经管之家App
让优质教育人人可得
立即打开


大家好!我是大聪明-PLUS!
在本文中,我将分享我们为管理 Linux 网络子系统所开发的 C++ 封装程序。该程序基于 Netlink 协议,并使用 libnl3 库实现,在某些场景下显著提升了配置效率。同时,我会解释为何我们最终放弃了传统的系统调用方式,并展示相关的性能基准测试数据。

在早期项目中,我们依赖一个自定义的 exec 函数来处理网络接口、邻居表项、路由等操作。其函数原型如下:
int exec(const std::string& cmd, std::string& result);
该函数接收一条 bash 命令作为输入,并通过调用 iproute2 工具包完成实际的网络配置任务。
底层使用的是 popen 函数,它会触发一系列系统调用流程:
pipe()fork()exec()随后,该函数会等待子进程结束并关闭 I/O 流,最终根据返回码确定执行结果。
pclose整个过程的成败可通过返回值判断。
exec例如,我们可以通过传递如下命令来创建一个网络桥接设备:
ip link add Bridge type bridge“ip link add br0 type bridge && ip link set br0 up”
命令执行后的输出会被存储在 result 参数中。
值得一提的是,我们选择使用标准的 Linux 网络协议栈来处理业务流量。虽然市面上存在诸如 DPDK 和 BPF 等高性能替代方案,但由于我们需要支持多种复杂协议,原生协议栈仍是更合适的选择。
尽管使用 exec 实现功能非常便捷,尤其在 MVP 阶段能快速迭代,但随着系统规模扩大,我们逐渐意识到这种方法存在多个问题,最终决定弃用:
每次调用都会引发完整的进程创建、上下文切换、bash 解析以及 Netlink 套接字初始化,开销较大。
虽然可以通过 “&&” 连接多个命令,避免频繁调用 iproute2,但这种拼接式写法破坏了代码结构,难以阅读和维护。
当一组链式命令中某一步失败时,无法准确判断是哪一个具体命令导致了错误,日志信息模糊。
由于直接依赖系统命令,难以对网络行为进行模拟,单元测试受限。后期我们引入了一个名为 “wet” 的辅助函数,用于验证传给 exec 的命令是否产生预期输出,但这仍属于黑盒测试,覆盖有限且不够稳定。
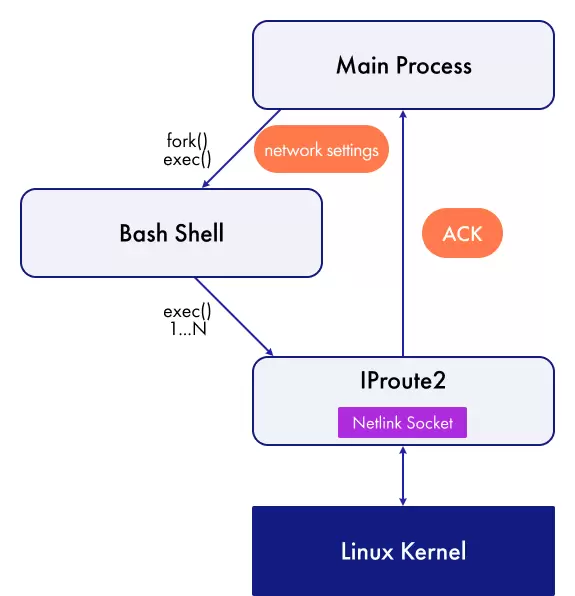
我们现在采用基于 libnl3 的 C++ 封装层,直接通过 Netlink 与内核通信,绕过 shell 和用户态工具。以下是一个旧版本使用 exec 创建和配置 Dot1Q 桥接的示例:
const std::string cmds = std::string("")
+ BASH_CMD + " -c \""
+ IP_CMD + " link add " + DOT1Q_BRIDGE_NAME + " up type bridge && "
+ IP_CMD + " link set " + DOT1Q_BRIDGE_NAME + " mtu " + DOT1Q_BRIDGE_DEFAULT_MTU_STR + " && "
+ IP_CMD + " link set " + DOT1Q_BRIDGE_NAME + " address " + gMacAddress.to_string() + " && "
+ IP_CMD + " link set " + DOT1Q_BRIDGE_NAME + " type bridge vlan_filtering 1 && "
+ IP_CMD + " link set " + DOT1Q_BRIDGE_NAME + " type bridge vlan_default_pvid 0 &&"
+ IP_CMD + " link set " + DOT1Q_BRIDGE_NAME + " type bridge no_linklocal_learn 1";
std::string res;
int err = exec(cmds, res);
if (err)
…
再看另一个获取路由信息的例子:
