写这个的时候,其实我脑子里第一反应是好多年以前某位领导问过我,transformer的下一跳是什么?我当时的回复是transformer是一个量变到质变长期积累得到的范式,很早期的视觉里面也有类似的nonlocal等,而且卷积也在跟attention持续互补发挥作用。diffusion本身也不算transformer的下一跳,但是从建模方式上,可能有潜力会对ar带来很大冲击。
很早就关注扩散语言模型了(diffusion language model,dllm),但是受限于精力和算力一直没机会深度思考。从文本角度探索diffusion的架构相对当前比较好入手,并且这里面很多问题不解决,多模态的版本也不好搞,所以我们会先聚焦dllm上的算法基础。
去年下半年陆陆续续开始在一些方向上有一些探索,受启发于某位内部专家,赶在元旦之前写了一篇算是洞察材料的文章。
https://www.chaspark.com/#/hotspots/1224469190780706816
前几天在AAAI的报告重点介绍了团队的几个工作,包含next-block diffusion的训练,diffusion in diffusion的分层结构,diffusion agent等。
感叹于现在AI进步真的日益显著,该图片根据文字内容,用AIGC生成
相关PPT已经上传在项目网站上(sofar我还是觉得diffusion搞到代码和agent场景很有意思):https://noah-dllm.github.io/
关于当前diffusion遇到的问题,我们也写了个proposal,更早源自于前段时间在伦敦和加拿大等地的一些研讨,陆陆续续被我整理成了一些中文观点,附如下:
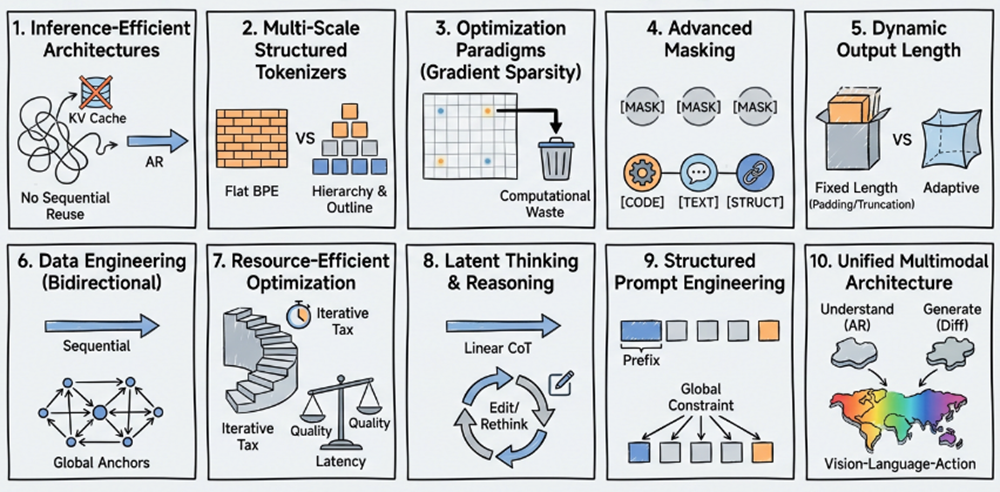
1. 推理高效的架构(kv cache/attention/model architecture): 当前的diffusion model整体框架还是用的ar模型,尤其是attention的形式,包括qkv和kv cache的计算等。在ar模型的next token prediction的推理模式中,可以复用kv cache来提升整体效率。但是diffusion model的mask位置的随机性导致kv cache复用的机制会失效,这也是当前diffusion model没有被广泛应用的主要问题之一。所以我们需要一个更合适diffusion model推理高效性的attention结构或者更有结构性的mask方式等,可以在兼顾diffusion解码方式的优势,也带来推理效率的提升。
idea:从ar的kv cache去思考,如果diffusion模型中mask tokens在去噪过程中,一定是从左到右顺序的,似乎可以解决kv cache复用的问题。但似乎不是完美方案,我们会去尝试一些更适合diffusion模型的attention或者kv相关的机制。
2. 更适配的词表(tokenizer): 最理想的diffusion model并不应该去follow ar现有的范式,而应该想人思考一样具有结构性,比如先对一个给定的topic生成一个全局的outline,然后再针对局部进行认真思考。本质上人在写文字的时候或者做报告的时候,往往是多尺度的。但是,ar模型的编码器通常都是通过各种切分和统计的算法得到的,也就是说,粒度是统一的。回到diffusion model,它的tokenizer是否也应该具有结构性,例如,不同粒度的tokenizer,有些负责段落间的联系,有些负责细节的修改,有些适合快速填充中间的空缺。
idea:简单的想法可能是tokenizer之间有重叠,形成词表金字塔,根据数据的首全局信息进行统计,比如首尾部分的信息等,参考一些图像生成的工作,先全局再局部,或者反之亦然。但是,想发挥这种词表的优势,对应的训推范式可能也需要进行调整。
3. 更好的优化范式(training and optimizing): diffusion model被讨论的比较多的优化上的问题在于梯度的计算比较低效,极端情况下一个很长的序列例如128k当中只有一个mask token,但是我们需要计算所有的前向和反向传播过程,也就是说,为了一个token做了很多的计算,并且得到的梯度反馈可能是很小的,这就意味着大多数时候同样训练开销下的diffusion模型精度不如ar模型。此外,当前diffusion模型在预训练阶段会在数据上加一定比例的随机mask tokens,在sft阶段是把answer都加上mask,可能会存在一些不同阶段训练不一致的问题,进一步对后续的强化学习也有很大的挑战。另外,masking的比例也是一个需要认真研究的问题,尤其是结合不同的训练阶段进行动态地调整。
idea:我觉得这是一个非常挑战的问题,暂时我能想到的idea是训练过程中。此外,在pre-training和sft阶段,可以引入更多的融合方案让diffusion模型的训练效果更好。
4. 掩码方式的更优方法(more mask tokens): 当前主流的diffusion model中,通常只有一个mask token,当然这也是一个非常简洁有效的范式,但是多样性不足,对于所有被mask掉的位置都用同样的token去处理,功能性上略有不足。此外,当前的masking范式,所有的位置都是等概率被处理的,有一些简单的地方可能不需要mask,而且mask的位置之间也没有联动性,缺乏结构化的masking机制。也就是说,当前的masking方式在diffusion model里面还处于比较初步的阶段,如何通过把diffusion model的潜力进一步挖掘出来,是一个非常值得深入讨论的问题。
idea:把原来的mask tokenizer变成多个,并加以一定的先验假设,让新增的tokenizer联动起来,也能高效的发挥作用。此外,也可以考虑更先进的加mask方式,尤其是结构化的,我觉得这样对复杂场景尤其是代码任务上可能会有更大的潜力。
5. 动态长度输出(dynamic output length): 虽然diffusion有很好的并行解码的特性,能够针对给定的问题进行快速输出,但是通常需要预先给定预期的输出长度,并且通过eos token来实现最终的输出长度。这很像我们的作文考试,例如以我的家乡为题写一个800字的文章,如果让扩散模型来执行这个任务的话,800字以内可以终止,以外的话就很难生成。虽然在模型的训练过程中有不同长短的数据用来学习,可以让diffusion模型对预期的输出长度有一定的适应性,但是一些极端情况下,比如9.11和9.8哪个大都需要100k tokens的话,是一种非常低效也可能对精度有影响的方式。所以,对于给定的问题,如何自适应地推断出最优的输出长度是非常值得探索的。
idea:在模型训练过程中同时增加对eos的位置预测,以便在推理过程中可以针对输入问题进行感知,减少无用的推理开销。此外,一些参数复用的技术可能会对超出给定长度的外推也是有帮助的。
6. 适配diffusion模型的数据(data engineering): 当前大多数的diffusion models都复用了ar模型的数据。哪怕是从ar模型改造过来的diffusion模型也在持续使用ar模型所积累的数据和相关的技术。虽然这些数据都是通用的,尤其是里面包含的知识也可以被扩散模型学习和吸收,但是如果我们想进一步激发扩散模型的潜力,让模型可以学习更多的结构化的知识并且具备更好的推理能力,当前的数据还是有进一步提升空间的。由于diffusion的训练阶段mask token都是随机加入的,想结合这个特性在数据上做一些优化所面临的挑战和需要的工作量还是非常巨大的。
idea :可能我们可以在预训练数据中增加mask的位置信息,通过对一些重要tokens的标注来提升diffusion模型的学习效率。此外,sft数据和rl的数据可能可以通过更有结构化的masking和标注,来让模型提升性能。
