使用熊猫读写CSV文件的基本介绍
如果使用数据,Pandas数据框将使生活变得更加轻松。许多数据以CSV格式出现。可以将CSV文件读取到Pandas数据框。实际上,使用read_csv非常容易 。在下面的视频中,我们将学习仅将CSV文件加载到Pandas数据框对象的基础知识。
还有更多使用Pandas read_csv()的方法。以下是本文最初发布到此处的方法。
在第一部分中,我们将通过示例介绍如何读取CSV文件,如何从CSV读取特定列,如何读取多个CSV文件并将它们组合为一个数据帧,以及最后如何转换数据。根据特定的数据类型(例如,使用Pandas read_csv dtypes)。
在上一节中,我们将继续学习如何使用熊猫编写CSV文件。也就是说,我们将学习如何将数据框导出到CSV文件。
目录
熊猫从硬盘导入CSV
如何在Python熊猫中读取CSV文件
如何使用Python将CSV文件导入Pandas?
熊猫从URL读取CSV
熊猫读取CSV usecols
熊猫读取CSV:删除未命名列
如何从Pandas数据框中删除列
熊猫读取CSV和缺少值
读取CSV和跳过行
熊猫read_csv跳过示例:
如何使用熊猫读取某些行
熊猫read_csv dtype
将多个文件加载到数据框
如何在熊猫中写入CSV文件
如何将熊猫保存为CSV
如何将多个数据框写入一个CSV文件
结论
熊猫从硬盘导入CSV
在此熊猫阅读CSV教程的第一个示例中,我们将仅使用read_csv将CSV加载到与脚本位于同一目录中的数据框。如果文件在另一个目录中,则必须记住将完整路径添加到文件中。
自然地,熊猫可用于从多种不同文件类型导入数据。例如,可以将Excel(xlsx)和JSON文件读入Pandas数据框。了解有关在Pandas中导入数据的更多信息:
Pandas Excel教程:如何读取和写入Excel文件
熊猫读写JSON教程
如何在Python熊猫中读取CSV文件
在本节中,我们将学习如何从硬盘驱动器读取CSV文件。但是,首先,我们将回答以下问题:如何在熊猫中打开CSV文件?
如何使用Python将CSV文件导入Pandas?
这是学习如何在Pandas中读取CSV文件的两个简单步骤:
1.导入Pandas包:
import pandas as pd
2.使用pd.read_csv()方法:
df = pd.read_csv('yourCSVfile.csv')
注意,read_csv方法的第一个参数应为CSV的文件路径。文件。
在本熊猫阅读CSV教程中,我们将学习如何在Python和Pandas中使用逗号分隔(CSV)文件。我们将概述如何使用Pandas将CSV加载到数据帧以及如何将数据帧写入CSV。
df = pd.read_csv('amis.csv') df.head()
如果我们对读取文件感兴趣,通常可以使用Python使用open()方法。这样,我们可以在Python中读取许多文件格式(例如.txt)。
熊猫阅读CSV示例

300w“ size =”(最大宽度:446px)100vw,446px “ />
数据框
可以在此处下载数据,但在以下示例中,我们将使用Pandas read_csv从URL加载数据。
熊猫从URL读取CSV
我们可以使用熊猫从URL导入CSV文件吗?是的,在本节中,我们将学习如何使用Pandas在Python中读取CSV文件,就像前面的示例一样。但是,在下一个read_csv示例中,我们这次将从URL读取相同的数据集。非常简单,我们只需将URL作为read_csv方法中的第一个参数即可。这是三个简单的步骤,可以帮助我们从URL读取CSV:
再次,我们需要进口熊猫
用URL创建一个字符串变量
现在,将Pandas read_csv与URL一起使用(请参见下面的示例)
在下面的示例代码中,我们遵循三个简单的步骤将CSV文件导入到Pandas数据框中:
url_csv = 'https://vincentarelbundock.github.io/Rdatasets/csv/boot/amis.csv' df = pd.read_csv(url_csv) df.head()
https://www.marsja.se/wp-content/uploads/2018/11/how_to_read_csv_file_pandas-300x173.png 300w“ size =”(最大宽度:335px)100vw,335px“ />
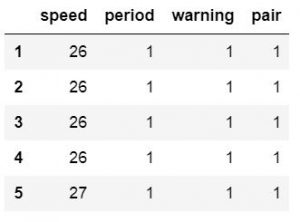
在上图中,我们看到有一个名为“未命名:0”的列。此外,我们可以看到它包含数字。因此,当使用Pandas read_csv方法时,我们可以将此列用作索引列。在下一个代码示例中,我们正在这样做。我们将使用Pandas read_csv和index_col参数。
此参数可以采用整数或序列。在我们的例子中,我们将使用整数0,我们将获得更好的数据帧:
df = pd.read_csv(url_csv
使用index_cols的熊猫read_csv
300w,https://www.marsja.se/wp-content/uploads/2018 / 11 / pandas-read-csv-ex ... 203w“ size =”(最大宽度:331px)100vw,331px“ />
