
" alt="图片1" />
文章目录
- 摘要
- 概述
- 多视图一致性稠密化
- 多视图一致性剪枝
- Compact Box
- 实验
- FastGS的通用性
一、摘要
当前流行的三维高斯溅射(3DGS)加速技术,在训练过程中难以有效地管理高斯分布的数量,导致计算资源的浪费。本文介绍的FastGS框架提供了一个既简洁又通用的加速解决方案,通过多视图一致性机制全面评估各个高斯基元的重要性,从而高效地平衡了训练效率和渲染质量。FastGS设计了基于多视图一致性的密度增强与剪枝策略,摒弃了传统的预算分配机制。在Mip-NeRF 360、Tanks & Temples和Deep Blending数据集的大规模测试中,FastGS在训练速度上显著优于现有的最佳方法,例如在Mip-NeRF 360数据集上比DashGaussian快3.32倍,在Deep Blending数据集上比基本3DGS快15.45倍,同时保持了与DashGaussian相媲美的渲染质量。实验还证明了FastGS在动态场景重建、表面重建、稀疏视图重建、大规模重建及同步定位建图等任务中的强大通用性,训练加速比可达2-7倍。
二、概述
FastGS框架(如图3所示)采用SfM点云初始化3DGS,并在多视图图像上进行训练。通过提出的多视图一致性致密化和剪枝策略来控制3DGS的增减。如图3b和图3c所示,Taming-3DGS[25]和Speedy-Splat[12]也分别从多视图中估计高斯分数用于致密化和剪枝。然而,这两种方法都依赖于与高斯分布相关的分数来控制高斯数量,而不是考虑每个高斯对多视图渲染质量的贡献。这种对多视图信息的次优利用导致Taming-3DGS[25]出现冗余问题,而Speedy-Splat[12]则导致渲染质量下降。相比之下,如图3a所示,我们的方法根据多视图重建质量而非高斯属性来评估每个高斯的重要性。此外,我们的方法在致密化和剪枝过程中都利用了多视图一致性,具体细节将在第三和第四节中讨论。为了进一步提高光栅化效率,第五节介绍了我们使用的紧凑框(CB)技术。
" alt="图片2" />
三、多视图一致性稠密化
传统的3DGS仅根据图像空间中的梯度幅值对高斯基元进行密度增强,这会导致大量的冗余高斯。其他稠密化方法[4,8,44]同样会生成数百万个高斯基元,导致效率低下。我们认为这种冗余现象源于这些方法未能严格判断多视角中是否需要对某个高斯进行密度增强。如图3b所示,Taming-3DGS在密度增强过程中考虑了多视角一致性,主要依据高斯相关属性(如不透明度、缩放比例、深度和梯度)而非其对渲染质量的实际贡献来计算评分,这使得难以严格保证高斯基元的多视角一致性。如图3b左侧所示,这也导致了冗余问题。此外,其评分计算过程复杂且效率较低。为了解决这些问题,我们提出了一种基于多视角一致性的新型简单密度增强策略VCD。如图3a所示,该方法通过采样视角计算每个高斯分布2D足迹中高误差像素的平均数量,其中高误差像素仅通过真实值与渲染结果之间的逐像素L1损失来判定。如图3a左侧所示,VCD在使用较少高斯分布的情况下实现了可比的渲染质量,从而大幅减少了冗余问题。接下来我们将详细介绍VCD的具体实现方法:
给定K个相机视角 \( V = \{ v^j \}_{j=1}^k \) (从训练视图中随机抽取),以及对应的真值图像 \( G = \{ g^j \}_{j=1}^k \) 和渲染图像 \( R = \{ r^j \}_{j=1}^k \)。针对每个视角 \( v^j \),计算渲染颜色 \( r_{u,v}^{j,c} \) 与真值颜色 \( g_{u,v}^{j,c} \) 在像素 \( (u,v) \) 处的误差:
" alt="图片3" />
其中 \( c \) 表示颜色通道。根据逐像素误差构建损失映射 \( M^j \in R^{W \times H} \):
" alt="图片4" />
其中每个 \( \hat{e}^j_{u,v} \) 值均通过最小-最大归一化获得:
" alt="图片5" />
随后对 \( M^j \) 应用阈值 \( \tau \),识别出重建误差较大的像素 \( p_h \),并生成mask:
" alt="图片6" />
其中像素P的 \( M^j_{mask}(u,v) = 1 \) 表示重建质量较差的区域。接下来,要找到与这些高误差像素相关的高斯基元。对于每个3D高斯基元 \( G_i \),将其投影到2D图像空间,以获得其2D足迹 \( \Omega_i \)。然后,我们使用指示函数判断像素是否存在高误差,为每个高斯基元计算重要性评分 \( s^+_i \),通过统计所有采样视图中二维足迹内高误差像素的数量进行累积,最终对累积值取平均值:
" alt="图片7" />
当 \( s^+_i \) 较大时,表明该高斯基元在多个视图中对提高重建质量有重要作用,因此应保留或增加其密度;反之,则可考虑减少其密度或移除。
四、多视图一致性剪枝
多视图一致性剪枝策略旨在去除那些对整体重建质量贡献较小的高斯基元,以进一步优化模型的效率和性能。这一策略同样基于多视图一致性原则,确保剪枝过程不会影响关键的视觉特征。具体而言,剪枝算法会评估每个高斯基元在不同视角下的表现,根据其对多视图渲染质量的贡献程度决定是否保留。通过这种方式,FastGS不仅能够有效减少不必要的高斯基元,还能保持高质量的渲染效果。
五、Compact Box
为了进一步提高光栅化效率,FastGS引入了紧凑框(CB)技术。这项技术通过对高斯基元的空间分布进行优化,使得渲染过程中能够更快速地访问和处理相关数据。CB技术通过将高斯基元分组并存储在一个紧凑的数据结构中,减少了渲染时的内存访问次数,从而加快了渲染速度。此外,CB技术还支持动态更新,允许在训练过程中根据需要调整高斯基元的分布,确保模型的持续优化。
六、实验
FastGS的性能在多个数据集上进行了广泛的测试,包括Mip-NeRF 360、Tanks & Temples和Deep Blending。实验结果表明,FastGS在训练速度和渲染质量方面均表现出色。特别是在Mip-NeRF 360数据集上,FastGS比DashGaussian快3.32倍;在Deep Blending数据集上,FastGS比基础3DGS快15.45倍。此外,FastGS在动态场景重建、表面重建、稀疏视图重建、大规模重建及同步定位建图等任务中也展现了强大的通用性和显著的加速效果。
七、FastGS的通用性
FastGS不仅在特定数据集上表现出色,还具有广泛的适用性。其实验验证了FastGS在多种任务中的强大通用性,包括但不限于动态场景重建、表面重建、稀疏视图重建、大规模重建及同步定位建图等。在这些任务中,FastGS的训练加速比达到了2-7倍,显示了其在不同应用场景中的高效性和灵活性。



当值较高时(超出预设阈值 \( \tau^+ \)),这表明该高斯持续出现在多个视图的高误差区域,因此可作为密集化处理的候选对象。值得注意的是,我们能够通过渲染过程的前向传播直接高效地确定二维足迹内高误差像素的数量。
四、多视图一致性剪枝
传统3DGS方法[17]虽然能排除透明度过低或尺寸过大的高斯,但在处理冗余问题上效果不佳。最近提出的剪枝策略[1,7,8]也存在不足,不仅未能解决冗余问题,还可能导致渲染质量显著下降。这些方法均未利用多视图一致性来判断高斯基元是否冗余。例如,在图3c中,Speedy-Splat[12]通过累加所有训练视图中与高斯相关的海森矩阵近似值来计算剪枝分数,而不是直接评估每个高斯对多视图渲染质量的实际贡献。这种间接依赖多视图一致性的方法往往导致渲染质量下降,如图3c右侧所示。为了彻底去除冗余的高斯分布,我们提出了一种基于多视图一致性的新剪枝策略——VCP。图3a展示了该方法如何类似于VCD,通过评估每个高斯分布对多视图重建质量的影响来计算分数。图3a右侧显示,VCP 能够在保持渲染质量的同时有效地移除大量的冗余高斯基元。
具体来说,对于每个视图 \( v^j \in V \),我们计算渲染图像 \( r^j \) 与相应的真实图像 \( g^j \) 之间的光度损失:
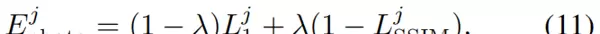
由于光度损失能够可靠地反映重建的保真度,我们将它与公式(10)结合起来,以得出每个高斯基元 \( G_i \) 的剪枝分数:
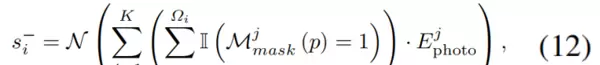
其中,\( N(\cdot) \) 表示最小-最大归一化函数。\( s_i \) 可视为高斯基元 \( G_i \) 对整体渲染质量影响的量化指标。当其超过预设阈值 \( \tau \) 时,意味着该高斯基元对多视角渲染质量的贡献较小,应被剪枝。
五、紧凑盒
在光栅化预处理阶段,标准3DGS算法使用3-sigma规则生成二维椭圆,但这种方法会生成大量高斯-tiles对,导致计算冗余并降低渲染效率。Speedy-Splat算法通过精确计算tiles的交集部分解决了这个问题,但我们发现某些2DGS对特定tile像素的影响仍然很小。为了进一步减少冗余配对,我们提出了紧凑盒算法,通过计算高斯中心的马氏距离,剔除贡献度最低的高斯-tiles对,从而在保持渲染质量的同时提高效率。
