一、检测缺失值情况(示例数据集:nhanes2,详细说明请看附录)
1 summary(数据集)
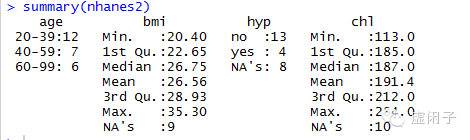
可以看到bmi、hyp、chl分别有9、8、10 个缺失值
2 统计数据集中缺失值数量
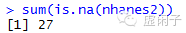
可以看到nhanes2数据集中有27个缺失值
3 统计数据集中完整记录条数

可以看到nhanes2数据集中有13条完整记录
4 观察数据集中缺失值是否随机(可以利用mice包中md.pattern函数来完成)
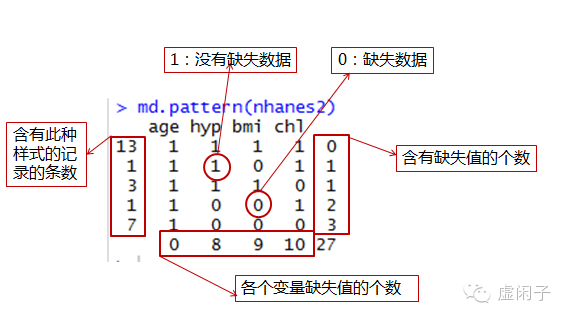
如:第一行第一列的13代表有13个样本是完整的
二、缺失值处理
1 删除法
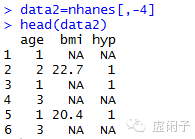
1.1 直接删除含有NA值的记录(na.omit命令)

可以看到凡是含有缺失值的记录已经被删除,只保留13条完整记录
1.2 若某些变量缺失严重且对分析影响不大,可以删除整个变量
chl有10个缺失值,如果chl对分析影响不大,那就可以考虑删除。
2 插补法
2.1 最简插补法(从总体中随机抽取某个样本值代表缺失值)
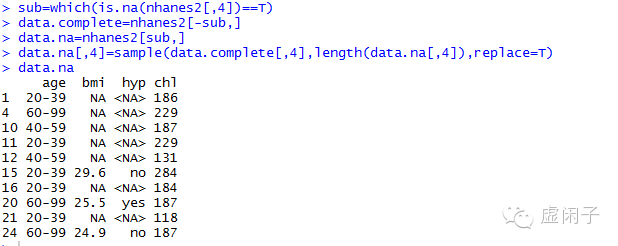
PS:此法很容易出问题,尤其是碰到各个变量相关时,一般不建议使用。
2.2 均值法
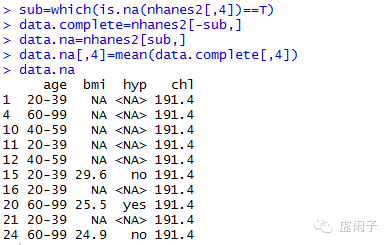
PS:没用到相关变量信息,会存在一定的偏差,慎用
2.3 回归插补(将需要插补变量作为因变量,其他相关变量作为自变量,建立回归模型预测出因变量对缺失变量进行插补)
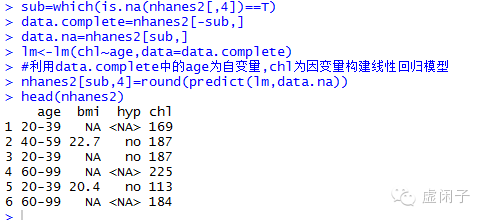
PS:用相关变量来进行预测,是比较理想处理缺失值的方法,但怎样构建回归模型需要具体情况具体分析。
附录:
nhanes2数据集:

age: 年龄段
bmi:身体质量指数,单位为kg/㎡
hyp:是否患高血夺
chl:血清胆固醇问题,单位为mg/dL


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





