经管之家App
让优质教育人人可得
立即打开


cm_ctl query -Cv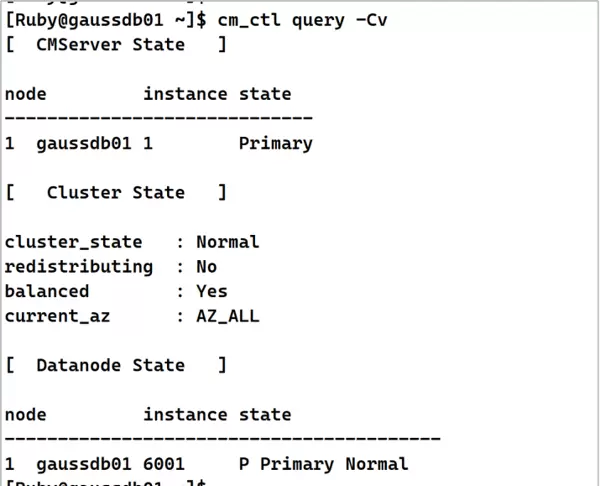
DROP TABLE IF EXISTS TEST_TABLE_1;
CREATE TABLE test_table_1(
a int,
b int,
c varchar(10),
d varchar(5)
);
CREATE INDEX test_idx_1_1 on test_table_1(c);INSERT INTO test_table_1
select generate_series(1,100000), round(random()*100), '61' || round(random()*10000) ||'000', '1';
INSERT INTO test_table_1
select generate_series(1,100000), round(random()*100), '61' || round(random()*10000) ||'000', '2';
INSERT INTO test_table_1
select generate_series(1,100000), round(random()*100), '61' || round(random()*10000) ||'000', '3';
INSERT INTO test_table_1
select generate_series(1,100000), round(random()*100), '61' || round(random()*10000) ||'000', '4';
ANALYZE test_table_1;SET explain_perf_mode=pretty;EXPLAIN (costs off, ANALYZE on)
SELECT a, sum(b)
FROM test_table_1
WHERE substr(c, 3, 6) = '1234'
GROUP BY a;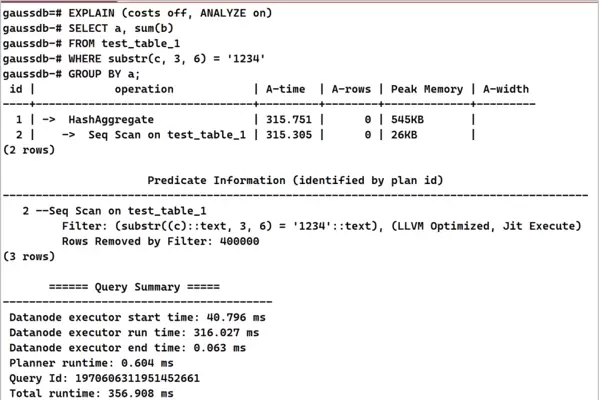 5. 根据执行计划分析结果,针对查询中使用的表达式条件,建立对应的表达式索引。
5. 根据执行计划分析结果,针对查询中使用的表达式条件,建立对应的表达式索引。
CREATE INDEX test_idx_1_2 on test_table_1(substr(c, 3, 6));EXPLAIN (costs off, ANALYZE on)
SELECT a, sum(b)
FROM test_table_1
WHERE substr(c, 3, 6) = '1234'
GROUP BY a;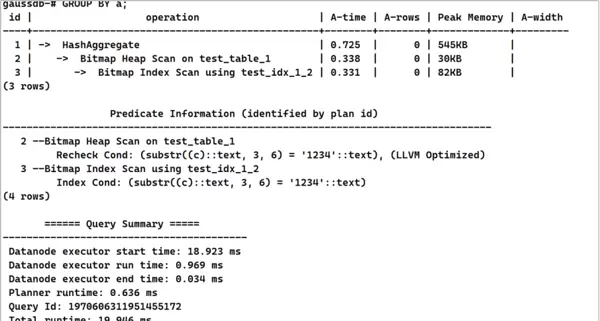
SET explain_perf_mode=pretty;DROP TABLE IF EXISTS test_table_2 ;
CREATE TABLE test_table_2 (
a int,
b int,
c varchar(10),
d varchar(5)
);
CREATE INDEX test_idx_2_1 on test_table_2(a);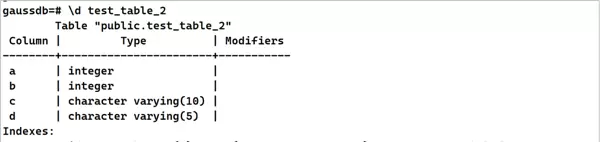 3. 导入约60秒量级的测试数据集。
3. 导入约60秒量级的测试数据集。
INSERT INTO test_table_2
select generate_series(1,100000), round(random()*100), '61' || round(random()*10000) ||'000', '1';
INSERT INTO test_table_2
select generate_series(1,100000), round(random()*100), '61' || round(random()*10000) ||'000', '2';
INSERT INTO test_table_2