std::string res;
std::string cmd = "ip route get " + ipAddrStr + vrfName + " | sed -n 's/.*dev \\([^\\ ]*\\).*/\\1/p' | tr -d '\n'";
int ret = exec(cmd, res);
这段代码的作用是:利用 ip route get 查询指定 IP 地址和 VRF 对应的出接口名称。
sed文章后续部分将展示如何使用我设计的新封装器以更高效、安全的方式完成相同操作。
我们分析了现有的解决方案,但未能找到一个符合我们需求的 C++ 封装库:部分库功能受限,难以满足实际使用场景;另一些虽然提供了底层 Netlink API 的访问能力,却大大增加了开发复杂度。最终,我们决定不依赖外部工具调用,而是着手构建一套自主的网络子系统管理库。 新方法的核心在于实现用户空间进程与 Linux 内核之间的直接通信。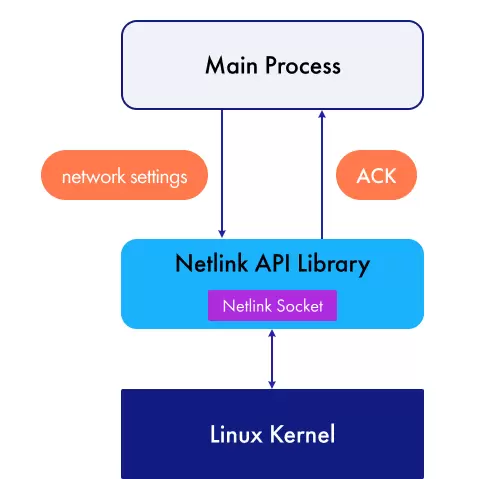 上图展示了如何通过封装 Netlink API 来操作网络子系统。
在项目中,我们广泛采用了 libnl3 库来监听由内核触发的网络配置变更事件。该库提供了一套基于 Netlink 协议的接口,用于与 Linux 内核进行交互。Netlink 作为一种进程间通信(IPC)机制,主要用于连接内核空间和用户空间的进程。它被设计为 ioctl 的更灵活替代方案,广泛应用于内核网络子系统的配置与监控。
尽管 libnl3 被普遍用于处理 Linux 网络协议栈相关任务,但直接在其基础上开发仍存在若干问题:首先,对于仅具备基础网络知识的开发者而言,掌握其使用方式耗时且困难;其次,该库的设计并不适合在高级代码结构中高效集成,也无法支持我们所需的测试策略——即通过对 Linux 行为进行模拟来完成单元测试。
然而,libnl3 的一大优势在于其提供的高级 Netlink 接口,能够自动处理套接字通信和 Netlink 消息的封装与解析,无需开发者手动干预。这使得它成为我们实现 C++ 包装器内部逻辑的理想选择。
为了达成目标,我们选用了 libnl3 套件中的两个核心组件:**libnl-core** 和 **libnl-route**。前者负责 Netlink 套接字的管理、消息的生成与解析;后者则提供了表示各类网络实体的数据结构,以及配置和应用这些配置到系统的函数集合。
以 `rtnl_link` 结构体为例,它是 libnl-route 中用于管理网络接口的关键数据类型。我们可以通过 set 方法设置其属性,例如:
上图展示了如何通过封装 Netlink API 来操作网络子系统。
在项目中,我们广泛采用了 libnl3 库来监听由内核触发的网络配置变更事件。该库提供了一套基于 Netlink 协议的接口,用于与 Linux 内核进行交互。Netlink 作为一种进程间通信(IPC)机制,主要用于连接内核空间和用户空间的进程。它被设计为 ioctl 的更灵活替代方案,广泛应用于内核网络子系统的配置与监控。
尽管 libnl3 被普遍用于处理 Linux 网络协议栈相关任务,但直接在其基础上开发仍存在若干问题:首先,对于仅具备基础网络知识的开发者而言,掌握其使用方式耗时且困难;其次,该库的设计并不适合在高级代码结构中高效集成,也无法支持我们所需的测试策略——即通过对 Linux 行为进行模拟来完成单元测试。
然而,libnl3 的一大优势在于其提供的高级 Netlink 接口,能够自动处理套接字通信和 Netlink 消息的封装与解析,无需开发者手动干预。这使得它成为我们实现 C++ 包装器内部逻辑的理想选择。
为了达成目标,我们选用了 libnl3 套件中的两个核心组件:**libnl-core** 和 **libnl-route**。前者负责 Netlink 套接字的管理、消息的生成与解析;后者则提供了表示各类网络实体的数据结构,以及配置和应用这些配置到系统的函数集合。
以 `rtnl_link` 结构体为例,它是 libnl-route 中用于管理网络接口的关键数据类型。我们可以通过 set 方法设置其属性,例如:
