经管之家App
让优质教育人人可得
立即打开


AI的终极挑战: 突破大模型Token限制的完整技术方案
设想这样一个情景:某市中级人民法院的法官助理小张,正在处理一起复杂的经济纠纷案。案件材料堆积如山——合同文本387页、往来邮件2000多封、银行流水记录5年、证人证言笔录48份、相关法条判例200多个……总计超过100万字的资料需要整理分析。小张满怀希望地打开了法院新引进的AI辅助系统,输入第一批材料后,系统却弹出提示:“ 输入内容超出模型最大处理长度(128K tokens),请精简后重试 ”。
这不是孤例。据最高人民法院发布的《2023年智慧法院建设白皮书》显示,全国法院系统每年新收案件超过3000万件,平均每个案件的电子卷宗容量达到500MB,其中文本内容平均超过20万字。面对如此庞大的司法文书,即便是目前最先进的GPT-5(128K上下文)或Claude-4.5(200K上下文),也显得无能为力。
如何让AI在不丢失关键信息的前提下,突破token数量限制,完整理解和处理超长司法文书?这正是上下文压缩技术要解决的核心问题。
在深入探讨解决方案之前,我们需要理解为什么大模型会有token数量限制。这不仅仅是一个技术参数,更是涉及计算资源、模型架构、经济成本等多方面的系统性挑战。
什么是Token?
Token是大型语言模型处理文本的基本单位。在中文语境下,一个token大约对应1-2个汉字。以一份标准的民事判决书为例:“原告张某某诉被告李某某民间借贷纠纷一案”这句话,会被分解为约10-12个token。一份完整的判决书(通常5000-10000字)就需要消耗3000-8000个token。
更复杂的是,司法文书中充斥着专业术语、法条引用、格式化表述,这些内容的token消耗往往高于普通文本。例如:“根据《中华人民共和国民法典》第五百零九条第一款之规定”这样一句标准的法条引用,就需要消耗约20个token。当一个案件涉及数十个法条、上百个证据材料时,token消耗呈指数级增长。
Transformer架构的核心是自注意力机制(Self-Attention),它让模型能够理解文本中任意两个位置之间的关系。然而,这种强大的能力是有代价的:计算复杂度为O(n),其中n是序列长度。
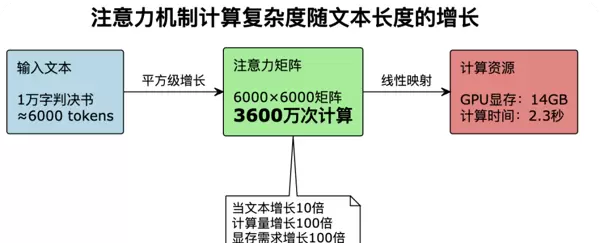
这意味着,当我们处理一份10万字的案卷(约6万个token)时,需要进行36亿次注意力计算,需要的GPU显存超过1.4TB——这已经远超当前主流硬件的能力范围。即便是配备A100 GPU(80GB显存)的高端服务器,也只能勉强处理3-4万token的内容。
司法领域的文本处理面临着独特的挑战,这些挑战让token限制问题更加突出:
法律推理强调证据链的完整性。一个经济犯罪案件可能涉及数年的资金流水,任何一笔关键交易的遗漏都可能影响案件定性。传统的文本截断方法在这里完全不适用——你不能因为token限制就只看前半部分的银行流水。司法AI需要准确引用相关法条和判例。以知识产权纠纷为例,可能需要同时参考《专利法》、《商标法》、《反不正当竞争法》等多部法律,以及最高法的指导性案例。这些引用必须完整、准确,不能因压缩而失真。许多案件的关键在于时间线的梳理。一起建设工程合同纠纷,从项目立项、招投标、合同签订、施工过程、质量验收到最终结算,时间跨度可能长达数年。AI需要在这个完整的时间线上进行推理,任何时间节点的缺失都可能导致错误的判断。案件往往涉及多个诉讼主体。比如一起公司股权纠纷,可能涉及大股东、小股东、实际控制人、关联公司、债权人等十几个主体,每个主体都有自己的诉求和证据。AI需要在这个复杂的关系网络中理清脉络。面对上述挑战,研究者们提出了多种上下文压缩技术。让我们结合司法场景,深入剖析每种技术的原理、优势和局限性。滑动窗口是最直观的压缩方法:只保留最近的N个token,超出部分自动“遗忘”。这种方法的实现极其简单,几乎不需要额外的计算开销。
司法应用案例: 在线法律咨询
某互联网法院的在线咨询系统采用了滑动窗口策略。用户咨询劳动争议时,系统保持最近3000个token的对话历史:
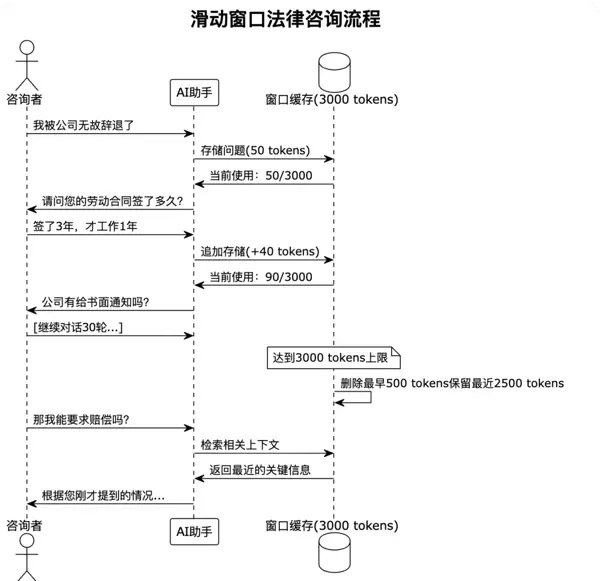
这种方法在简单的法律咨询场景下表现良好,因为用户的问题通常比较集中,最近的几轮对话包含了最相关的信息。然而, 当用户咨询复杂案件或需要引用早期提到的关键信息时,滑动窗口就会出现严重的信息丢失。
实际案例的教训: 某律所的AI助手在处理一起劳动仲裁咨询时,用户在对话开始时提到了“入职时公司口头承诺的年终奖”,但经过20多轮对话后,这个关键信息被滑出窗口。当用户最后问“我的年终奖能要回来吗”时,AI因为失去了上下文,给出了完全错误的建议。