7. 资源高效的模型优化(model efficiency): 可能目前还不着急在扩散模型中讨论细粒度的模型压缩,比如weight或者神经元层面的稀疏化,因为很多基础的模型结构层面的东西还没有收敛。但是如何提升整体diffusion模型的推理效率还是非常值得研究的,尤其是当batch size加大之后,global diffusion的推理跟ar比在部分场景呈现劣势。此外,去噪过程本身的高效性也是值得研究的,无论是对那种形态的diffusion,都可以获得比较显著的收益。此外,从当前的各项评测来看,ar模型还是有显著优势的,如何把ar和diffusion同时使用来获得更大的整体收益,也是值得讨论的。
idea:几个可以优先尝试获得较大收益的可能方向是,扩散多步的蒸馏,参考之前在图像生成的相关工作,把diffusion模型的去噪步骤降低。投机推理,低比特后量化等也可以被用来降低推理开销。一些互补性的高效组合,例如,长序列单batch场景用diffusion,大batch整合信息用ar等。
8. 慢思考及隐式思考(reasoning & latent thinking): 在diffusion模型的sft训练过程中,对于给定的query会在预定的长度空间内通过不断的去噪过程来产生answer并进行对比。如果用传统的顺序的思维链等来实现慢思考,对于diffusion model来说可能是低效的,并没有充分释放diffusion模型的潜能,还有很多改进空间,无论是数据上还是优化方式等。此外,diffusion的另外一个潜力大的地方在于可以做remasking,在去噪的过程中,也可以对置信度较低的token进行重置然后进行修改,给了更多深度思考和隐式思考的可能性,一旦充分利用这些特性,模型的智能可以进一步提升。
idea:首先可能是需要针对diffusion的特性进行新的思维链的构建,比如结构化的思维链,尤其是代码和agent场景,从一个outline入手,再去补充细节可以产生更好的结果。此外,不同粒度的思考,过程中的editing和remasking等,都可以进行更多的探索。
9. 结构化的提示词工程和记忆(prompt and memory): 虽然当前有一些算法是通过ar模型续训到diffusion模式的,也有通过blcok解码的机制来让diffusion模型具有一定的局部ar特性。但是diffusion模型的masking方式和解码方式终究是不同的,尤其是diffusion不但可以向前看tokens,也可以向后看的特性。这就引发了我们的思考,是否有更适合diffusion模式的prompt格式,以及更高效的prompt方法,比如只给出几个全局关键token,快速实现全过程的解码和推理,这对代码、deep research、agent等场景是非常有帮助的。
idea:一个非常直接的方式是把原来的ar问答式prompt变成完形填空式的prompt用于diffusion模型,尤其是给一些关键信息辅助生成更好的回复。也可以通过一些prompt自演进的方式,来做更深度的优化。同时,这些方法也可以被用到rag和memory相关的工作中。
10. 未来的统一架构(uniform architecture): 在各种多模态或者多视角等任务中,我们经常会讨论,一个端到端from scratch的方案可能更好地激发模型的能力上限。但是,实际情况往往面临着很多挑战,比如,不同模态数据的对齐,数据配比,甚至不同任务所用的模型和优化目标完全不一样。比如用于理解的模型当前会用ar较多一些,而生成类任务会用diffusion多一些。未来一定是属于多模态的,那如何探索出来一个更统一的模型结构和训练范式,是非常有必要行的,而diffusion model当前所展现出来的能力恰恰具备一定的潜力。
idea:以vla模型为例,这是一个比较火热的领域,尤其是与真实物理环境交互,已经成功地融合了多种信息。当前的主流架构是vision和language部分以ar模式为主,但是action部分会采用diffusion的模式,不过这里的diffusion是传统的而不是离散的加mask的,为了生成更连续的动作轨迹。那么,能否用discrete diffusion models让这三个部分融合在一起,就是一个非常非常有意思的问题。
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