select generate_series(1,100000), round(random()*100), '61' || round(random()*10000) ||'000', '3';
INSERT INTO test_table_2
select generate_series(1,100000), round(random()*100), '61' || round(random()*10000) ||'000', '4';
ANALYZE test_table_2;EXPLAIN (costs off, ANALYZE on)
SELECT *
FROM test_table_2
WHERE a = 100015 OR c = '615273000';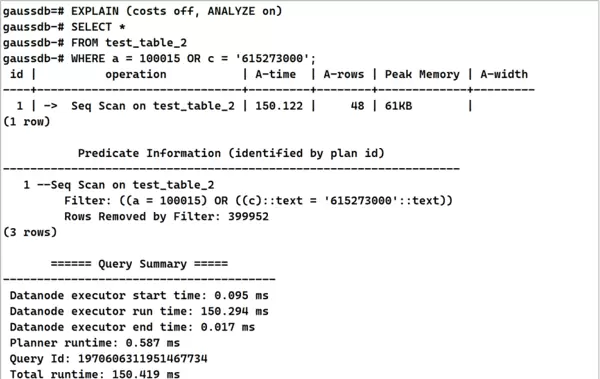 5. 分析发现因OR后存在未建索引的字段导致整体索引失效,因此对相关字段补充索引。
5. 分析发现因OR后存在未建索引的字段导致整体索引失效,因此对相关字段补充索引。
CREATE INDEX test_idx_2_2 ON test_table_2(c);EXPLAIN (costs off, ANALYZE on)
SELECT *
FROM test_table_2
WHERE a = 100015 OR c = '615273000';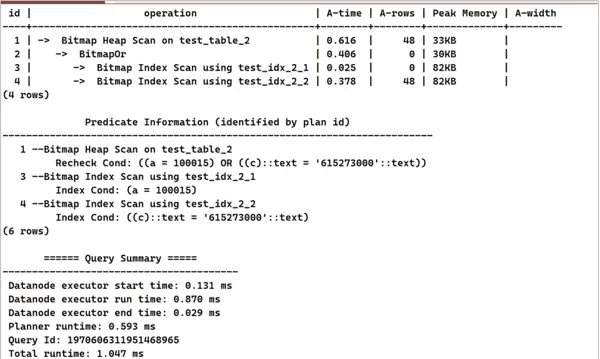
SET explain_perf_mode=pretty;DROP TABLE IF EXISTS test_table_4 ;
CREATE TABLE test_table_4 (
a varchar(10),
b varchar(10)
);
CREATE INDEX test_idx_4 on test_table_4(a);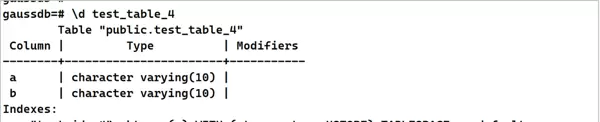 3. 加载测试数据,预计耗时约60秒。
3. 加载测试数据,预计耗时约60秒。
insert into test_table_4 values(generate_series(1,400000), generate_series(1,400000));
ANALYZE test_table_4;EXPLAIN (costs off, ANALYZE on)
SELECT *
FROM test_table_4
WHERE a = 10;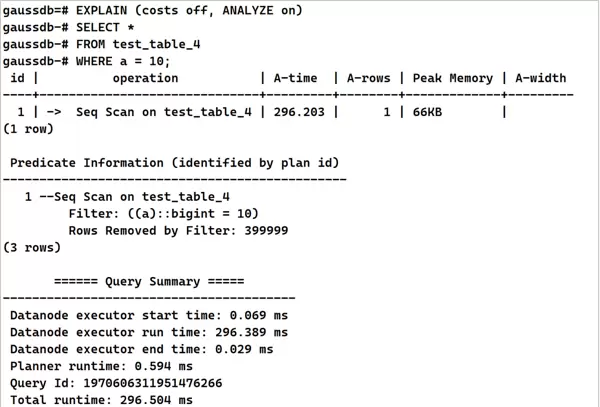 5. 对原SQL进行语义等价改写,显式转换数据类型,避免隐式转换干扰索引选择。
5. 对原SQL进行语义等价改写,显式转换数据类型,避免隐式转换干扰索引选择。
EXPLAIN (costs off, ANALYZE on)
SELECT *
FROM test_table_4
WHERE a = 10 :: varchar;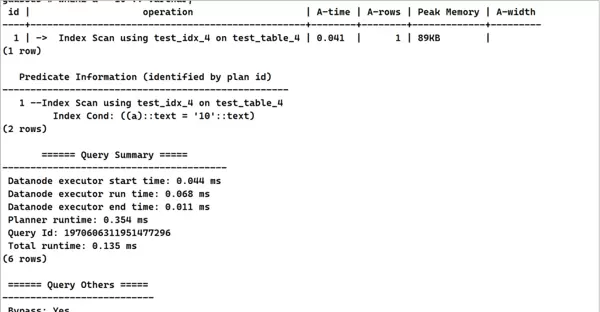
DROP TABLE IF EXISTS test_table_15_1;
CREATE TABLE test_table_15_1 (
a INTEGER
)PARTITION BY RANGE(a) (
PARTITION P1 VALUES LESS THAN(1000),
PARTITION P2 VALUES LESS THAN(2000),
PARTITION P3 VALUES LESS THAN(3000),
PARTITION P4 VALUES LESS THAN(4000),
PARTITION P5 VALUES LESS THAN(5000),
PARTITION P6 VALUES LESS THAN(6000),
PARTITION P7 VALUES LESS THAN(7000),
PARTITION P8 VALUES LESS THAN(MAXVALUE)
);
DROP TABLE IF EXISTS test_table_15_2;
