本文介绍数据分析中最最最基础和常用的概念,分为四个部分:显著性指标、量表、数据类型、样本。
常见概念
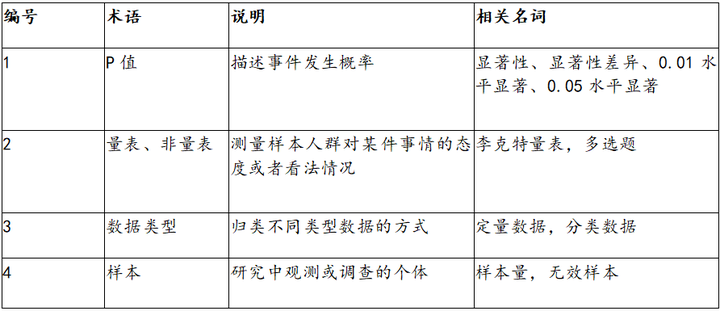
- P值
P值也称显著性值,或者Sig值,用于描述某件事件发生的概率情况,其取值范围介于0到1之间,不包括0或者1。通常情况下P值有三个标准,分别是0.01,0.05和0.1。如果P值小于0.01即说明某件事情的发生至少有99%的把握,如果P值小于0.05(并且大于0.01)则说明某件事情的发生至少有95%的把握。针对大部分分析,都需要通过显著性检验,说明分析具有统计学意义。
2. 量表
通常是指李克特量表,其用于测量被试对于某构念(通俗讲即某件事情)的态度或者看法情况。通常量表会由很多项目(题项)构成,并且答项类似于”非常同意”、”同意”、”不一定”、”不同意”、”非常不同意”,也或者“非常满意”、“比较满意”、“中立”、“比较不满意”,“非常不满意“等。
量表被广泛使用于学术研究的各个领域,并且大多数统计方法均只能针对量表。量表的尺度形式有多种,常见是五级量表,即五个答项,另外还会有七级量表,九级量表或者四级量表等,四级量表或者九级量表使用频率相对较少。
非量表,即除量表(或者类似量表)的题项,比如多选题,或者基本事实现状题项等,非量表题项更多用于了解基本事实现状,研究人员可以通过此类题项分析研究当前现状情况。
3.数据类型
针对数据类型,当前分类标准并不统一,本书将数据分为两类,分别是定量数据和分类数据。
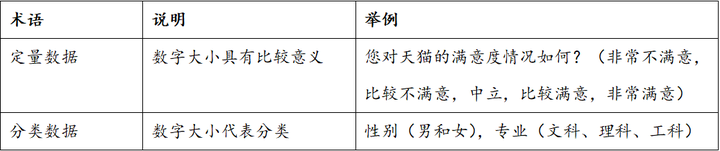
定量数据和分类数据区别在于数字大小是否具有比较意义,比如研究满意度(1=非常不满意,2=比较不满意,3=中立,4=比较满意,5=非常满意),可以看到每项的数值是具有比较意义的,数值越高,代表样本的满意度越高。
而定类数据数值大小仅作为区分类别,每项数值之间不存在有比较的关系,例如1=男性,2=女性,不能说“数值越大越女性”。
4. 样本
通俗地讲即为填写问卷的人,针对样本数量要求,统计上并没有统一标准,通常情况下为量表题项的5倍或者10倍即可。有时研究人员需要的样本比较特殊,比如需要样本具有企业高管背景,因而此时样本量要求会较少。从经验上看,作为硕士研究生,多数情况下样本需要大于200,如果作为本科生,样本量需要高于100。
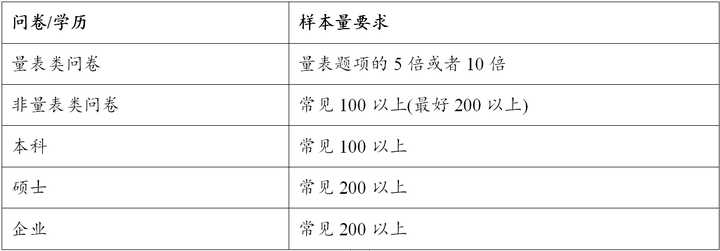
如果样本中有大篇幅题项没有填写,或者多数题项均填写同样一个答案,也或者样本本身并不具有研究的背景性质(比如研究对象为90后,但部分样本为80后,则80后为无效样本),也或者研究者认为某部分样本的填写存在逻辑问题等,上述几种情况下的样本均称作无效样本,分析之前需要将无效样本进行删除或者筛选处理,以上两种剔除样本的方法在SPSSAU中均可实现。
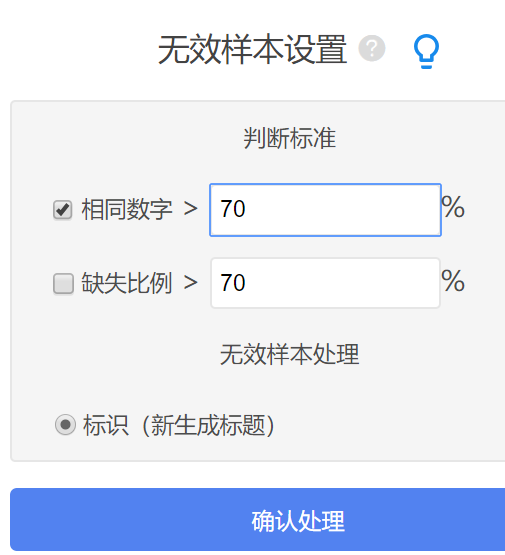
spssau筛选样本


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏






