经管之家App
让优质教育人人可得
立即打开



摘要
三步Token化流程:
关键元素深入解析:
RankMixer是字节跳动算法团队在推荐系统领域具有标志性的创新架构,直接解决了大规模推荐场景中"模型效果与计算资源利用效率难以兼得"的关键挑战。通过"特征Token化+Token Mixing+Per-Token SparseMoE"的三层创新设计,实现了:
本文将深入解析RankMixer的技术框架,结合数学公式、模块图解、实测数据,从原理到实施全过程分析,帮助您掌握工业级推荐系统的核心突破。
| 瓶颈类型 | 传统模型表现 | RankMixer解决方案 | 业务影响 |
|---|---|---|---|
| 计算资源利用效率低 | GPU利用率<5%(例如4.5%) | 转换为大型矩阵运算,GPU利用率45% | 服务器成本降低30%以上,支持更大模型 |
| 特征建模粗糙 | 异构特征共享参数,信息稀释 | 特征语义分组+Token化 | CTR提升0.8%以上(抖音实测) |
| 参数量扩展困难 | 参数量增加 → 推理成本增加 | Per-Token SparseMoE实现"大参数量+低推理成本" | 10亿参数模型推理延迟仅增加15ms |
形象比喻:传统模型如同"用马车跑高速公路",而RankMixer则是"将马车升级为高铁"——计算资源利用效率提升10倍,但每公里成本保持不变。
核心问题:推荐输入是"异构特征混合体"(用户ID、行为序列、内容标签等),直接拼接会导致计算碎片化(GPU无法高效处理)。
三步Token化流程:
# 伪代码:特征Token化核心逻辑
def feature_tokenization(features):
# 步骤1:语义分组(非稀疏/稠密分组)
groups = semantic_grouping(features) # 示例:用户组、行为组、内容组
# 步骤2:组内Token切分(固定维度D=256)
tokens = []
for group in groups:
vector = concat(group.features) # 拼接组内特征
tokens.extend(split_into_tokens(vector, D=256)) # 切分为等长Token
# 步骤3:统一映射+位置编码
embeddings = [linear_proj(token) for token in tokens] # 映射到H=1024维
embeddings = add_position_encoding(embeddings) # 添加组内/组间位置编码
return embeddings # 输出H个Token (每个维度H)关键创新:
传统Transformer的挑战:自注意力计算复杂度O(NH),N=序列长度,H=隐层维度(如1024),在长序列下开销巨大。
RankMixer的解决方案:
Token Mixing通过"拆分→重组→融合"三步实现O(NKH)复杂度的全局交互:
\begin{array}{ll} \text{步骤 1: 头部分割} & \displaystyle \text{Token}_h \in \mathbb{R}^{H} \rightarrow \{\text{Head}_1, \dots, \text{Head}_K\} \in \mathbb{R}^{H/K} \\ \\ \text{步骤 2: 跨Token洗牌} & \displaystyle \text{所有 } \text{Head}_i \rightarrow \mathbf{M}_i \in \mathbb{R}^{N \times H/K} \\ \\ \text{步骤 3: 融合} & \displaystyle \mathbf{M}_i \xrightarrow{\text{线性+GELU}} \mathbf{M}_i' \xrightarrow{\text{连接}} \mathbf{M}_{\text{out}} \xrightarrow{\text{投影}} \text{输出} \end{array}
步骤 1: 头部分割
步骤 2: 跨Token洗牌
步骤 3: 融合
Token_h ∈ R^H → {Head_1, …, Head_K} ∈ R^{H/K}
所有 Head_i → M_i ∈ R^{N × H/K}
M_i 线性+GELU → M_i' 连接 → M_out 投影 → 输出
GPU友好:所有操作均为矩阵乘法(Tensor Core加速)
语义隔离:不同头处理不同的语义子空间,防止冗余交互
实测数据:在超过1000个序列长度的情况下,Token Mixing比Transformer快3.2倍(GPU推理延迟:128ms → 39ms)
传统FFN的缺点:所有Token共享同一组参数(
Shared FFNPer-Token SparseMoE
