meta新手,悬赏求助关系到学位,诚心求教大家帮忙!
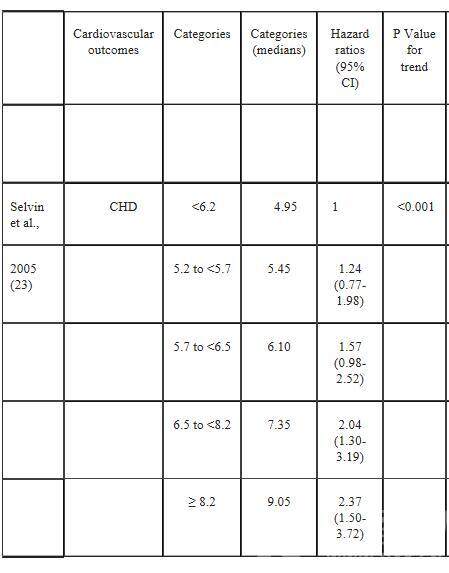
在准备一个meta-analysis,希望纳入的文章是cohort study。查询文章后,有些是用连续变量得到的HR,有些是二分类变量得到的HR,有些是分类变量(tertile,quantile...)代入的HR。想用STATA做分析。找到一篇已经被接收了,但是还没有发表的类似的文章。解决办法似乎是把分类变量(tertile,quantile...)的HR怎么换算成连续变量的HR,然后再在STATA里分析。比如,该篇文章中纳入的其中一篇文章:“Glycemic Control and Coronary Heart Disease Risk
in Persons With and Without Diabetes” 其中数据如下:但是最后带入分析的是:1.14 (1.07-1.21). 请问怎么求得这个1.14 (1.07-1.21)的呢?原文在附件中。并没有提供每个组的发病人数是多少!
0
文中method部分描述得非常概约,如下:
Most of the studies included in the present analysis reported the
RRs of per unit change of GHb level, therefore, we converted studies that used different units in their original analyses based on the method previously published [15]. For example, there were 3 studies [28-30] that compared the RR for participants in the 3rd tertile of GHb to participants in the 2 lowest tertiles. In order to make these results comparable to the rest of studies, we assumed that there was a normal distribution for GHb values and used the reported mean and standard deviation (SD) to estimate the 33rd and 83rd percentiles of GHb (corresponding to the midpoints of the 2 lowest and the highest tertiles, respectively). Then, we divided the log RRs by the difference of these 2 values to estimate the effect of a 1% change in HbA1 [31]. Similarly, for one study [32] that compared the reported RR of above and below the median value of GHb, we estimated the effect of a 1% change but calculated the 25th and 75th percentiles instead. " 提到的处理方法里还不包括这个文章。我看了引用的两篇处理方法的文章也没有得到什么有用的信息。其中一篇也许有用,我放在附件里了,其中的“estimation from reports employing only broad exposure categoreis”似乎沾到点边,但是又没说清楚。
总之万分着急,希望得到大家的赐教!



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