CREATE TABLE test_table_15_2 (
b INTEGER,
c VARCHAR
)PARTITION BY RANGE(c) (
PARTITION P1 VALUES LESS THAN(1000),
PARTITION P2 VALUES LESS THAN(2000),
PARTITION P3 VALUES LESS THAN(3000),
PARTITION P4 VALUES LESS THAN(4000),
PARTITION P5 VALUES LESS THAN(5000),
PARTITION P6 VALUES LESS THAN(6000),
PARTITION P7 VALUES LESS THAN(7000),
PARTITION P8 VALUES LESS THAN(MAXVALUE)
);INSERT INTO test_table_15_1 SELECT generate_series(1,100000);
INSERT INTO test_table_15_2 SELECT x, x from generate_series(1,100000) AS x;set explain_perf_mode=pretty;EXPLAIN ANALYZE SELECT * FROM test_table_15_1 t1, test_table_15_2 t2 WHERE a = c AND a BETWEEN 3000 AND 4000; 5. 重新定义test_table_15_2表结构,修正字段类型匹配问题。
5. 重新定义test_table_15_2表结构,修正字段类型匹配问题。
DROP TABLE IF EXISTS test_table_15_2;
CREATE TABLE test_table_15_2 (
b INTEGER,
c INTEGER
)PARTITION BY RANGE(c) (
PARTITION P1 VALUES LESS THAN(1000),
PARTITION P2 VALUES LESS THAN(2000),
PARTITION P3 VALUES LESS THAN(3000),
PARTITION P4 VALUES LESS THAN(4000),
PARTITION P5 VALUES LESS THAN(5000),
PARTITION P6 VALUES LESS THAN(6000),
PARTITION P7 VALUES LESS THAN(7000),
PARTITION P8 VALUES LESS THAN(MAXVALUE)
);INSERT INTO test_table_15_2 SELECT x, x FROM generate_series(1,100000) AS x;EXPLAIN ANALYZE SELECT * FROM test_table_15_1 t1, test_table_15_2 t2 WHERE a = c AND a BETWEEN 3000 AND 4000;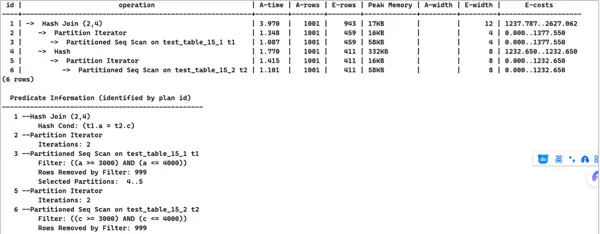
DROP TABLE IF EXISTS test_table_15_1;
CREATE TABLE test_table_15_1 (
a INTEGER
)PARTITION BY RANGE(a) (
PARTITION P1 VALUES LESS THAN(1000),
PARTITION P2 VALUES LESS THAN(2000),
PARTITION P3 VALUES LESS THAN(3000),
PARTITION P4 VALUES LESS THAN(4000),
PARTITION P5 VALUES LESS THAN(5000),
PARTITION P6 VALUES LESS THAN(6000),
PARTITION P7 VALUES LESS THAN(7000),
PARTITION P8 VALUES LESS THAN(MAXVALUE)
