学习视频:https://www.bilibili.com/video/BV1owrpYKEtP?t=1.3&p=94
一、决策树回归的基本概念
决策树是一种非参数监督学习模型,既适用于分类任务(如决策树分类),也适用于回归任务(如决策树回归)。
在回归任务中,决策树的目标是通过对特征的逐层划分,将数据集分割成多个子集,每个子集最终生成一个预测值(通常是该子集中样本标签的平均值)。
与分类树不同,回归树的分裂标准不是“纯度”(如信息熵、基尼系数),而是“方差”——我们希望分裂后的子集中样本的方差尽可能小,以提高预测的稳定性。
二、决策树回归的最终预测结构
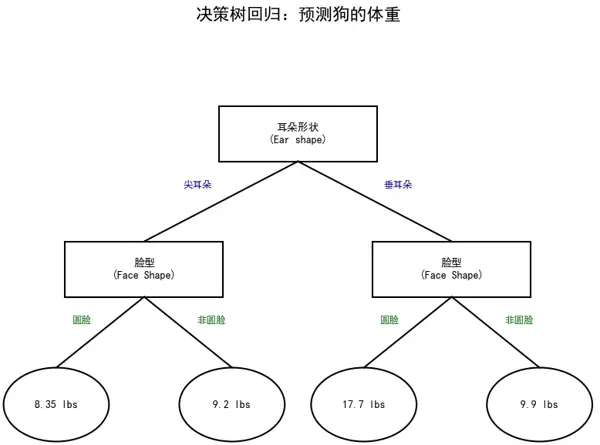
上图展示了一棵用于** 预测 “狗的体重(lbs.)”** 的回归决策树,其分裂逻辑和预测过程如下:
- 根节点分裂:Ear shape(耳朵形状)
- 二级节点分裂:Face Shape(脸型)
- 对于
Pointy
分支,继续按 Face Shape
分裂为 Round(圆脸)
和 Not Round(非圆脸)
- 对于
Floppy
分枝,同样按 Face Shape
分裂为 Round
和 Not Round
- 叶节点的预测值(均值)
Ear shape=Pointy + Face Shape=Round
:样本体重为 7.2, 8.4, 7.6, 10.2
,平均值为 (7.2+8.4+7.6+10.2)/4=8.35Ear shape=Pointy + Face Shape=Not Round
:样本体重为 9.2
,平均值为 9.2Ear shape=Floppy + Face Shape=Round
:样本体重为 15, 18, 20
,平均值为 (15+18+20)/3=17.7Ear shape=Floppy + Face Shape=Not Round
:样本体重为 8.8, 11
,平均值为 (8.8+11)/2=9.9
三、分裂节点的选择(方差减少法)
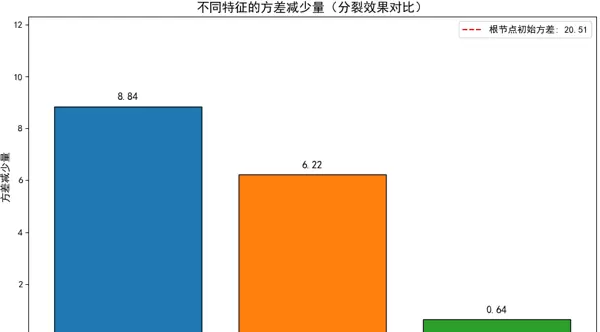
决策树的核心问题是“如何选择最佳的分裂特征和分裂点”。通过“方差减少量”来量化不同特征的分裂效果,步骤如下:
- 根节点的初始方差(Variance at root node: 20.51)
- 首先计算所有样本体重的方差,作为根节点的初始方差。
- 假设所有样本的体重为:
7.2, 9.2, 8.4, 7.6, 10.2, 8.8, 15, 11, 18, 20
(共 10 个样本),平均值 μ=(7.2+9.2+8.4+7.6+10.2+8.8+15+11+18+20)/10=11.64,方差为 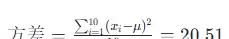
- 候选特征 1:Ear shape(耳朵形状)
- 分裂为
Pointy
和 Floppy
两个子集:
Pointy
子集:5 个样本,体重 7.2, 9.2, 8.4, 7.6, 10.2
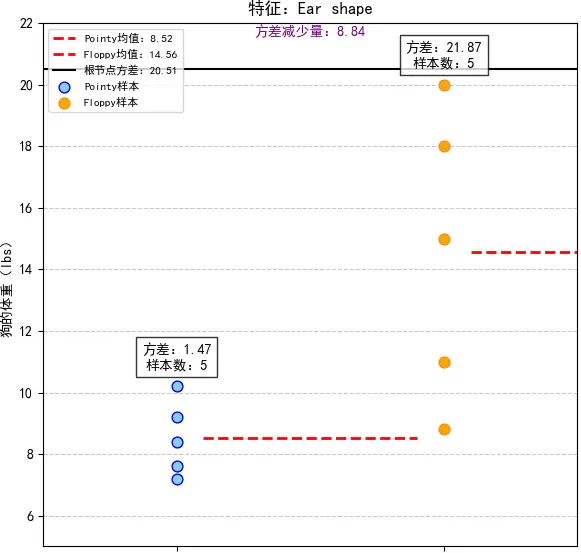
,平均值 μ1=8.52,方差为 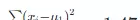
Floppy
子集:5 个样本,体重 8.8, 15, 11, 18, 20