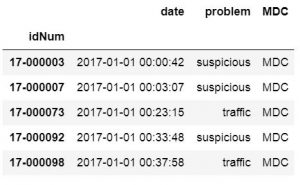
index_col参数也可以将字符串作为输入,我们现在将使用其他数据文件。在下一个示例中,我们将CSV读取到Pandas数据框中,并使用idNum列作为索引。
csv_url = 'http://vincentarelbundock.github.io/Rdatasets/csv/carData/MplsStops.csv' df = pd.read_csv(csv_url
https://www.marsja.se/wp-content/uploads/2018/11/pandas-read-csv-index-cols-multiindex-300x102.jpg 300w,https://www.marsja.se/wp-content / uploads / 2018/11 / pandas-read-csv-in ... 640w,https://www.marsja.se/wp-content/uploads/2018/11/pandas-read-csv-in ... 879w “ size =”(最大宽度:768px)100vw,768px“ />
注意,要获得以上输出,我们使用了Pandas iloc选择前7行。这样做是为了获得可以更容易说明的输出。就是说,我们现在继续下一节,我们将从CSV文件中读取某些列到数据框。
熊猫读取CSV usecols
在某些情况下,我们不想解析CSV文件中的每一列。为了只读取某些列,我们可以使用参数usecols。请注意,如果我们希望第一列为索引列,并且要解析前三个列,则需要一个包含4个元素的列表(在此处比较我的read_excel usecols示例):
cols = [0
read_csv usecols
当然,如果我们有一个包含更多列的CSV文件,那么使用read_csv usecols更有意义。我们也可以将Pandas read_csv usecols与字符串列表一起使用。在下一个示例中,我们返回之前使用的较大文件:
csv_url = 'http://vincentarelbundock.github.io/Rdatasets/csv/carData/MplsStops.csv' df = pd.read_csv(csv_url
usecols示例
300w“ Size =”(max-width:466px)100vw,466px “ />
usecols与字符串列表
熊猫读取CSV:删除未命名列
在之前的read_csv示例中,我们获得了一个未命名的列。在本熊猫阅读CSV教程的前几部分中,我们已通过将此列设置为索引或使用usecols从CSV文件中选择特定列的方式来解决此问题。但是,由于某些原因,我们可能不想这样做。这是一个如何使用Pandas read_csv摆脱“ Unnamed:0”列的示例:
csv_url = 'http://vincentarelbundock.github.io/Rdatasets/csv/carData/MplsStops.csv' cols = pd.read_csv(csv_url
https://www.marsja.se/wp-content/uploads/2018/11/pandas-read-csv-tutorial-300x96.jpg 300w,https://www.marsja.se/wp-content/uploads/2018 / 11 / pandas-read-csv-tu ... 640w,https://www.marsja.se/wp-content/uploads/2018/11/pandas-read-csv-tu ... 774w“ size =” (最大宽度:768px)100vw,768px“ />
如何从Pandas数据框中删除列
当然,也可以在将CSV加载到数据框后删除未命名的列。要删除未命名的列,我们可以使用两种不同的方法。定位以及其他Pandas数据框方法。当使用drop方法时,我们可以使用inplace参数并获取没有未命名列的数据框。
df.drop(df.columns[df.columns.str.contains('unnamed'
https://www.marsja.se/wp-content/uploads/2018/11/removing-many-unnamed-columns-from-pandas-dataframe-300x79.jpg 300w,https ://www.marsja.se/wp -content / uploads / 2018/11 / removing-many-unna ... 640w,https://www.marsja.se/wp-content/uploads/2018/11/removing-many-unna ... 909w“尺寸=“(最大宽度:768px)100vw,768px” />