);
DROP TABLE IF EXISTS test_table_15_2;
CREATE TABLE test_table_15_2 (
b INTEGER,
c VARCHAR
)PARTITION BY RANGE(c) (
PARTITION P1 VALUES LESS THAN(1000),
PARTITION P2 VALUES LESS THAN(2000),
PARTITION P3 VALUES LESS THAN(3000),
PARTITION P4 VALUES LESS THAN(4000),
PARTITION P5 VALUES LESS THAN(5000),
PARTITION P6 VALUES LESS THAN(6000),
PARTITION P7 VALUES LESS THAN(7000),
PARTITION P8 VALUES LESS THAN(MAXVALUE)
);INSERT INTO test_table_15_1 SELECT generate_series(1,100000);
INSERT INTO test_table_15_2 SELECT x, x from generate_series(1,100000) AS x;set explain_perf_mode=pretty;EXPLAIN ANALYZE SELECT * FROM test_table_15_1 t1, test_table_15_2 t2 WHERE a = c AND a BETWEEN 3000 AND 4000;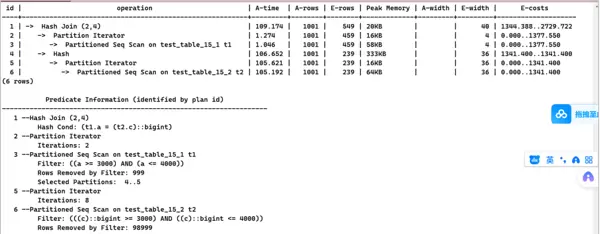 5. 修改test_table_15_2表定义,调整字段类型以消除潜在转换风险。
5. 修改test_table_15_2表定义,调整字段类型以消除潜在转换风险。
DROP TABLE IF EXISTS test_table_15_2;
CREATE TABLE test_table_15_2 (
b INTEGER,
c INTEGER
)PARTITION BY RANGE(c) (
PARTITION P1 VALUES LESS THAN(1000),
PARTITION P2 VALUES LESS THAN(2000),
PARTITION P3 VALUES LESS THAN(3000),
PARTITION P4 VALUES LESS THAN(4000),
PARTITION P5 VALUES LESS THAN(5000),
PARTITION P6 VALUES LESS THAN(6000),
PARTITION P7 VALUES LESS THAN(7000),
PARTITION P8 VALUES LESS THAN(MAXVALUE)
);INSERT INTO test_table_15_2 SELECT x, x FROM generate_series(1,100000) AS x;EXPLAIN ANALYZE SELECT * FROM test_table_15_1 t1, test_table_15_2 t2 WHERE a = c AND a BETWEEN 3000 AND 4000;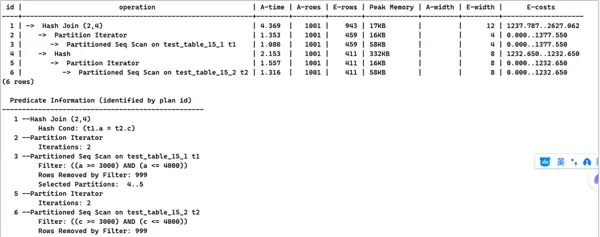
SET explain_perf_mode=pretty;DROP TABLE IF EXISTS test_table_9_1;
CREATE TABLE test_table_9_1 (
a int,
b int,
c int
);
DROP TABLE IF EXISTS test_table_9_2;
CREATE TABLE test_table_9_2 (
a int,
b int
);INSERT INTO test_table_9_1
SELECT generate_series(1,20000),generate_series(1, 20000) ,generate_series(1, 20000);