rtnl_link_set_mturtnl_link_set_masterexeciproute2ipbridgeadddelsetget
class NetlinkFactory {
public:
std::shared_ptr<ILinkNetlink> createLinkNetlink() override;
std::shared_ptr<IRouteNetlink> createRouteNetlink() override;
...
private:
std::shared_ptr<ILinkNetlink> m_linkNetlink;
std::shared_ptr<IRouteNetlink> m_routeNetlink;
...
std::unordered_map<int, std::shared_ptr<nl_sock>> m_producerSocketMap;
};
本项目所开发的库主要用于实现对 Linux Netlink 接口的高层封装,其典型使用流程如下:
在网络服务启动初始化阶段,系统会构建一个工厂实例。通过该工厂,能够生成用于与 Netlink 子系统交互的各类包装器对象。这些包装器被用于订阅 Redis 数据库中的配置变更以及内核空间的网络事件。一旦检测到核心信息更新或配置表发生变动,相应的回调处理函数将被触发,并利用 Netlink API 包装器执行具体操作。
举例来说,当用户通过命令行工具修改某个网络接口的管理状态时,这一操作会引发 Redis 中相关数据的变化。由于网络服务已对该类变化进行了监听,因此会立即调用对应的处理逻辑。该逻辑借助 Netlink 封装接口在操作系统内完成实际的状态设置,随后再将此变更传递至下游服务,最终将端口的管理状态同步至 ASIC 交换芯片中。
sudo unshare --net build/tests/kfnetlink_tests --gtest_output=xml:junit-report.xml
class IpMgrTest : public ::testing::Test
{
std::unique_ptr<IpMgr> m_ipMgr;
std::shared_ptr<MockAddrNetlink> m_mockAddrNetlink;
...
IpMgrTest()
: m_mockAddrNetlink(std::make_shared<StrictMock<MockAddrNetlink>>())
, m_ipMgr(std::make_unique<IpMgr>(m_mockAddrNetlink))
{}
};
TEST_F(IntfTest, AddIPv6)
{
auto addrInfo = AddrInfo("Ethernet1", "2001:db8:85a3::a2e:3:34/64")
.setFamily(AF_INET6);
EXPECT_CALL(*m_mockAddrNetlink, add(addrInfo))
.Times(1)
.WillOnce(Return(NLE_SUCCESS));
...
ASSERT_TRUE(m_ipMgr->addIpAddress("Ethernet1", "2001:db8:85a3::a2e:3:34/64"));
}
LinkInfo bridgeLinkInfo(DOT1Q_BRIDGE_NAME, "bridge");
int err = m_linkNetlink->add(bridgeLinkInfo);
if (err)
...
bridgeLinkInfo.setAdmin(true)
.setLinkLayerAddr(macAddress)
.setMtu(DOT1Q_BRIDGE_DEFAULT_MTU)
.setBridgeVlanFiltering(true)
.setBridgeVlanDefaultPvid(0)
.setBridgeLinkLocalLearn(false);
err = m_linkNetlink->set(bridgeLinkInfo);
if (err)
...
