引言
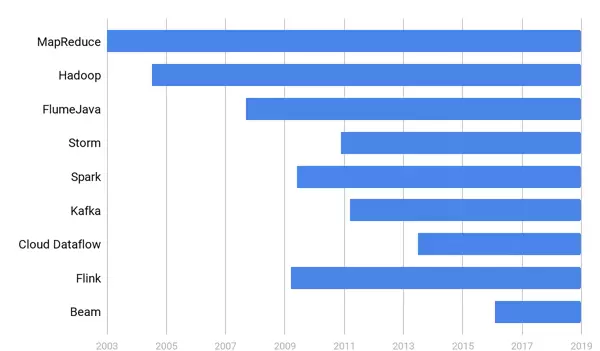
随着互联网与科技行业的迅猛发展,数据量正以指数级速度增长。如何高效、稳定地完成大规模数据的处理、分析与价值挖掘,已成为决定企业创新能力与市场竞争力的关键技术瓶颈。MapReduce 曾作为大数据处理领域的里程碑式解决方案,被广泛应用于各类场景。然而近年来,包括 Google 在内的多家硅谷头部企业已逐步停用 MapReduce,转而采用更先进的框架(如 FlumeJava 及其开源版本 Apache Beam)。本文将系统梳理大规模数据处理技术的演进路径,回顾 MapReduce 的历史贡献,深入解析其被淘汰的技术动因,并展望未来数据处理的发展方向,为开发者与研究人员提供具有实践参考价值的一线洞察。

一、技术演进:大规模数据处理的三大阶段
1. 石器时代 —— MapReduce 出现前的无序探索期
在 2003 年之前,尽管像 Google 这样的公司已经面临海量数据处理需求——例如每日数十亿次搜索请求的日志分析——但行业内缺乏统一的数据处理范式。各组织往往自行设计工具和流程,导致开发重复、维护困难、系统不可复用,整体处于高度分散与低效的状态。
2. 青铜时代 —— MapReduce 带来的标准化革命
2003 年,Google 发表《MapReduce: Simplified Data Processing on Large Clusters》论文,由 Jeff Dean 与 Sanjay Ghemawat 提出“Map-Reduce”编程模型,首次实现了对分布式计算逻辑的高度抽象。这一模型迅速成为行业标准,催生了 Hadoop 生态系统的兴起,其中融合了 GFS、BigTable 和 MapReduce 三大核心技术理念。该时期,MapReduce 成为超大规模批处理的事实标准,极大推动了数据工程、机器学习和商业智能等领域的基础设施建设。

3. 蒸汽机时代 —— FlumeJava 与 Apache Beam 开启统一处理新纪元
到了 2014 年,Google 内部已基本停止新增 MapReduce 作业。自 2016 年起,新员工培训中全面采用 FlumeJava(注意:非 Apache Flume,而是 Google 内部专用框架)替代传统 MapReduce 编程教学,标志着其正式进入新一代数据处理范式。作为 FlumeJava 的开源延续,Apache Beam 实现了批处理与流处理 API 的统一建模,显著提升了代码可复用性、系统可维护性以及跨执行引擎的兼容能力,引领了现代数据流水线架构的设计潮流。
二、MapReduce 为何被弃用?深度技术剖析与真实案例解读
1. 维护成本过高 —— 工程复杂度失控
虽然 MapReduce 的理论模型简洁明了,但在实际业务中却极易引发工程复杂性爆炸。以一个典型应用场景为例:
假设某机构希望通过视觉识别手段评估美团股价走势,其中一个关键指标是城市街头活跃的美团外卖电动车数量。为此需处理海量图像数据,在真实生产环境中,通常需要串联超过十个独立的 MapReduce 任务,包括:
- 数据导入(从多个源系统归集并下载原始文件)
- 格式标准化(统一不同来源的图片元信息)
- 压缩优化(降低存储开销)
- 备份机制(防止数据丢失)
- 质量检测(筛选有效图像,排除模糊或时间错误项)
- 结构化处理(人工标注或自动识别车辆特征)
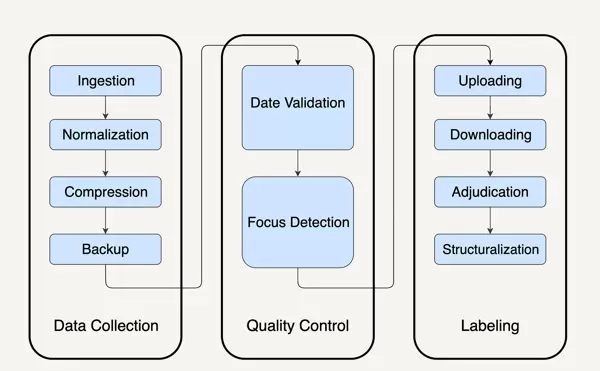