ANALYZE test_table_9_1;
INSERT INTO test_table_9_2
SELECT generate_series(1,1000),generate_series(1, 1000);
ANALYZE test_table_9_2;EXPLAIN (costs off, ANALYZE on)
SELECT t1.a, t1.b
FROM test_table_9_1 t1
WHERE t1.b NOT IN (
SELECT b
FROM test_table_9_2
); 5. 将原语句改写为等效的NOT EXISTS形式,并将关联条件t1.b = t2.b置于子查询内部,确保语义一致,执行改写后的SQL2。
5. 将原语句改写为等效的NOT EXISTS形式,并将关联条件t1.b = t2.b置于子查询内部,确保语义一致,执行改写后的SQL2。
EXPLAIN (costs off, ANALYZE on)
SELECT t1.a, t1.b
FROM test_table_9_1 t1
WHERE NOT EXISTS (
SELECT b
FROM test_table_9_2 t2
WHERE t1.b = t2.b
);
SET explain_perf_mode=pretty;drop table if exists test_test_table7_1;
create table test_test_table7_1(c1 int,c2 int);
drop table if exists test_test_table7_2;
create table test_test_table7_2(c1 int,c2 int);INSERT INTO test_test_table7_1
SELECT generate_series(1,10000),generate_series(1,10000);
INSERT INTO test_test_table7_2
SELECT generate_series(1,10000),generate_series(1,10000);
ANALYZE;set rewrite_rule='none';
explain(costs off, ANALYZE on)
select c1,(select avg(c2) from test_test_table7_2 t2 where t2.c2=t1.c2)
from test_test_table7_1 t1
where t1.c1<100 order by t1.c2; 5. 在GaussDB中,根据子查询在SQL语句中的位置,可将其划分为“子查询”与“子链接”两种形式,不同的结构可能受到不同重写规则的影响。
5. 在GaussDB中,根据子查询在SQL语句中的位置,可将其划分为“子查询”与“子链接”两种形式,不同的结构可能受到不同重写规则的影响。在SQL查询中,子查询(SubQuery)通常对应查询解析树中的范围表(RangeTblEntry),通俗来说,是指出现在FROM子句后的独立SELECT语句。而子链接(SubLink)则对应解析树中的表达式节点,常见于WHERE、ON条件或目标列(targetlist)中的嵌套查询结构。
由于子查询在SQL中的使用较为灵活,子链接(SubLink)的频繁嵌套容易导致整体查询逻辑复杂化,进而引发性能瓶颈。为优化此类情况,可通过GUC参数rewrite_rule进行控制,调整查询重写行为。针对SubLink的主要优化策略是“提升”(pullup)内层子查询,使其与外层查询合并为JOIN操作,避免生成包含SubPlan及Broadcast内表的低效执行计划。
当目标列中存在相关子查询时,往往会导致该子查询无法被自动提升。此时可启用rewrite_rule参数中的intargetlist选项,强制将目标列中的子查询提升并转换为JOIN结构,从而提升执行效率。需要注意的是,rewrite_rule支持多种可选的查询重写规则,但并非所有规则在所有场景下都能带来性能提升。应结合具体业务逻辑和数据特征,合理配置该参数,以实现最优查询性能。