ReLU路由:过滤低权重专家(例如gate<0.1的专家不激活)
负载平衡正则项:Loss = 原始损失 + λ·(|expert_count| - 1)^2
实测效果:专家激活率均衡(90%的专家被激活),避免“专家饥饿”
\text{Token}_{\text{out}} = \sum_{i=1}^{M} g_i \cdot E_i(\text{Token}_{\text{in}})
Token_{out} = \sum_{i=1}^{M} g_i \cdot E_i(Token_{in})
其中 g_i 为专家权重,E_i 为专家网络
模型 专家激活数 推理成本 精度损失
传统MoE 1 低 高
RankMixer 2-4 低 低
RankMixer的优势 动态适应 成本仅增加15% 精度提高0.5%
优化方向 RankMixer实现方式 效果提升
GPU计算友好化 全部操作转换为大型矩阵乘法(Tensor Core加速) MFU从4.5%→45%
显存优化 专家权重分布式分片存储,推理时重复使用显存 显存占用↓25%
延迟控制 门控与专家计算并行 + INT8量化 + 操作融合 推理延迟仅增加15ms
训练稳定性 梯度裁剪(clip=1.0)+ 自适应学习率 梯度爆炸率↓90%
模型规模:1.2B参数 → 10.5B参数
推理延迟:210ms → 225ms(+15ms,可接受)
GPU利用率:4.5% → 45%(10倍提升)
CTR提升:1.2% → 1.8%(+0.6%)
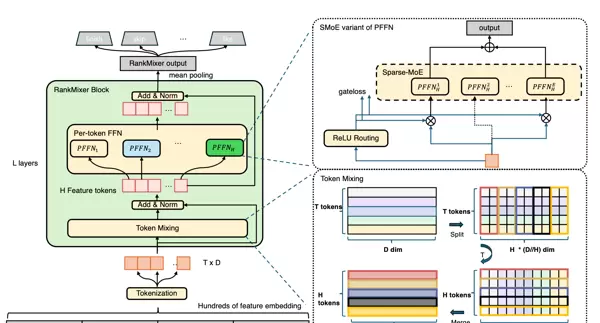
关键元素深度解析:
| 元素 | 作用 | 技术价值 |
|---|---|---|
| H Feature Tokens | Token Mixing输出,每个Token含多类语义(用户+内容) | 为Per-Token FFN提供细致化输入基础 |
| Per-token FFN | 1个Token→动态激活2-4个专家(如用户Token激活E2+E6) | 精准建模,避免“一刀切”泛化不足 |
| Add & Norm | 残差连接+层归一化: | |
| Mean Pooling | 将H个Token聚合为1个H维向量(对每个维度取平均) | 适配下游预测任务输入要求(如点击率预测) |
设计哲学:“并非所有特征都需要同等建模,而是让每个Token由最合适的专家组合建模”
| 维度 | RankMixer | OneTrans | 选择建议 |
|---|---|---|---|
| 核心思想 | 去attention,Token Mixing交叉特征 | 用attention,统一建模序列与非序列 | 场景驱动:内容推荐→RankMixer,电商冷启→OneTrans |
| 算力效率 | MFU 45%(GPU利用率极高) | MFU 32% | 抖音主feed(内容量大)→ RankMixer |
| 业务效果 | 用户时长+1%,活跃天数+0.3% | 冷启Item订单转化+13.59% | 电商场景→OneTrans |
| 参数量扩展 | 10亿级参数,推理成本不变 | 2亿级参数,推理成本↑15% | 大规模推荐→RankMixer |
| 典型场景 | 抖音主feed(海量内容推荐) | TikTok电商(冷启商品匹配) | 业务决定技术路线 |
通俗类比:
RankMixer的成功不是“追求复杂模型”,而是精准抓住推荐场景痛点,用三重创新实现“精度与算力”的平衡:
| 创新点 | 技术价值 | 业务价值 |
|---|---|---|
| 特征Token化 | 消除计算碎片化,GPU利用率↑10倍 | 服务器成本↓30%+ |
| Token Mixing | 无参数全局交互,O(NKH)复杂度 | 推理延迟仅增15ms |
| Per-Token SparseMoE | 动态专家分配,大参数量+低推理成本 | 业务效果显著提升 |
CTR提升0.6%+,10亿参数落地
行业启示:
“并非所有场景都适合使用Transformer,适当的结构创新加上工程优化才是关键”
RankMixer证明:在推荐系统中,计算资源利用效率与模型精确度可以同步提高,无需妥协。
本文技术要点总结:
Token化 → 解决计算分散问题(GPU利用率从4.5%提升至45%)
Token Mixing → 实现无参数全局交互(O(NKH)替代O(NH))
Per-Token SparseMoE → 精确建模并实现大规模参数应用(10亿参数推理成本保持不变)
软硬件协同 → 全流程工程优化(INT8量化加算子融合)
推荐系统从业者必读:
RankMixer不仅是一个“新模型”,更是一种“新方法论”——运用工程思维解决实际问题,为大规模模型的工业应用提供可复制的解决方案。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