每个环节都涉及复杂的分布式异常处理、状态同步、容错重试机制,开发与运维团队深陷于流程控制、错误追踪和资源协调之中,完全背离了“简单易用”的初衷。许多团队不得不引入额外的工作流调度系统(如 Airflow 或 Oozie),进一步增加系统耦合度与故障风险,导致上线周期拉长,维护负担急剧上升。
2. 性能难以满足预期 —— 调优门槛极高
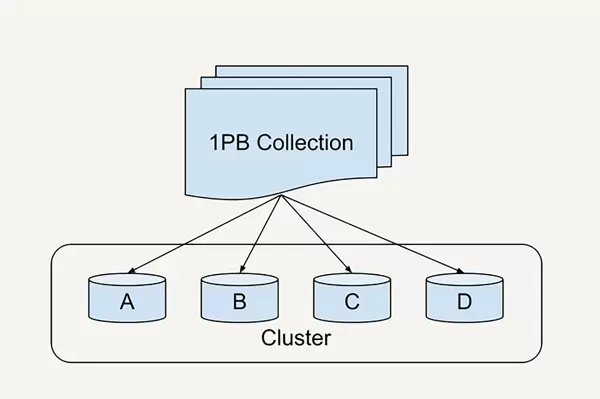
MapReduce 对性能调优的要求极为严苛,涉及分片策略(sharding)、缓冲区设置、预读机制、内存缓存等多个底层参数。即便是 Google 这类顶尖企业,也经历了漫长优化过程:在 1PB 数据排序任务中,耗时从 2007 年的 12 小时缩短至 2012 年的仅 0.5 小时,历时五年,依赖大量专家经验与动态分片技术创新才勉强跟上业务增长节奏。[1]
对于普通开发者而言,掌握如此复杂的调优体系几乎不可能。常见的“掉队者问题”(stragglers)频发——个别 worker 因分配数据过多而长时间未完成,拖累整个作业进度。若分片不合理,还会引发数据倾斜、节点负载失衡等问题,严重影响系统吞吐量与稳定性。
3. 扩展性与统一性不足 —— 无法适应现代数据需求
随着实时分析、事件驱动架构和微批处理的普及,单一的批处理模型已无法满足多样化的业务诉求。MapReduce 缺乏对流式数据的原生支持,也无法实现批流接口的统一抽象。面对日益增长的多模态数据处理需求(如日志流、传感器数据、用户行为追踪),其架构显得僵化且扩展困难,最终被更具弹性和表达力的新一代框架所取代。
三、对比分析与行业实践案例
1. MapReduce 与 Spark 的核心差异
Spark 通过内存计算模型显著提升了迭代型任务的执行效率,尤其适用于机器学习、图计算等场景。相比 MapReduce 每步操作均需落盘的 I/O 开销,Spark 支持 DAG(有向无环图)执行计划,允许中间结果驻留内存,大幅减少延迟。此外,Spark 提供了更高层次的 API(如 DataFrame、SQL 接口),降低了开发门槛,增强了代码可读性与可测试性。
2. 数据分片策略的实际应用经验
合理的数据分片是保障系统性能的基础。实践中应避免静态分片带来的热点问题,推荐结合数据分布特征采用动态或哈希一致性分片策略。例如在用户行为分析系统中,按用户 ID 哈希分区可有效均衡负载;而在时间序列数据场景下,则宜采用范围+滚动窗口的方式进行切片管理,提升查询局部性与合并效率。
四、技术趋势与未来展望
1. 批处理与流处理的融合 —— Apache Beam 的数据流模型
Apache Beam 提出“编程模型与执行引擎分离”的设计理念,定义统一的 SDK 接口,可在不同后端(如 Flink、Spark Streaming、Google Cloud Dataflow)上运行。其核心优势在于支持事件时间(event time)、水位线(watermark)、窗口聚合等高级语义,真正实现批与流的逻辑统一,为构建端到端一致性的数据管道提供了坚实基础。
2. 面向可测试性、可观测性与工程扩展性的架构设计
未来的数据处理系统不仅追求高性能,更强调工程层面的可持续性。良好的模块化设计、清晰的状态管理、内置的监控埋点与告警机制,成为衡量系统成熟度的重要指标。同时,支持单元测试、集成测试与回放调试的能力,有助于提升开发效率与线上稳定性,推动数据平台向 DevOps 化方向演进。
结论
MapReduce 作为大数据时代的开创性技术,奠定了分布式计算的基础范式。然而受限于高维护成本、低性能弹性及缺乏统一编程模型等固有缺陷,已逐渐退出主流舞台。以 Apache Beam 为代表的新型框架,凭借批流一体、高可维护性和工程友好性,正在重塑现代数据处理体系。理解这一技术变迁脉络,不仅有助于把握当前最佳实践,也为应对未来复杂数据挑战提供了重要启示。