set rewrite_rule='intargetlist';以下为查看上述查询执行计划的操作示例:
explain(costs off, ANALYZE on)
select c1,(select avg(c2) from test_test_table7_2 t2 where t2.c2=t1.c2)
from test_test_table7_1 t1
where t1.c1<100 order by t1.c2;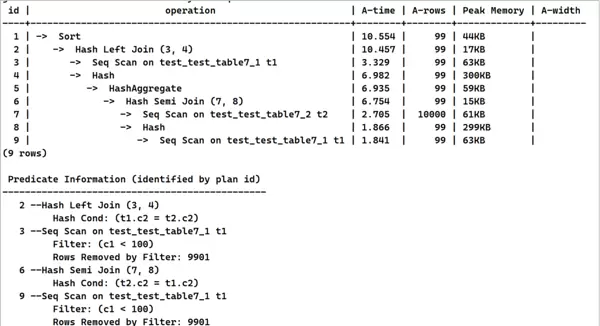
通过逻辑层面的SQL语句重写,可以有效优化查询性能,尤其是在涉及子查询的复杂场景中。
1. 创建测试表
CREATE TABLE t_p1 (id serial,number character varying(96),type integer);
CREATE TABLE t_p2 (id serial,number character varying(96),type integer);2. 插入测试数据
insert into t_p1 select generate_series(1,10000),generate_series(1,10000),floor((random() * 100));
insert into t_p2 select generate_series(1,1000),floor(10 + random() * 100),floor((random() * 1000));3. 原始业务SQL包含标量子查询,示例如下:
select p.id ,p.number ,(select max(td.type) from t_p2 td where td.number=p.number) as max from t_p1 p where p.id<100;4. 查看当前SQL的执行计划:
explain analyze select p.id ,p.number ,(select max(td.type) from t_p2 td where td.number=p.number) as max from t_p1 p where p.id<100;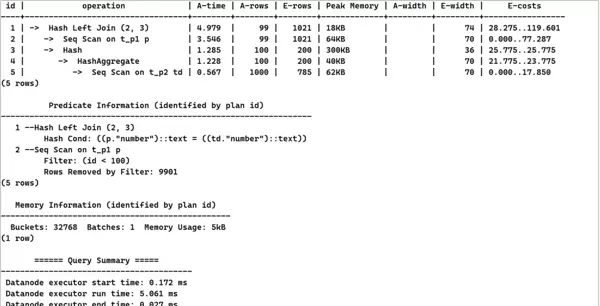
5. 优化方案一:该场景属于典型的标量子查询应用。由于相关性限制,子查询无法被自动提升。结合业务数据特点分析可知,该标量子查询可通过逻辑等价改写为关联查询(JOIN),从而消除子查询结构,提升执行效率。改写参考如下:
explain analyze select p.id ,p.number ,td.max from t_p1 p,(select number,max(type) max from t_p2 group by 1) td where td.number(+)=p.number and p.id<100;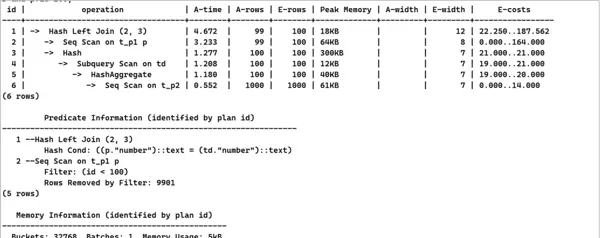
6. 优化方案二:GaussDB支持多种查询重写规则,可通过组合使用这些规则,由优化器自动将目标列中的子查询提升并转化为JOIN操作。此方式能显著提升查询性能,具体实现方式如下:
explain analyse select /*+ set(rewrite_rule 'magicset,intargetlist,uniquecheck')*/ p.id ,p.number ,(select max(td.type) from t_p2 td where td.number=p.number) as max from t_p1 p where p.id<100;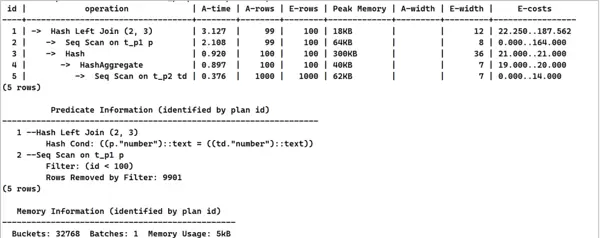
7. 清理环境:删除测试表t_p1和t_p2。
drop table t_p1;
drop table t_p2;
 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