,平均值 μ2=14.56,方差为 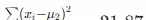
- 方差减少量的计算公式为:
- 方差减少量 = 根节点方差 - (wleft × 左子集方差 + wright × 右子集方差)
- 其中,wleft 和 wright 分别是左右子集的样本比例(此处均为 5/10)。代入得:20.51 - (5/10 × 1.47 + 5/10 × 21.87) = 8.84
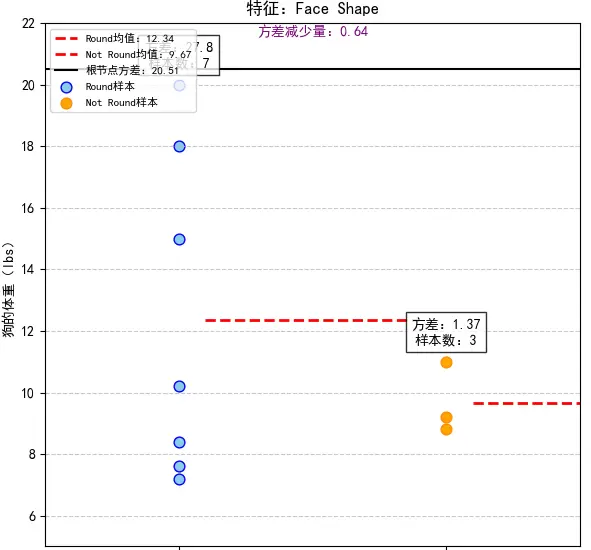
- 候选特征 2:Face Shape(脸型)
- 分裂为
Round
和 Not Round
两个子集:
Round
子集:7 个样本,体重 7.2, 15, 8.4, 7.6, 10.2, 18, 20
,平均值 μ1 ≈ 12.34,方差为 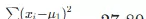
Not Round
子集:3 个样本,体重 9.2, 8.8, 11
,平均值 μ2 ≈ 9.67,方差为 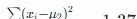
- 样本比例 wleft = 7/10,wright = 3/10,代入方差减少量公式:20.51 - (7/10 × 27.80 + 3/10 × 1.37) = 0.64
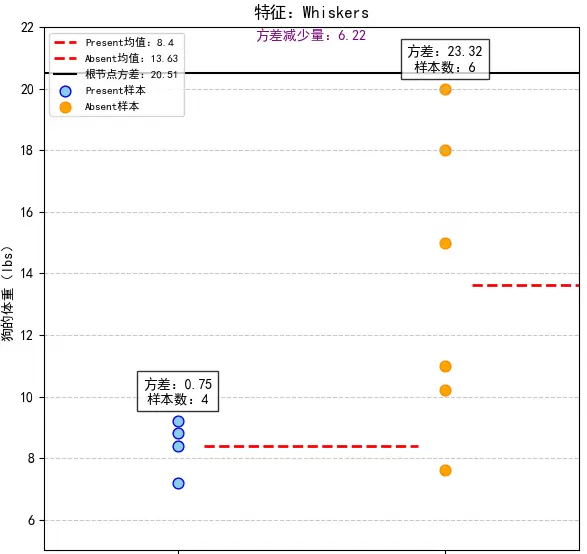
- 候选特征 3:Whiskers(胡须)
- 分裂为
Present
和 Absent
两个子集:
Present
子集:4 个样本,体重 7.2, 8.8, 9.2, 8.4
,平均值 μ1 = 8.4,方差为 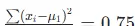
Absent
子集:6 个样本,体重 15, 7.6, 11, 10.2, 18, 20
,平均值 μ2 ≈ 13.63,方差为 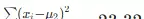
- 样本比例 wleft = 4/10,wright = 6/10,代入方差减少量公式:20.51 - (4/10 × 0.75 + 6/10 × 23.32) = 6.22
- 选择最佳分裂特征
四、决策树回归的扩展知识
过拟合与剪枝
决策树容易出现过拟合问题(尤其是深度较大的树),因为它们会“记住”训练数据的细节。常见的解决方法是通过剪枝来减少过拟合,分为:
预剪枝:在分裂过程中提前停止(如限制树的最大深度、叶节点最少样本数);
后剪枝:先构建一棵完整的树,再从叶节点向上剪去 “对泛化能力提升不大” 的分支。
集成学习:随机森林、梯度提升树
决策树的单个模型稳定性较差,因此常通过“集成”方法来提高性能。
随机森林:多棵决策树 “投票 / 平均” 输出结果,通过 “随机选择特征 + 随机选择样本” 降低过拟合;
梯度提升树(GBDT、XGBoost、LightGBM):多棵树
依次修正前一棵树的误差
,以迭代的方式提高精度。
特征重要性
在决策树(尤其是集成树)中,可以通过 “特征被分裂的次数、方差减少的总量” 量化
特征重要性
,以此筛选对预测结果影响较大的特征。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