摘要提取技术通过NLP算法识别文本中的关键信息,生成压缩版本。在司法领域,这相当于将冗长的案卷材料提炼成“案情摘要”。
司法应用案例: 判决书智能摘要系统
北京市某基层法院开发了判决书自动摘要系统,采用基于BERT的抽取式摘要算法:
# 简化的判决书摘要提取流程
def extract_judgment_summary(judgment_text):
# 1. 识别判决书的标准结构
sections = {
'当事人信息': extract_parties(judgment_text),
'案由': extract_case_type(judgment_text),
'诉讼请求': extract_claims(judgment_text),
'事实认定': extract_facts(judgment_text),
'法院观点': extract_court_opinion(judgment_text),
'判决结果': extract_verdict(judgment_text)
}
# 2. 对每个部分进行重要性评分
importance_scores = calculate_importance(sections)
# 3. 基于评分选择关键句子
key_sentences = select_key_sentences(sections, importance_scores)
# 4. 生成结构化摘要
summary = generate_structured_summary(key_sentences)
return summary该系统能将平均8000字的判决书压缩到800字左右,保留了案件的核心要素。在处理大量类案检索时效果显著:法官可以快速浏览数十份相似案例的摘要,找到最相关的判例。
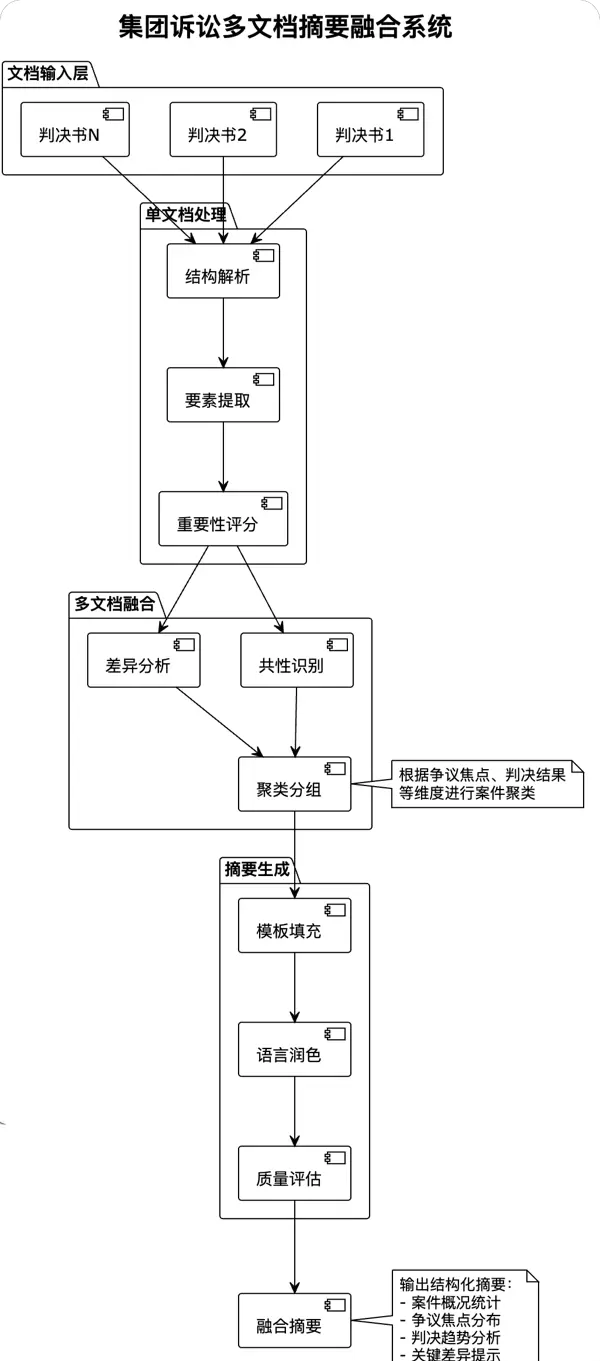
进阶应用: 多文档摘要融合
更复杂的场景是多文档摘要。例如在一起集团诉讼中,有50个相似案件,每个案件都有独立的判决书。系统需要:
3. 生成融合摘要(“50个案件均涉及产品质量问题,其中30个判决支持消费者,20个驳回诉讼请求,支持率与产品批次高度相关…”)
摘要技术的局限性:尽管摘取内容在许多情况下有效,但它存在一个严重缺陷——信息丢失不可逆。一旦某个细节被认定为“不重要”而被过滤掉,后续就无法恢复。在法律领域,一个看似微不足道的细节可能成为案件的关键点。
2.3 向量化压缩:语义空间的降维魔法
向量化压缩是近年来的一项热门技术,它将文本转换为高维向量,在语义空间中进行压缩和检索。这种方法的核心思想在于:相似的内容在向量空间中的距离较近,可以用一个向量代表一类信息。
司法应用案例:海量判例的语义检索系统
某省高级人民法院构建了一个包含500万份判决书的判例库,采用向量化压缩技术实现高效检索:
# 判例向量化与检索系统架构
classJudicialVectorDatabase:
def __init__(self):
self.encoder = SentenceTransformer('legal-bert-base')
self.vector_dim = 768
self.index = FAISSIndex(self.vector_dim)
def process_judgment(self, judgment):
# 1. 分段处理长文本
segments = self.split_into_segments(judgment, max_length=512)
# 2. 生成段落向量
vectors = []
for segment in segments:
vec = self.encoder.encode(segment)
vectors.append(vec)
# 3. 向量压缩(使用PCA或AutoEncoder)
compressed_vec = self.compress_vectors(vectors)
# 4. 存储元数据
metadata = {
'case_id': judgment['id'],
'court': judgment['court'],
'case_type': judgment['type'],
'judgment_date': judgment['date'],
'key_points': self.extract_key_points(judgment)
}
return compressed_vec, metadata
def semantic_search(self, query, top_k=10):
# 查询向量化
query_vec = self.encoder.encode(query)
