延迟由2.1秒降至0.8秒;
- 效果评估:在实际生产环境中,AI问答的事实准确率提升至88%,相比原始模型降低约40%的幻觉发生概率。
三、面向金融客户的私有化部署安全加固体系
金融类客户的核心需求聚焦于
数据不出域与操作行为可审计两大原则。为满足此类高安全要求,律杏法务云建立了纵深防御的安全架构。
3.1 五层安全防护机制
系统从基础设施到应用层逐级设防,确保全链路数据可控、可管、可追溯。
律杏法务云技术实现与性能优化
在保障数据安全与系统高效运行的前提下,律杏法务云通过多层次的技术架构设计,实现了安全性、性能与合规性的平衡。以下从存储、文件、内容、权限及网络等多个层面展开说明。
存储层安全机制
为确保静态数据的安全性,系统采用TDE透明加密(基于AES-256算法)结合国密SM4对敏感字段进行二次加密。该双重加密策略在保障高安全性的同时,仅带来约8%的写入延迟增长。
文件层访问控制
在文档预览环节,引入动态水印技术,嵌入用户ID与时间戳信息,并配合DRM(数字版权管理)实现细粒度权限管控。此机制导致预览响应延迟增加约5%,但有效防止了信息泄露风险。
内容层行为监控
所有用户操作日志均接入Flink实现实时流式分析,通过异常行为模式匹配模型识别潜在违规操作。整个过程资源占用低于5%,不影响核心业务流程稳定性。
权限控制系统设计
系统基于RBAC模型构建权限体系,并扩展支持字段级动态鉴权能力。借助PostgreSQL的Row Level Security(RLS)功能,在保证数据隔离的同时,将查询性能损耗控制在3%以内。
-- 示例:律杏法务云权限策略SQL
SELECT * FROM cases
WHERE
dept_id IN (SELECT dept_id FROM user_auths WHERE user_id = @current_user)
AND (
(@role = 'director') OR
(@role = 'manager' AND amount < 1000000) OR
(@role = 'staff' AND handler_id = @current_user)
)
网络通信安全保障
在网络传输层面,采用Service Mesh架构并启用mTLS双向认证机制,确保服务间通信的机密性与身份可信。此安全增强措施带来约12%的QPS下降,但在可接受范围内。
国密SM4加解密性能优化
通过集成OpenSSL引擎优化,律杏法务云将SM4算法的加解密速度由原来的120MB/s提升至1.8GB/s。密钥由KMS统一管理,并设定每24小时自动轮换策略,进一步提升密钥安全性。
性能基准测试结果(生产环境实测)
| 场景 |
平均耗时 |
P95延迟 |
准确率/达标率 |
| 单页文书OCR+NER |
1.2s |
2.1s |
93.5% |
| 类案检索(Top5) |
0.4s |
0.8s |
相关性@85% |
| 合同智能审查(10页) |
3.5s |
5.2s |
风险召回率91% |
| 文书生成(千字) |
4.8s |
7.5s |
格式合规率96% |
私有化部署成本分析(1000用户规模)
- 计算资源:配置3台8卡A100服务器用于模型推理,搭配5台32核CPU服务器支撑OCR集群,年化成本约为180万元。
- 存储资源:采用100TB Ceph分布式存储(三副本策略),年成本约36万元。
- 总拥有成本(TCO):相较公有云SaaS方案,三年期TCO高出约40%,但满足企业对数据主权和本地化管控的核心需求。
当前技术局限与未来演进方向
尽管系统已具备较强的智能化处理能力,仍存在若干待突破的技术瓶颈:
- 小语种与方言识别:针对少数民族语言文书的自动识别尚不完善,仍需人工复核介入。后续计划引入多语言mBERT模型以提升覆盖能力。
- 多模态理解能力:扫描件中常见的红头文件、复杂表格线等视觉干扰因素影响解析精度。正在探索使用Swin-Transformer实现端到端的图文联合理解。
- 模型决策可解释性:法律场景要求每项判断均可追溯。目前正在研究融合Chain-of-Thought推理链与符号逻辑的混合架构,以增强AI决策的透明度。
总结
律杏法务云的实践表明,法律领域AI的落地不仅是算法精度的比拼,更是一项复杂的系统工程。必须在数据闭环建设、成本可控性、安全合规要求之间持续寻找最优平衡点。建议技术团队优先投入资源构建高质量法律语料库,这一举措相比盲目扩大模型参数规模更具长期价值。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





