经管之家App
让优质教育人人可得
立即打开


在日常的工作与生活中,我们常常依赖搜索引擎来寻找问题的解决方案。然而,实际体验却往往不尽如人意:搜索结果充斥着大量重复、基础性或带有商业推广性质的内容。尽管不断调整关键词,依然难以定位真正有价值的信息。这种困境源于当前搜索引擎算法的局限——它们更倾向于优先展示高点击率的内容,而非高质量或最准确的答案。商业利益常凌驾于信息本身的价值之上,导致用户获取的并非最优解。
随着人工智能技术的迅猛发展,我们在设计AI驱动的产品时,亟需打破这一“信息茧房”。以RAG(检索增强生成)系统为例,为了提升回答的精准度和用户体验,我们需要进一步优化其架构。在已掌握RAG基本原理的基础上,引入**结果重排序(Rerank)模型**,相当于为系统插上一双更敏锐的“慧眼”,使其能够深入理解查询与文档之间的语义关联,从海量候选中筛选出最具相关性的内容,并以清晰的方式呈现给用户。


重排序(Rerank)是检索增强生成(RAG)流程中的关键环节,位于初步检索之后、大语言模型(LLM)生成答案之前。它的作用是对初始检索返回的一批文档进行精细化的相关性评估与重新排序。通常情况下,向量检索会返回数十至数百个候选文档,而Rerank模型则像一位专业的“质检员”或“决赛裁判”,从中甄选出最相关、最可靠的少数几个文档(例如5–10个),作为最终输入给LLM的上下文依据。
可以将整个过程类比为一场选拔赛:
虽然基于Embedding的向量检索方法(如FAISS)具备极高的检索速度,但在实际应用中仍存在明显短板:
正是在这样的背景下,Rerank模型通过精细化分析每一个“查询-文档”对的相关性,有效弥补了上述缺陷,显著提升了整体系统的准确性与稳定性。
| 特性 | 嵌入(Embedding)模型 | 重排序(Rerank)模型 |
|---|---|---|
| 输入形式 | 单段文本 | (Query, Document) 成对输入 |
| 输出结果 | 高维向量表示 | 单一相关性评分(标量) |
| 计算机制 | 双编码器结构,独立编码后计算相似度 | 交叉编码器,实现查询与文档间的深度交互 |
| 处理速度 | 极快,适合大规模初筛 | 较慢,适用于少量候选精排 |
| 准确度水平 | 良好,但存在一定误差 | 极高,专精于相关性判断 |
| 典型应用场景 | 从海量数据中快速召回Top K文档 | 对Top K结果进行二次排序优化 |
Rerank模型多采用交叉编码器(Cross-Encoder)架构,区别于用于生成Embedding的双编码器(Bi-Encoder)。
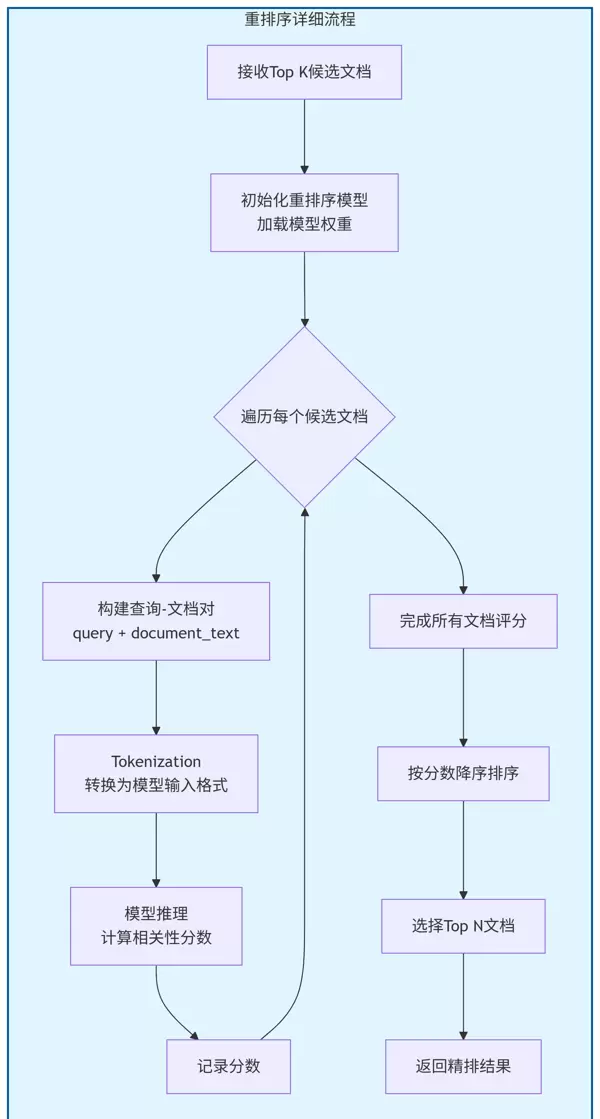
在一个集成了Rerank模块的典型RAG系统中,信息流动遵循以下步骤:


在系统运行前,需对原始文档进行结构化处理:
该阶段目标是快速召回大量潜在相关文档:
此阶段通过更精细的相关性建模提升排序质量:
结合精排后的上下文生成高质量回答:

输入: "如何学习钢琴?"
输出:
输入: 查询“如何学习钢琴?”及初始检索出的100个文档
处理: 使用BGE-Reranker模型计算每篇文档与查询之间的细粒度相关性得分
输出:
输入: 经重排序后选出的5个最相关文档 + 原始查询“如何学习钢琴?”
输出:
学习钢琴应从基础入手,首先掌握正确的坐姿和手型,并熟悉基本指法。建议从《拜厄钢琴基本教程》开始练习,每日坚持30至60分钟。同时,了解基础乐理知识,包括音符识别、节奏训练和和弦构成等内容,有助于提升整体演奏能力。若条件允许,最好寻求经验丰富的老师指导,以便及时纠正错误动作并获得个性化学习建议。
在基于FAISS的RAG流程中集成bge-reranker模型进行重排序处理:
from langchain_community.vectorstores import FAISS
# 初始化嵌入模型以支持初步检索
embedding_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
# 定义模拟的知识文档集合
documents = [
"苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。",
"苹果公司最著名的产品是iPhone智能手机,它彻底改变了移动通信行业。",
"水果苹果是一种蔷薇科苹果属的落叶乔木果实,营养价值高,富含维生素和纤维。",
"苹果公司在2023年发布了其首款混合现实头显设备Apple Vision Pro。",
"吃苹果有助于促进消化和增强免疫力,是一种健康零食。",
"蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。"
]
# 将文本内容转换为LangChain Document格式
docs = [Document(page_content=text) for text in documents]
# 构建基于FAISS的向量数据库
vectorstore = FAISS.from_documents(docs, embedding_model)
# 用户输入的问题
query = "苹果公司的创始人是谁?"
# 初步检索:从向量库中获取最相关的前K个文档(K设为4)
initial_retrieved_docs = vectorstore.similarity_search(query, k=4)
print("=== 初始检索结果(基于语义相似度)===")
for i, doc in enumerate(initial_retrieved_docs):
print(f"{i+1}. [相似度得分: N/A] {doc.page_content}")
# 加载用于重排序的模型与分词器
model_name = "BAAI/bge-reranker-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
model.eval() # 启用评估模式以确保推理稳定
# 定义文档重排序逻辑
def rerank_docs(query, retrieved_docs, model, tokenizer, top_n=3):
"""
对已检索出的文档进行相关性重排序
Args:
query: 用户提出的问题
retrieved_docs: 初步召回的文档列表
model: 预训练的序列分类重排序模型
tokenizer: 对应模型的分词工具
top_n: 最终保留的最高排名文档数量
Returns:
sorted_docs: 按相关性由高到低排列的文档列表
scores: 各文档对应的相关性得分
"""
# 组合查询与每个文档形成文本对
pairs = [(query, doc.page_content) for doc in retrieved_docs]
# 批量处理所有文本对,进行编码
with torch.no_grad():
inputs = tokenizer(
pairs,
padding=True,
truncation=True,
return_tensors='pt',
max_length=512
)
# 前向计算获取相关性分数
scores = model(**inputs).logits.squeeze(dim=-1).float().numpy()
# 将文档与其分数配对
doc_score_list = list(zip(retrieved_docs, scores))
# 根据分数从高到低排序
doc_score_list.sort(key=lambda x: x[1], reverse=True)
# 提取排序后的前N个文档
sorted_docs = [doc for doc, score in doc_score_list[:top_n]]
3. 代码详解
1. 初始设置:
采用 sentence-transformers 提供的嵌入模型,并结合 FAISS 构建基础向量检索系统。设定一个具有歧义性的查询语句:“苹果公司的创始人是谁?”,需注意知识库中同时包含“苹果公司”与“水果苹果”的相关信息。
2. 初始检索阶段:
通过调用 vectorstore.similarity_search(query, k=4) 方法,获取语义上最相近的前 4 个文档。由于 Embedding 模型基于泛化语义理解,可能将关于水果“苹果”的内容也纳入召回结果(如文档3和5)。
3. Rerank 模型初始化:
利用 transformers 库加载预训练的 BAAI/bge-reranker-base 模型及其对应分词器。执行 model.eval() 将模型切换至评估模式,关闭 Dropout 等仅用于训练的组件,以确保推理输出稳定一致。
4. 重排序函数 rerank_docs 实现逻辑:
- 构造文本对: 将原始查询与每个已检索到的文档内容组合成 (Query, Document) 对。
- Tokenization 处理: 使用 tokenizer 将所有文本对转换为模型所需的输入格式(包括 input_ids、attention_mask 等),其中 padding=True 和 truncation=True 保证不同长度的输入可统一进行批处理。
- 模型推理过程: 在 with torch.no_grad() 上下文中将处理后的数据送入模型进行预测。此操作不记录梯度信息,有效降低内存占用并提升推理速度。模型输出为相关性得分,分数越高表示该文档与查询的相关性越强。
# 4. 执行重排序
reranked_docs, reranked_scores = rerank_docs(query, initial_retrieved_docs, model, tokenizer, top_n=3)
# 5. 输出重排序结果
print("\n=== 重排序后结果(基于交叉编码相关性)===")
for i, (doc, score) in enumerate(zip(reranked_docs, reranked_scores)):
print(f"{i+1}. [相关性分数: {score:.4f}] {doc.page_content}")
# 6. 构造最终上下文并模拟 LLM 输入
context_for_llm = "\n".join([doc.page_content for doc in reranked_docs])
prompt = f"""
基于以下上下文,请回答问题。
上下文:
{context_for_llm}
=== 最终输出最优的匹配结果 ===
问题:{query}
答案:{reranked_docs[0].page_content}
"""
print(f"\n=== 最终提供给LLM的Prompt ===")
print(prompt)