# 向量检索
distances, indices = self.index.search(query_vec, top_k)
# 返回相关案例
return self.retrieve_cases(indices, distances)这个系统能够在大量的判例中迅速找到语义相似的案例。例如,当法官输入“未成年人网络游戏充值退款”时,系统不仅能找到直接相关的案例,还能检索到“未成年人网络直播打赏”、“未成年人电商消费”等语义相近的判例。
向量压缩的高级应用:分层语义索引
为了处理超长文书,系统采用了分层次向量化策略:
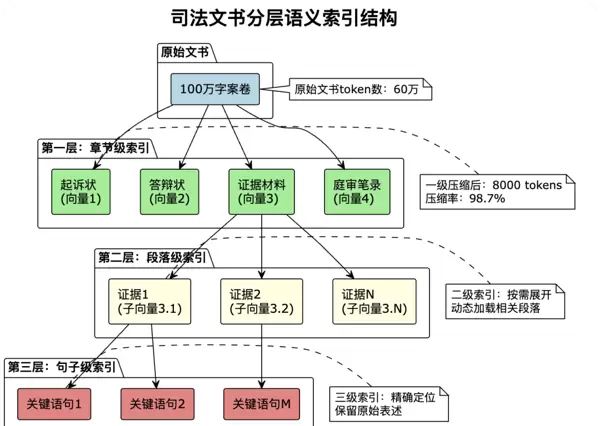
通过这种分层结构,系统可以先在高层次快速定位相关内容,然后逐层深入,按需加载详细信息。这样既保证了检索效率,又避免了信息丢失。
向量化压缩的挑战:
2.4 图结构压缩:司法知识的网络化表示
图结构压缩将文本信息组织成知识图谱,通过节点和边的关系网络来表示复杂的法律知识。这种方法特别适合处理涉及多个主体、复杂关系的案件。
司法应用案例:经济犯罪关系图谱
某市检察院在办理一起特大非法集资案时,使用图结构技术梳理资金流向:
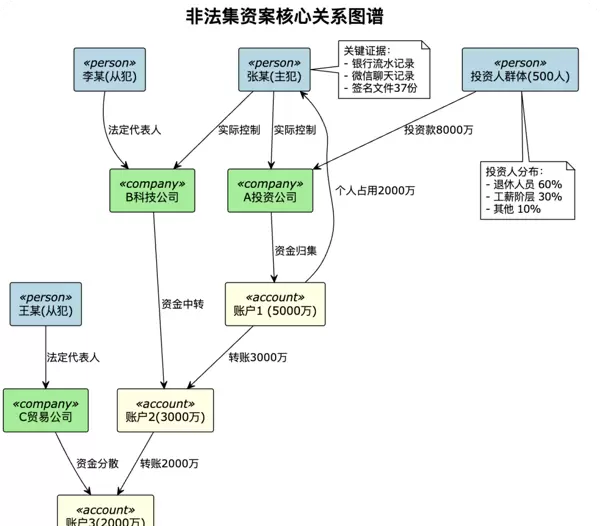
通过图结构,检察官可以清晰地看到:
图压缩的高级特性:子图提取与推理
面对复杂的关系网络,系统可以根据需要提取相关子图:
classJudicialKnowledgeGraph:
def __init__(self):
self.graph = nx.DiGraph() # 有向图
self.node_embeddings = {} # 节点嵌入向量
self.edge_types = {} # 边类型定义
def build_case_graph(self, case_data):
# 1. 提取实体(人、组织、账户、证据等)
entities = self.extract_entities(case_data)
# 2. 识别关系(控制、转账、签约等)
relations = self.extract_relations(case_data)
# 3. 构建图结构
for entity in entities:
self.graph.add_node(entity.id, **entity.attributes)
for relation in relations:
self.graph.add_edge(
relation.source,
relation.target,
type=relation.type,
weight=relation.confidence,
evidence=relation.evidence_ids
)
def compress_subgraph(self, query_entities, max_hops=3):
"""根据查询实体提取相关子图"""
# 1. 多跳邻居提取
relevant_nodes = set()
for entity in query_entities:
neighbors = nx.single_source_shortest_path_length(
self.graph, entity, cutoff=max_hops
)
relevant_nodes.update(neighbors.keys())
# 2. 子图构建
subgraph = self.graph.subgraph(relevant_nodes)
# 3. 重要性评分与进一步压缩
importance_scores = self.calculate_importance(subgraph)
# 4. 保留核心节点和边
core_nodes = [n for n, score in importance_scores.items()
if score > threshold]
compressed_graph = subgraph.subgraph(core_nodes)
return compressed_graph图结构压缩的独特优势:
2.5 混合策略:取长补短的智能组合
单一的压缩方法往往难以应对司法领域的复杂需求,因此实践中常采用混合策略,根据不同类型的内容选择最适合的压缩方法。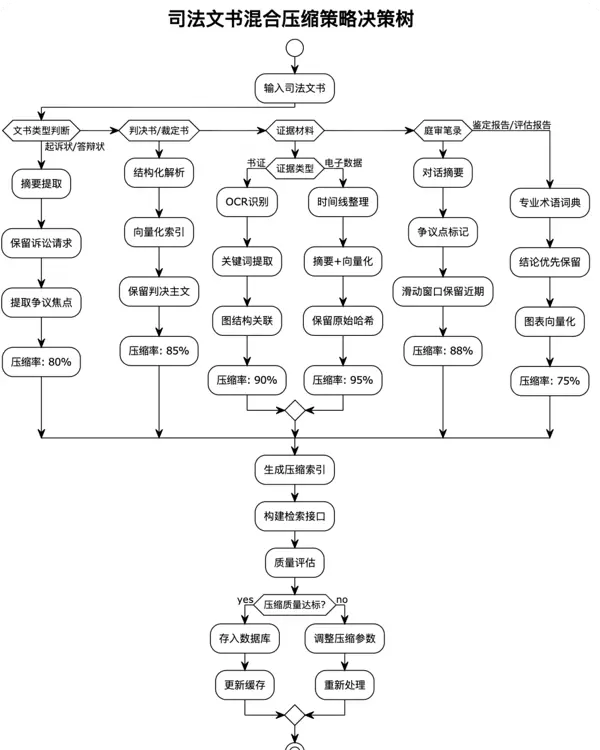
混合策略的实现细节:
classContentTypeClassifier:
def __init__(self):
self.patterns = {
'起诉状': ['原告', '被告', '诉讼请求', '事实与理由'],
'判决书': ['案号', '审理查明', '本院认为', '判决如下'],