3. 扩展性与统一性局限 —— 新一代需求推动范式演进
随着“流式处理(streaming)”与“批处理(batch)”场景的深度融合,传统MapReduce架构在编程接口设计、任务调度机制以及监控体系方面逐渐暴露不足。为应对这一挑战,FlumeJava及Apache Beam等框架提出了统一的数据处理范式,能够无缝支持从单条记录到海量数据的处理规模,有效简化开发接口,提升测试效率与系统可观测性,从而驱动整个数据处理模型向更高层次的系统化升级。
三、对比分析与行业应用实例
1. MapReduce 与 Spark 的核心差异
复杂度方面:MapReduce在多阶段任务执行中频繁依赖磁盘读写,流程割裂严重,导致运维负担加重;而Spark通过DAG(有向无环图)结构对计算流程进行建模,利用链式RDD操作实现高效串联,显著降低了开发与维护的复杂度。
性能表现:Spark优先采用内存计算模式,减少I/O开销,而MapReduce主要基于磁盘IO,两者在执行效率上存在明显差距。
数据倾斜应对能力:Spark 3.0引入了动态分片机制与倾斜partition自动调整策略,极大增强了负载均衡能力和系统的自动化水平。
2. 数据分片策略的实际应用
在Facebook等大型平台处理用户行为数据时,分片函数的设计直接关系到数据分布的均匀性与系统的容错能力:
- 哈希分片(hash-based):实现简单且利于负载均衡,但在节点增减时需大规模重分配数据。
- 一致性哈希环(含虚拟节点):适用于高可用分布式环境,具备良好的伸缩性,但实现逻辑较为复杂。
- 动态采样与分区合并/拆分:针对未知数据分布场景效果显著,但技术实现门槛较高。
- Round Robin 分片:分配机制简洁,但缺乏容错机制,任务恢复能力较弱。
实践中推荐结合关键字段(如用户ID、注册时间等)进行合理采样,并融合动态分片机制、自动识别与优化数据倾斜的技术方案,以支撑超大规模数据工程的稳定运行。
四、技术发展方向与未来展望
1. 批处理与流处理的融合趋势 —— Apache Beam 数据流模型
早期批处理(有限数据集)与流处理(无限数据集)分别依赖不同技术栈。然而,随着实时分析、数据湖架构等应用场景的普及,构建统一的编程模型已成为必然选择。Apache Beam以“Dataflow Model”为核心理念,兼容Spark、Flink、Google Dataflow等多种执行引擎,既能高效完成批处理任务,也能优雅支持流式数据处理,大幅降低跨平台迁移和学习成本。
2. 面向可测试性、可监控性与可扩展性的架构演进
现代数据处理系统愈发重视以下三大工程属性:
- 可测试性:支持细粒度的单元测试与集成测试,便于快速验证逻辑正确性,保障迭代稳定性。
- 可监控性:提供精细化的性能指标采集、异常自动检测与告警机制,提升系统透明度与响应速度。
- 无缝扩展性:具备从单机小规模到亿级数据量的横向扩展能力,无需重构核心业务逻辑即可适应不同负载。
结论
MapReduce作为大数据领域的奠基性技术,在大规模数据处理史上具有里程碑意义。然而,其较高的运维成本、复杂的调优过程、滞后的生态系统以及无法融合流批处理需求等缺陷,使其逐步被更先进的分布式处理框架所替代。开发者应主动关注Apache Beam、Spark等现代大数据工具,深入理解数据分片机制、异常处理流程与容错设计原则,积极拥抱统一数据流编程模型的实践落地。技术的迭代不仅是工具的更新换代,更是思维方式与工程方法的全面进化。



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