2. 执行结果展示
=== 初始检索结果(基于语义相似度)===
1. [相似度得分: N/A] 苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。
2. [相似度得分: N/A] 蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。
3. [相似度得分: N/A] 苹果公司在2023年发布了其首款混合现实头显设备Apple Vision Pro。
4. [相似度得分: N/A] 水果苹果是一种蔷薇科苹果属的落叶乔木果实,营养价值高,富含维生素和纤维。
=== 重排序后结果(基于交叉编码相关性)===
1. [相关性分数: 9.3700] 苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。
2. [相关性分数: 4.5305] 蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。
3. [相关性分数: -6.0679] 苹果公司在2023年发布了其首款混合现实头显设备Apple Vision Pro。
=== 最终提供给LLM的Prompt ===
基于以下上下文,请回答问题。
上下文:
苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。
蒂姆·库克是苹果公司的现任首席执行官,于2011年接替史蒂夫·乔布斯。
苹果公司在2023年发布了其首款混合现实头显设备Apple Vision Pro。
=== 最终输出最优的匹配结果 ===
问题:苹果公司的创始人是谁?
答案:苹果公司于1976年由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,最初主要生产和销售个人电脑。

sorted_scores = [score for doc, score in doc_score_list[:top_n]]
return sorted_docs, sorted_scores
在信息检索过程中,排序与筛选是关键步骤。系统会依据模型计算出的相关性分数,对所有候选文档进行降序排列,并最终返回得分最高的Top N个文档。
以“苹果公司”为例进行结果分析:
初始检索结果:由于“苹果”一词具有多义性,检索系统可能返回一些关于水果苹果的文档。这些文档虽然包含相同词汇,但在语义上与科技企业无关,相关性较低。
重排序后结果:引入Rerank模型后,其作为“相关性判断专家”,能够精准识别用户查询中的特定实体意图——此处为“苹果公司”。该模型会对涉及科技公司的文档赋予高分,而将描述水果的文档评分大幅降低。经过这一过程,最终排名靠前的文档均为高度相关的科技类内容,无关信息被有效剔除。