'合同': ['甲方', '乙方', '权利义务', '违约责任'],
'证据': ['证明事项', '来源', '真实性', '关联性']
}
def classify(self, text):
scores = {}
for doc_type, keywords in self.patterns.items():
score = sum(1for kw in keywords if kw in text)
scores[doc_type] = score
return max(scores, key=scores.get)系统根据实时的GPU内存使用情况和响应时间要求,动态调整压缩率:
classCompressionEvaluator:
def evaluate(self, original, compressed, task_type):
metrics = {
'compression_ratio': len(compressed) / len(original),
'information_retention': self.calculate_info_retention(
original, compressed
),
'task_performance': self.test_downstream_task(
compressed, task_type
),
'latency': self.measure_processing_time(compressed),
'user_satisfaction': self.get_user_feedback()
}
# 综合评分
score = (
metrics['information_retention'] * 0.4 +
metrics['task_performance'] * 0.3 +
(1 - metrics['latency']) * 0.2 +
metrics['user_satisfaction'] * 0.1
)
return score, metrics03 AI的实践突破:从理论到落地
上下文压缩技术在法律领域的应用不仅停留在理论层面,已经在多个实际项目中取得突破性进展。让我们深入了解典型的落地案例。
"类案推送"系统的压缩创新
"类案智能推送系统"是上下文压缩技术的典型应用。该系统需要在包含2亿份判决书的数据库中,为法官实时推送相关案例。
技术挑战与解决方案:
系统采用离线批处理+在线增量更新的混合架构:
classCaseVectorProcessor:
def __init__(self):
self.batch_size = 10000
self.vector_db = FAISSCluster(n_clusters=1000)
def offline_processing(self):
"""离线批处理历史判决书"""
for batch in self.get_case_batches():
# 1. 批量向量化
vectors = self.batch_encode(batch)
# 2. 层次聚类
clusters = self.hierarchical_clustering(vectors)
# 3. 生成聚类中心摘要
for cluster_id, cluster_cases in clusters.items():
centroid = self.compute_centroid(cluster_cases)
summary = self.generate_cluster_summary(cluster_cases)
# 存储压缩后的表示
self.vector_db.add_cluster(
cluster_id, centroid, summary
)
def online_update(self, new_case):
"""在线处理新判决书"""
# 1. 快速向量化
vector = self.encode(new_case)
# 2. 找到最近的聚类
nearest_cluster = self.vector_db.find_nearest_cluster(vector)
# 3. 判断是否需要创建新聚类
if self.distance(vector, nearest_cluster.centroid) > threshold:
self.create_new_cluster(new_case)
else:
self.update_cluster(nearest_cluster, new_case)为了实现毫秒级的推送延迟,系统采用了多级缓存策略:
系统不仅考虑文本相似度,还结合了法律领域的特殊因素:
def calculate_relevance_score(query_case, candidate_case):