可以看出,新版本代码更为简洁清晰。对于最终使用者而言,他们面对的是一个结构良好、语义明确的高级控制接口,完全无需了解底层 Netlink 协议的具体细节即可完成复杂操作。获取内核信息的过程十分直接。只需将所需键值填充到对应结构体中,调用 get 方法,便可得到一个包含目标内核信息的对象作为返回结果。然而,并非所有字段都支持写入操作,因此在尝试读取属性前,必须先判断该字段是否存在,例如可通过以下方式实现:
has_valueLinkInfo linkInfo("Ethernet1");
int err = m_linkNetlink->get(linkInfo);
if (err)
...
if (linkInfo.isAdminUp.has_value() && linkInfo.isAdminUp.value())
{
std::cout << "Ethernet1 is UP" << std::endl;
}
为了评估所构建封装器的实际性能表现,我们将对其执行时间进行基准测试,并与基于 libnl3 编写的函数以及 iproute2 工具中采用 C 语言实现的原始 Netlink 调用方式进行对比。同时,我们还将展示一个简单的网络场景示例——创建虚拟接口。
execstd::system需要注意的是,exec 和 system 函数无需额外对象即可直接调用。而针对原始 Netlink 操作、基于 libnl3 的实现以及我们自定义的包装器,都会分别设计专用类来管理资源。这些类的核心优势在于避免了每次调用时重复创建套接字和相关对象,从而提升效率。
整个基准测试流程包括执行待测函数并随后将系统配置恢复至初始状态,但仅记录函数执行阶段的时间开销,回滚过程不计入测量范围。
下面的代码片段演示了如何使用 libnl3 构建一个用于管理虚拟接口的类。其中,套接字在构造函数中完成一次初始化,后续所有方法均复用该连接:
class LibnlDummyManager
{
using LinkPtr = std::unique_ptr<rtnl_link, decltype(&rtnl_link_put)>;
using SocketPtr = std::unique_ptr<nl_sock, decltype(&nl_socket_free)>;
public:
LibnlDummyManager() : m_socket(nl_socket_alloc(), nl_socket_free)
{
if (!m_socket)
throw std::runtime_error("Failed to allocate memory to Netlink socket");
if (int err = nl_connect(m_socket.get(), NETLINK_ROUTE); err)
throw std::runtime_error("Failed to connect Netlink socket: " + std::string(nl_geterror(err)));
}
int createDummy(const std::string& dummyName)
{
LinkPtr linkPtr(rtnl_link_alloc(), rtnl_link_put);
rtnl_link_set_name(linkPtr.get(), dummyName);
rtnl_link_set_type(linkPtr.get(), "dummy");
return rtnl_link_add(m_socket.get(), linkPtr.get(), NLM_F_REQUEST | NLM_F_CREATE | NLM_F_EXCL | NLM_F_ACK);
}
int setDummyUp(const std::string& dummyName)
{
LinkPtr oldLinkPtr(rtnl_link_alloc(), rtnl_link_put);
LinkPtr newLinkPtr(rtnl_link_alloc(), rtnl_link_put);
rtnl_link_set_name(oldLinkPtr.get(), dummyName.c_str());
rtnl_link_set_name(newLinkPtr.get(), dummyName.c_str());
rtnl_link_set_flags(newLinkPtr.get(), IFF_UP);
return rtnl_link_change(m_socket.get(), oldLinkPtr.get(), newLinkPtr.get(), 0);
}
private:
SocketPtr m_socket;
};
WrapperDummyManager 类的设计思路与之相似,但在其基础上引入了更高层次的抽象——即利用我们开发的 Netlink 包装器。该类的构造函数接收一个由工厂预先创建好的 Netlink 包装器实例,确保资源管理的一致性与高效性。