为了实现上述功能,示例中引用了两个可本地部署的模型:
当代码首次执行时,若检测到本地尚未存在所需模型,系统将自动从远程仓库下载:


下载完成后,模型文件将被缓存至本地目录。后续再次调用时,程序会直接加载本地模型,无需重复下载,提升运行效率。
从输出结果可以明显看出,经过重排序处理后,包含核心答案关键词如“创始人”的文档被调整至首位,且前几位全部为与“学习钢琴”强相关的教学类内容,无关或边缘信息被淘汰。这显著提升了提供给大语言模型(LLM)的上下文质量,从而保障了生成答案的准确性和实用性。
Rerank模型的应用,使得整个RAG系统从基础可用跃升为高质量响应,成为性能优化的关键环节。
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
class BGEReranker:
def __init__(self, model_name="BAAI/bge-reranker-base"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(model_name)
self.model.eval() # 设置为评估模式
def rerank(self, query: str, documents: list, top_k: int = 5):
"""
对文档进行重排序
:param query: 用户查询
:param documents: 候选文档列表
:param top_k: 返回前K个文档
:return: 排序后的文档和分数
"""
# 构建查询-文档对
pairs = [(query, doc) for doc in documents]
# 特征编码
with torch.no_grad():
inputs = self.tokenizer(
pairs,
padding=True,
truncation=True,
return_tensors='pt',
max_length=512
)
# 计算相关性分数
scores = self.model(**inputs).logits.squeeze(dim=-1).float().numpy()
# 组合文档和分数
scored_docs = list(zip(documents, scores))
# 按分数降序排序
scored_docs.sort(key=lambda x: x[1], reverse=True)
return scored_docs[:top_k]
# 使用示例
if __name__ == "__main__":
# 初始化重排序模型
reranker = BGEReranker()
# 用户查询
query = "如何学习钢琴?"
# 初始检索结果(假设从FAISS获取)
initial_docs = [
"钢琴保养和清洁方法",
"音乐理论基础入门",
"钢琴购买指南:如何选择第一台钢琴",
"钢琴入门指法教程:从零开始学习",
"十大著名钢琴家及其作品",
"钢琴练习曲目推荐:适合初学者"
]
print("初始检索结果:")
for i, doc in enumerate(initial_docs):
print(f"{i+1}. {doc}")
# 应用重排序
reranked_docs = reranker.rerank(query, initial_docs, top_k=3)
print("\n重排序后结果:")
for i, (doc, score) in enumerate(reranked_docs):
print(f"{i+1}. {doc} (得分: {score:.4f})")
重排序(Rerank)作为RAG系统中提升检索精度的核心环节,能够深入分析查询与文档之间的语义关联,对初步检索出的结果进行精细化排序,从而筛选出最相关的文档内容。这一过程显著增强了最终生成答案的准确性和质量。
尽管重排序会带来一定的计算负担,但在大多数注重结果准确性的应用场合中,其所带来的性能增益远超额外开销,已成为现代RAG架构中不可或缺的一环。
在对准确性要求极高的领域,例如医疗诊断、法律条文检索等场景,建议务必引入重排序机制。而对于响应延迟敏感或计算资源受限的环境,则可根据实际情况选择性启用,或减少参与重排序的文档数量(即控制K值)。合理选用重排序策略与模型,有助于推动RAG系统从“可用”迈向“好用”,充分释放检索增强生成技术的潜力。
执行结果展示如下:
初始检索结果:
1. 钢琴保养和清洁方法
2. 音乐理论基础入门
3. 钢琴购买指南:如何选择第一台钢琴
4. 钢琴入门指法教程:从零开始学习
5. 十大著名钢琴家及其作品
6. 钢琴练习曲目推荐:适合初学者
重排序后结果:
1. [分数: 1.7239] 钢琴入门指法教程:从零开始学习
2. [分数: 0.7639] 音乐理论基础入门
3. [分数: -1.1614] 钢琴练习曲目推荐:适合初学者
最优的匹配结果:
钢琴入门指法教程:从零开始学习



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




