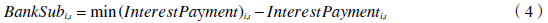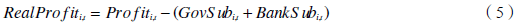在Stata中识别2006-2023年僵尸企业的过程主要基于上述提到的方法,涉及信贷补贴、ZF补贴(政府补贴)和企业盈利能力等因素。下面是具体步骤:
### 1. 定义变量
首先定义你需要的几个关键变量:
- 利润前税收与利息 (EBIT)
- 政府补贴
- 短期贷款平均利率
- 贷款总额或负债
假设这些数据已经存在于你的Stata数据集中的变量名分别为:`ebit`, `govt_subsidy`, `short_rate`, 和 `debt_total`.
### 2. 计算信贷补贴
计算每年的信贷补贴,公式为:
\[ \text{Credit Subsidy} = \min(\text{Debt} * \text{Short Rate}, \text{EBIT}) \]
使用Stata命令进行操作:
```stata
gen credit_subsidy = min(debt_total * short_rate, ebit)
```
### 3. 计算调整后利润
接下来,计算扣除信贷补贴和ZF补贴后的实际利润:
\[ \text{Adjusted Profit} = \text{EBIT} - \text{Credit Subsidy} - \text{Govt Subsidy} \]
Stata命令如下:
```stata
gen adjusted_profit = ebit - credit_subsidy - govt_subsidy
```
### 4. 僵尸企业识别
最后,根据连续若干年(如T=2或3)调整后利润为负的条件来识别僵尸企业:
\[ \sum_{t}^{t+2} \text{Adjusted Profit}_t < 0 \]
使用`egen`命令进行计算:
```stata
by firm_id: egen total_adjusted_profit = sum(adjusted_profit), by(year)
gen zombie = (total_adjusted_profit < 0) if year > 2006 & year <= 2023
```
这里假设你的数据集已经根据`firm_id`(企业ID)和`year`排序。在最后一行代码中,`zombie`变量将被赋值为1如果企业在连续三年内调整后的利润总和小于零,则该企业被认为是僵尸企业;否则赋值为0。
### 5. 数据清洗与检查
确保所有计算的步骤没有错误,并且数据集中的缺失值已经被适当地处理。可以使用`tab zombie, m`或`summarize adjusted_profit`等命令来验证结果和统计数据的一致性。
以上步骤在Stata中实现了僵尸企业的识别,基于Caballero、Imai 和黄少卿等人提出的方法。这将帮助你更全面地理解企业行为以及经济政策的影响。
此文本由CAIE学术大模型生成,添加下方二维码,优先体验功能试用


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