解释上面的代码示例;我们选择不包含字符串“ unnamed”的列。此外,我们使用了case参数,以便contains方法不区分大小写。因此,我们将获得名为“未命名”和“未命名”的列。在第一行中,使用Pandas drop,我们还使用了inplace参数,以便它更改数据框。的轴参数,但是,用于删除的,而不是索引(即,行)的列。
学习一些使用Python和Pandas的数据处理技术。
熊猫读取CSV和缺少值
在本节中,我们将学习如何处理Pandas数据框中的缺失值。如果我们的CSV文件中缺少数据,并且编码方式使得熊猫无法找到它们,则可以使用参数na_values。在下面的示例中,amis.csv文件已更改,并且有些单元格的字符串为“ Not Available”。
https://www.marsja.se/wp-content/uploads/2018/11/missing-data-pandas-dataframe-768x529.jpg 768w,https ://www.marsja.se/wp-content/uploads/2018 / 11 / missing-data-panda ... 640w,https://www.marsja.se/wp-content/uploads/2018/11/missing-data-panda ... 782w“ size =”(最大宽度:300px)100vw,300px“ />
CSV文件
也就是说,我们将把“不可用”更改为以后在进行
数据分析时可以轻松删除的内容。
df = pd.read_csv('Simdata/MissingData.csv'
https://www.marsja.se/wp-content/uploads/2018/11/read-csv-pandas-missing-values-300x164.jpg 300w“ size =”(最大宽度:453px)100vw,453px“ / >
读取CSV和跳过行
如果我们的数据文件包含前x行的信息并且使用熊猫read_csv时需要跳过行怎么办?例如,我们如何跳过文件中的前三行,如下所示:
https://www.marsja.se/wp-content/uploads/2018/11/read-csv-pandas-skip-rows-300x168.jpg 300w,https://www.marsja.se/wp-content/uploads / 2018/11 / read-csv-pandas-sk ... 640w,https://www.marsja.se/wp-content/uploads/2018/11/read-csv-pandas-sk ... 888w“尺寸=“(最大宽度:768px)100vw,768px” />
现在,我们将学习如何使用熊猫read_csv并跳过x的行数。幸运的是,仅使用skiprows参数非常简单。在下面的示例中,我们使用read_csv和skiprows = 3跳过前3行。
熊猫read_csv跳过示例:
我们如何使用Pandas skiprow参数?这是一个熊猫的read_csv示例,我们跳过了前三行:
df = pd.read_csv('Simdata/skiprow.csv'
https://www.marsja.se/wp-content/uploads/2018/11/skip-rows-pandas-csv-tutorial-300x145.jpg 300w“ size =”(最大宽度:532px)100vw,532px“ / >
注意,我们可以使用header参数获得与上述相同的结果(即data = pd.read_csv('Simdata / skiprow.csv',header = 3))。
如何使用熊猫读取某些行
我们可以使用Pandas的read_csv方法从CSV文件中读取特定的行吗?如果我们不想读取CSV文件中的每一行,则可以使用参数nrows。在下一个示例中,下面我们读取了CSV文件的前8行。
df = pd.read_csv(url_csv
如果我们想选择随机行,我们可以加载完整的CSV文件并使用Pandas示例随机选择行(请阅读Pandas Sample教程以了解更多信息)。
熊猫read_csv dtype
我们还可以设置列的数据类型。尽管在amis数据集中所有列都包含整数,但我们可以将其中一些设置为字符串数据类型。这正是我们在下一个Pandas read_csv pandas示例中将要执行的操作。我们将使用熊猫read_csv D型参数,并把在词典:
url_csv = 'https://vincentarelbundock.github.io/Rdatasets/csv/boot/amis.csv' df = pd.read_csv(url_csv
https://www.marsja.se/wp-content/uploads/2018/11/pandas-read-csv-dtype-string-300x178.jpg 300w“ size =”(最大宽度:448px)100vw,448px“ / >
当然,可以强制使用其他数据类型,例如整数和浮点数。例如,我们要做的就是将str更改为float(当然,假设该列中有十进制数字)。
题库



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