# 基础文本相似度
text_similarity = cosine_similarity(
query_case.vector, candidate_case.vector
)
# 法条重合度
law_overlap = jaccard_similarity(
query_case.laws, candidate_case.laws
)
# 案由匹配度
case_type_match = 1.0if query_case.type == candidate_case.type else0.5
# 时间相关性(越近期的案例权重越高)
time_weight = exp(-days_diff / 365) # 指数衰减
# 法院层级权重
court_weight = {
'最高法': 1.0,
'高院': 0.8,
'中院': 0.6,
'基层': 0.4
}[candidate_case.court_level]
# 综合评分
final_score = (
text_similarity * 0.3 +
law_overlap * 0.25 +
case_type_match * 0.2 +
time_weight * 0.15 +
court_weight * 0.1
)
return final_score实际效果:
04 技术实现的核心挑战与解决方案
在法律领域应用上下文压缩技术,面临独特的考验。让我们深入探讨这些考验及其解决策略。
法律语言追求高度的精确性,一字之差可能导致截然不同的法律后果。例如,“应当”与“可以”,“情节严重”与“情节恶劣”,这些细微差异在压缩过程中必须完整保留。
解决策略:法律术语保护机制
classLegalTermProtector:
def __init__(self):
# 加载法律术语词典
self.legal_terms = self.load_legal_dictionary()
self.protected_patterns = [
r'第[零一二三四五六七八九十百千万]+条', # 法条
r'应当|可以|必须|禁止|不得', # 义务词
r'故意|过失|明知|应知', # 主观要件
r'情节严重|情节恶劣|情节较轻', # 量刑情节
]
def protect_terms(self, text):
"""标记需要保护的法律术语"""
protected_segments = []
# 1. 识别法律术语
for pattern in self.protected_patterns:
matches = re.finditer(pattern, text)
for match in matches:
protected_segments.append({
'start': match.start(),
'end': match.end(),
'text': match.group(),
'type': 'legal_term',
'importance': 1.0 # 最高重要性
})
# 2. 识别引用的法条
law_citations = self.extract_law_citations(text)
for citation in law_citations:
protected_segments.append({
'text': citation,
'type': 'law_citation',
'importance': 1.0
})
return protected_segments
def compress_with_protection(self, text, target_length):
"""在保护法律术语的前提下压缩文本"""
# 1. 识别保护区域
protected = self.protect_terms(text)
# 2. 分割文本为保护区和非保护区
segments = self.split_by_protection(text, protected)
# 3. 仅压缩非保护区
compressed_segments = []
for segment in segments:
if segment['protected']:
compressed_segments.append(segment['text'])
else:
compressed = self.compress_segment(
segment['text'],
segment['target_length']
)
compressed_segments.append(compressed)