class WrapperDummyManager
{
public:
WrapperDummyManager(std::shared_ptr<ILinkNetlink> linkNetlink)
: m_linkNetlink(linkNetlink)
{
}
int createDummy(const std::string& dummyName)
{
return m_linkNetlink->add(kfnl::LinkInfo(dummyName, "dummy"));
}
int setDummyUp(const std::string& dummyName)
{
return m_linkNetlink->set(kfnl::LinkInfo(dummyName).setAdmin(true));
}
private:
std::shared_ptr<ILinkNetlink> m_linkNetlink;
};
为了评估函数执行性能,我们采用了 Google Benchmark 框架进行测试。实验环境为一台搭载 Intel Core i5-1235U 处理器、运行 Ubuntu 22.04 系统的设备,具体配置如下:
std::system在未启用编译优化的情况下,各方法创建虚拟接口的时间表现如下:
| 基准方式 | 时间 | CPU 时间 | 迭代次数 |
|---|---|---|---|
| 执行官 | 1592 ns | 102 ns | 7438 |
| std::system | 1552 ns | 73.3 ns | 9222 |
| C++ 封装器 | 186 ns | 185 ns | 3812 |
| libnl3 | 168 ns | 167 ns | 3854 |
| 原始 Netlink | 152 ns | 151 ns | 4759 |
对于开启虚拟接口操作的性能测量结果如下:
| 基准方式 | 时间 | CPU 时间 | 迭代次数 |
|---|---|---|---|
| 执行官 | 1228 ns | 70.3 ns | 9639 |
| std::system | 1210 ns | 52.4 ns | 12827 |
| C++ 封装器 | 63.2 ns | 61.6 ns | 11277 |
| libnl3 | 46.0 ns | 44.0 ns | 16314 |
| 原始 Netlink | 36.1 ns | 34.6 ns | 19284 |
exec从数据可以看出,多种实现方式的执行时间较为接近。其中,基于原始 Netlink 的实现最快;使用 libnl3 的方案稍慢,延迟高出约 10–16 微秒。而我们的 C++ 封装函数性能略低,在此基础上再增加约 17–18 微秒的开销。这部分额外消耗主要来源于抽象层的设计、调用链的延长以及增强的可维护性和可测试性所带来的结构性代价。
当我们启用 O2 编译优化后,重新对库及测试代码进行编译,性能差距显著缩小。此时,C++ 封装器与直接使用 libnl3 的性能差异已几乎可以忽略。考虑到项目本身正是构建于该优化等级之上,这意味着采用 C++ 封装函数替代底层 Netlink 或 libnl3 调用不仅有效解决了开发中的诸多问题,同时并未带来明显的性能损失。
以下是开启 O2 优化后的最新测试数据:
| 基准方式 | 时间 | CPU 时间 | 迭代次数 |
|---|---|---|---|
| 执行官 | 1502 ns | 88.7 ns | 7839 |
| std::system | 1490 ns | 70.2 ns | 10324 |
| C++ 封装器 | 156 ns | 155 ns | 4397 |
| libnl3 | 154 ns | 154 ns | 4531 |
| 原始 Netlink | 144 ns | 143 ns | 5105 |
exec与通过 std::system 调用外部命令的方式相比,封装后的 C++ 接口展现出显著更高的效率——无论是否开启优化:
std::systemNetlink 是 Linux 平台上一种现代化且高效的网络配置机制。相较于传统的系统调用方式,直接通过 Netlink API 与内核通信能够将操作延迟降低一个数量级,极大提升响应速度。
然而,直接使用 Netlink 或 libnl3 等底层库往往复杂且易出错,开发成本较高。为此,引入适当的封装层显得尤为重要。良好的封装不仅能提升代码质量、可读性和单元测试能力,还能让开发者更专注于业务逻辑本身,而不必深陷于协议细节之中。
实践表明,合理设计的 C++ 包装器在保持高性能的同时,提供了更安全、更简洁的接口,是现代网络工具开发中的理想选择。
欢迎在评论区提出您的疑问,我将乐意为您解答。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




