初次接触 RAG(Retrieval-Augmented Generation)的用户,常遇到相似的问题:即使将200页的PDF、多个Markdown文件或整套API文档导入向量数据库,提问时模型的回答也可能偏离实际。例如:
- 询问“支付回调接口在哪里?”得到的回答可能是“应该在用户模块下。”
- 关于“合同审批流程?”的回答则可能是“这取决于你的项目架构。”
这些“含糊其辞”的答案容易让人质疑RAG的有效性。实际上,问题的关键在于向量编码(Embedding)未能准确理解文档内容。
一、RAG 不准的原因:模型在“投影”而非“理解”
在一个实际案例中,某智能客服团队将全部FAQ文档上传至向量数据库,尽管数据库容量达到500MB,但用户询问“如何修改绑定手机号”时仍无法获得正确答案。这是因为:
向量编码不是搜索引擎的理解工具,而是将文本转换为数学向量的过程,通过向量间的距离来表示语义相关性。
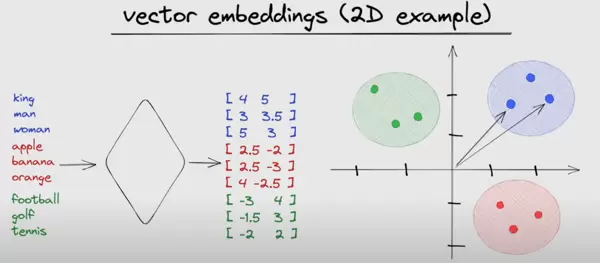
二、向量编码的本质:语义到多维空间的映射
向量编码的核心在于将文本转换成数字序列,使这些数字能够反映文本之间的语义关系。这一过程更像是在高维空间中进行三维行为的模拟,而非真正‘理解’文本内容。
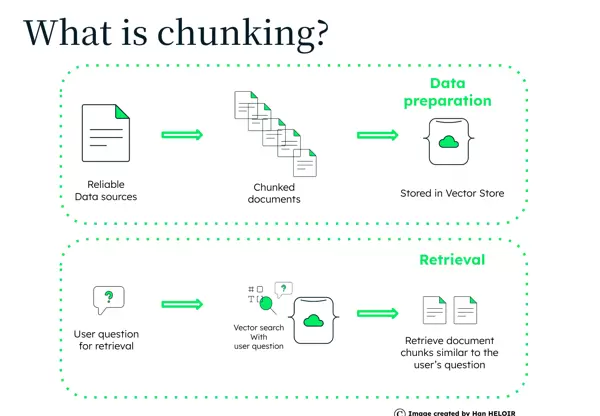
三、文档检索不准确的原因:Chunk 大小影响语义单元
文档的分割方式直接影响检索效果。过大或过小的Chunk都会导致向量表示的不准确,进而影响搜索结果。理想的Chunk大小应能保持内容的连贯性和完整性。
四、向量编码模型的“世界观”限制了RAG的准确性
向量编码模型基于特定的数据集训练,这意味着它对于特定领域的专业术语或私有业务知识可能缺乏理解能力。例如,在搜索“供应商结算流程”时,可能会误召回“供应链库存日报”。
五、实践探索:通过实验了解向量空间的局限性
为了更好地理解向量编码的局限性,可以通过一个简单的实验来观察不同文本在向量空间中的距离变化。实验步骤包括:
- 安装必要的软件包。
- 准备两段看似无关的文本。
- 生成向量并计算两者之间的距离。
- 观察结果,分析为什么某些看似相关的内容在向量空间中距离较远。
pip install openai numpy
text_a = "供应商结算流程包括数据回填、签章、审批和对账。"
text_b = "供应链库存日报由仓储中心负责整理。"
text_c = "绑定手机号可以在设置中心修改。"
from openai import OpenAI
import numpy as np
client = OpenAI()
def embed(t):
return client.embeddings.create(
model="text-embedding-3-large",
input=t
).data[0].embedding
# 生成向量
a, b, c = embed(text_a), embed(text_b), embed(text_c)
def cosine(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
print("A vs B:", cosine(a, b))
print("A vs C:", cosine(a, c))
A vs B > A vs C
六、提升RAG准确性的关键:向量空间的协同优化
要提高RAG系统的性能,重点不在于扩大数据库规模,而在于优化向量空间,使其更加贴合业务需求。这涉及到对向量编码模型的精细调优,以及对文档分割策略的合理设计。
六条黄金法则
(行业经验总结):
-
颗粒度划分应考虑语义,而非单纯依据字数
例如:
- API 文档中的头部和方法描述应当作为一个整体处理
- 当一个段落横跨两个小节时,应在适当处断开
- 法务条款不可随意分割,以免破坏其语义连贯性
建议采用:
语义分段与固定长度相结合的方法
-
选择符合业务背景的 Embedding 模型(如 bge-m3、gte 或商业嵌入模型)
业务背景越贴合,语义空间的表示就越接近实际情况。
-
实施再排序(二次召回)以提高相关性
这一步骤通常能够将 RAG 的准确率从 60% 提高至 90% 以上。
-
为长文档建立“父子向量结构”(parent-child RAG)
防止因分割而导致的语义断裂。
-
对专业术语进行“词汇表增强”(Term Expansion)
例如,“结算流程”可以扩展为:
- 账单审核
- 发票比对
- 付款条款
- 对账时间段
这样可以使搜索结果更加贴近业务场景。
-
采用混合搜索(BM25 + 向量搜索)以应对词汇不在词汇表中(OOV)及稀疏数据的问题
单纯的向量匹配存在局限,而混合搜索则能有效补充这些不足。
meme 时间

结语:提升维度——Embedding 并非“知识存储器”,而是“认知地图”
如果将大型模型比作大脑,那么:
- Embedding 就相当于神经元间的距离图
- Chunking 则是你选择以何种视角观察世界
- Retrieval 是在地图上寻找路径的行为
当这张地图未能准确反映你的业务环境时,无论 RAG 如何调整都无法达到预期效果。
理解 Embedding 的核心,你将意识到:
RAG 的关键不在于堆积文档,而在于构建一个与你的业务相匹配的语义空间。
若你在开发企业级知识库、AI 辅助工具或复杂的业务流程搜索系统,欢迎留言交流,共同探讨更深入的 RAG 优化方案。
——全文结束——


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