return''.join(compressed_segments)司法推理依赖于完整的证据链,任何环节的缺失都可能影响案件判断。压缩过程必须确保证据链的逻辑完整。
解决策略:证据链图谱构建
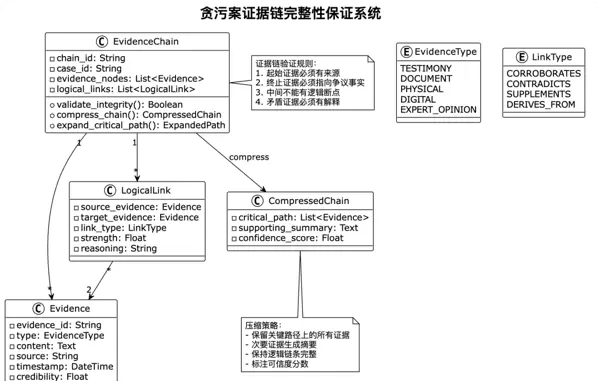
实际应用案例:职务侵占案的证据链压缩
def compress_embezzlement_evidence_chain(case_evidence):
"""压缩职务侵占案证据链"""
# 1. 构建证据图谱
evidence_graph = build_evidence_graph(case_evidence)
# 2. 识别关键证据路径
critical_paths = []
# 路径1:资金流向证明
fund_flow_path = [
evidence_graph.get('bank_records'), # 银行流水
evidence_graph.get('accounting_books'), # 账簿记录
evidence_graph.get('audit_report'), # 审计报告
evidence_graph.get('personal_account') # 个人账户
]
critical_paths.append(fund_flow_path)
# 路径2:职务便利证明
position_path = [
evidence_graph.get('job_description'), # 职务说明
evidence_graph.get('authorization'), # 授权文件
evidence_graph.get('signature_samples'), # 签名样本
evidence_graph.get('operation_logs') # 操作日志
]
critical_paths.append(position_path)
# 路径3:非法占有证明
possession_path = [
evidence_graph.get('consumption_records'), # 消费记录
evidence_graph.get('property_purchase'), # 财产购买
evidence_graph.get('witness_testimony'), # 证人证言
evidence_graph.get('confession') # 供述
]
critical_paths.append(possession_path)
# 3. 压缩非关键证据
compressed_evidence = {}
for evidence_id, evidence in evidence_graph.items():
if evidence in flatten(critical_paths):
# 关键证据完整保留
compressed_evidence[evidence_id] = evidence
else:
# 非关键证据压缩
compressed_evidence[evidence_id] = {
'summary': summarize_evidence(evidence),
'key_points': extract_key_points(evidence),
'relevance_score': calculate_relevance(evidence),
'original_location': evidence.storage_path
}
# 4. 生成证据链分析报告
chain_analysis = {
'critical_paths': critical_paths,
'compressed_evidence': compressed_evidence,
'chain_integrity': validate_chain_integrity(critical_paths),
'total_compression_ratio': calculate_compression_ratio(
case_evidence, compressed_evidence
)
}
return chain_analysis现代司法证据不仅包括文本,还有图像(现场照片)、音频(录音证据)、视频(监控录像)等多模态信息。如何统一压缩这些异构数据是一大挑战。
解决策略:多模态融合压缩框架
classMultiModalCompressor:
def __init__(self):
self.text_compressor = TextCompressor()
self.image_compressor = ImageCompressor()
self.audio_compressor = AudioCompressor()