实验
数据集
与标准3DGS相同,我们在三个现实世界数据集上进行了实验:Mip-NeRF 360、Deep-Blending 和 Tanks & Temples。对于其他具有挑战性的任务,我们在D-NeRF、NeRF-DS 和 Neu3D 数据集上评估了动态场景重建。Tanks & Temples、LLFF、BungeeNeRF 和 Replica 分别用于表面重建、稀疏视图重建、大规模重建和SLAM。
评估指标
为了评估性能,我们使用PSNR、SSIM和LPIPS等常见指标来衡量新视图的渲染质量。此外,通过总训练时间(分钟)、最终高斯点数量和渲染速度(帧率)等指标,评估模型的训练效率和紧凑性。
具体实现
所有方法均采用Adam优化器[20]进行30,000次迭代训练。在实验中,我们统一设置了 \( K = 10 \) 和 \( \lambda = 0.2 \)。在基础配置下,每500次迭代执行一次数据密集化处理,直到第15,000次迭代。为确保实验的公平性,所有测试均在NVIDIA RTX 4090显卡上完成,对比方法均使用官方代码实现。FastGS的默认配置为3DGSaccel[17,25],包括我们提出的VCD、VCP和CB三种加速方案。为了实现极致的训练加速,我们的方法在渲染质量上并非最优。为此,我们推出了FastGS Big版本,该版本通过将数据密集化处理频率提升至每100次迭代一次,同时保持最高的渲染质量和最快的训练速度。
如表1所示,FastGS在保持渲染质量相当的情况下实现了最快的训练速度。平均场景训练耗时100秒,最快案例仅需77秒。Speedy-Splat[12]在剪枝过程中未能充分考虑多视图一致性,导致渲染质量显著下降。Taming3DGS[25]采用较弱的多视图一致性约束,导致高斯点过度增长且训练速度减慢。当前SOTA算法DashGaussian[4]虽然实现了高渲染质量,但缺乏有效的冗余高斯点剪枝策略,场景优化后仍保留数百万个高斯点,限制了训练速度。相比之下,我们的改进方案FastGS-Big在渲染质量上比DashGaussian[4]提升了超过0.2分贝,训练时间缩短了43.7%以上,高斯点数量减少了超过一半。
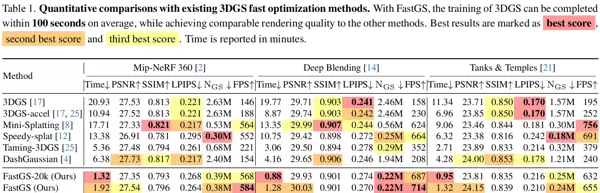
图4展示了表1的结果,其改进版本FastGS-Big在多视图一致性约束下,能够更准确地重建场景,几何结构的还原度也更高。

FastGS的通用性
基准模型:Deformable-3DGS、PGSR、DropGaussian、OctreeGS和photo-SLAM。
这些方法分别被用作动态场景重建、表面重建、稀疏视图重建、大规模重建和光图SLAM的主要架构。
通过增强主干网络,此方法因其框架设计的简洁性,能够轻松地适应其他3DGS主干网络,同时支持不同的优化器、表示基元或额外的过滤器。根据表2的数据,我们的方法在不牺牲渲染质量的情况下,能够将训练速度提高2至14倍,平均减少了77.46%的高斯数量。这一结果表明了该方法的广泛适用性,我们认为这主要归功于多视角一致性作为3D重建任务的核心要素。
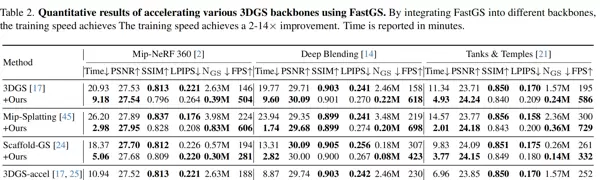
为了进一步验证其在多种任务中的优化能力,我们还测试了将多种最先进(SOTA)的方法与本框架相结合的应用效果。表3和表4显示,当保持相同的渲染质量时,所有基准方法的训练速度都提高了2到7倍。图5展示了一些实验的结果,这些显著的提升再次证明了我们方法的广泛适用性。我们认为,这种优势来源于多视角一致性特征,这是各种重建任务的基础。更多的实验数据可以在补充材料中找到,相关的代码也将对外公开。


#pic_center =60%x80%
\( d \sqrt{d} d \)
\( ? 1 8 \frac {1}{8} 8 1 ? \)
\( \bar{x} \bar{x} \hat{D} \hat{D} \tilde{I} \tilde{I} ? \epsilon ? ? \phi ? \prod \prod \)
\( a b c \sqrt{abc} ab c ? \)
\( \sum{abc} \sum ab c / \)
\( E \mathcal{E} E \)


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