self.video_compressor = VideoCompressor()
self.fusion_model = MultiModalFusionModel()
def compress_evidence_package(self, evidence_package):
compressed_data = {
'metadata': self.extract_metadata(evidence_package),
'modalities': {}
}
# 1. 分模态压缩
for modality, data in evidence_package.items():
if modality == 'text':
compressed = self.compress_text_evidence(data)
elif modality == 'image':
compressed = self.compress_image_evidence(data)
elif modality == 'audio':
compressed = self.compress_audio_evidence(data)
elif modality == 'video':
compressed = self.compress_video_evidence(data)
compressed_data['modalities'][modality] = compressed
# 2. 跨模态关联分析
correlations = self.analyze_cross_modal_correlations(
compressed_data['modalities']
)
# 3. 生成统一表示
unified_representation = self.fusion_model.fuse(
compressed_data['modalities'],
correlations
)
compressed_data['unified'] = unified_representation
return compressed_data
def compress_image_evidence(self, images):
"""压缩图像证据(如现场照片)"""
compressed_images = []
for image in images:
# 1. 关键区域检测(如伤痕、物证位置)
key_regions = self.detect_key_regions(image)
# 2. 生成图像描述
description = self.generate_image_description(image)
# 3. 保留关键区域高清,其他区域降质
compressed_img = self.selective_compression(
image, key_regions
)
compressed_images.append({
'compressed_image': compressed_img,
'description': description,
'key_regions': key_regions,
'forensic_markers': self.extract_forensic_markers(image)
})
return compressed_images司法数据涉及大量个人隐私和敏感信息,压缩过程必须确保数据安全,防止信息泄露。
解决策略:差分隐私压缩技术
classPrivacyPreservingCompressor:
def __init__(self, privacy_budget=1.0):
self.privacy_budget = privacy_budget
self.anonymizer = DataAnonymizer()
self.encryptor = HomomorphicEncryptor()
def compress_with_privacy(self, judicial_document):
# 1. 识别敏感信息
sensitive_entities = self.identify_sensitive_info(judicial_document)
# 2. 分级脱敏处理
anonymized_doc = self.apply_differential_privacy(
judicial_document, sensitive_entities
)
# 3. 同态加密压缩
encrypted_compressed = self.homomorphic_compression(anonymized_doc)
# 4. 生成审计日志
self.audit_logger.log({
'operation': 'compress_with_privacy',
'document_id': judicial_document.id,
'privacy_level': self.calculate_privacy_level(anonymized_doc),
'timestamp': datetime.now()
})
return encrypted_compressed
def identify_sensitive_info(self, document):
"""识别需要保护的敏感信息"""
sensitive_patterns = {
'identity': {
'pattern': r'\d{17}[\dX]', # 身份证号
'replacement': lambda x: f"***{x[-4:]}",
'sensitivity': 0.9
},
'phone': {
'pattern': r'1[3-9]\d{9}', # 手机号
'replacement': lambda x: f"{x[:3]}****{x[-4:]}",
'sensitivity': 0.7
},
'address': {
'pattern': r'[\u4e00-\u9fa5]+市[\u4e00-\u9fa5]+区.*\d+号',
'replacement': lambda x: self.generalize_address(x),
'sensitivity': 0.6
},
'bank_account': {
'pattern': r'\d{16,19}', # 银行账号
'replacement': lambda x: f"****{x[-4:]}",
'sensitivity': 0.8
},
'minor_name': { # 未成年人姓名
'detector': self.detect_minor_names,
'replacement': lambda x: "某未成年人",
'sensitivity': 1.0
}
}
return self.extract_sensitive_entities(document, sensitive_patterns)
def apply_differential_privacy(self, document, sensitive_entities):
"""应用差分隐私技术"""
# 添加拉普拉斯噪声
noise_scale = 1.0 / self.privacy_budget
for entity in sensitive_entities:
if entity['type'] == 'numeric':
# 数值型数据添加噪声
original_value = float(entity['value'])
noise = np.random.laplace(0, noise_scale * entity['sensitivity'])
entity['private_value'] = original_value + noise
else:
# 类别型数据使用随机响应
entity['private_value'] = self.randomized_response(
entity['value'], entity['sensitivity']
)
return self.reconstruct_document(document, sensitive_entities)隐私保护的层次架构:
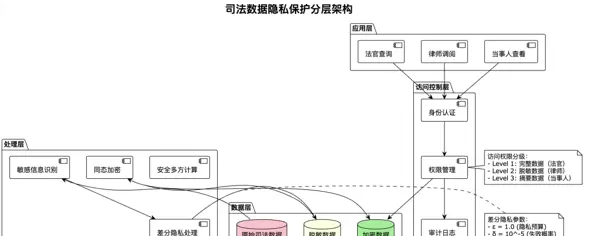
上下文压缩技术不仅是司法AI的技术突破点,更是推动司法现代化的重要动力。随着技术的不断成熟和应用的深入推广,我们有理由相信,智慧司法的美好愿景终将实现。
在这个AI技术快速发展的时代,法律领域正经历着前所未有的变革。上下文压缩技术作为这场变革的关键支柱,将继续发挥重要作用。让我们共同期待,在不久的将来,每个公民都能享受到更加公正、高效、智能的司法服务。
生命由一段又一段的旅程连接而成,在每段旅程中,都能发现不同的风景。
最近几年,经济形势下滑,IT行业面临经济周期波动与AI产业结构调整的双重压力,许多人都迫于无奈,要么被裁员,要么被降薪,苦不堪言。但我想说的是,一个行业的下行必然会有上行行业,目前AI大模型的趋势就非常不错,大家应该也经常听说大模型,知道这是趋势,但苦于没有入门的机会,现在它来了,我在本平台找到了一个非常适合新手学习大模型的资源。想学习和了解大模型的朋友可以**点击这里前往查看**。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




