经管之家App
让优质教育人人可得
立即打开


Step 1:Python 环境准备
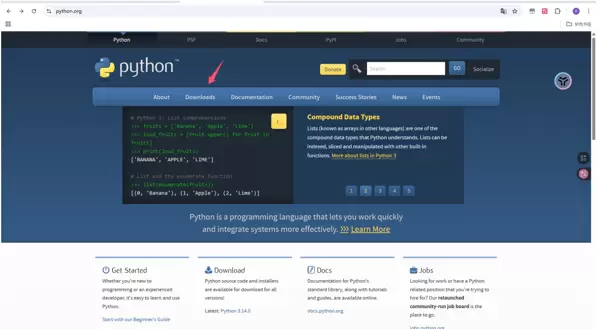
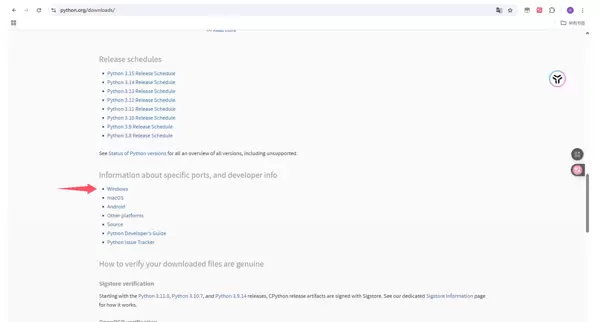
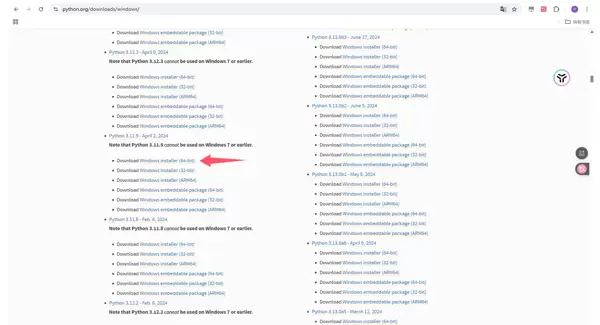
若设备已安装 Python,可跳过此步骤。访问 https://www.python.org/,进入 Download 页面,选择 Windows 平台,下载 Windows installer (64-bit) 版本。推荐使用 Python 3.10 至 3.13 的版本,图示以 3.11.9 为例。
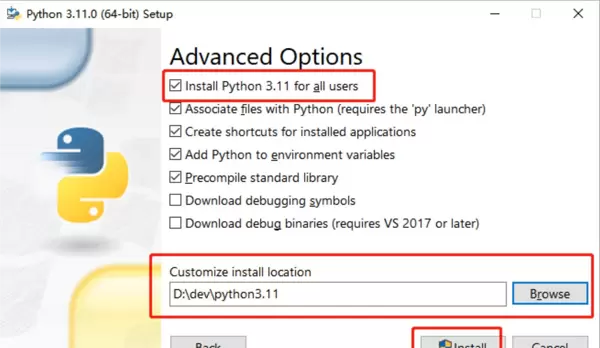
运行下载的 .exe 安装程序,务必勾选 “Add python.exe to PATH” 和 “Use admin privileges when installing py.exe”,然后点击 “Customize installation” 进入下一步设置。
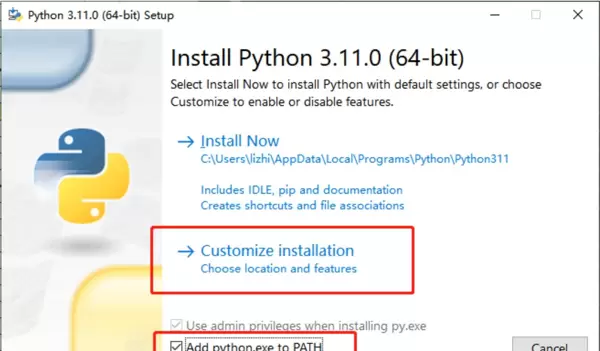
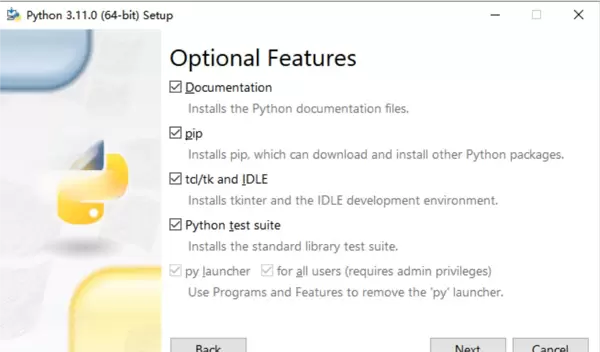
在可选项中按提示进行勾选,并自定义安装路径完成安装过程。
验证是否安装成功:按下 Win+R 键,输入 cmd 并回车,随后在命令行中输入 python,若返回已安装的 Python 版本信息,则表示安装成功。
Step 2:PyTorch 安装
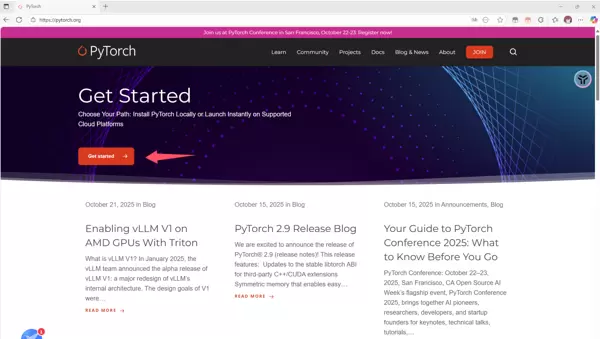
前往 https://pytorch.org/,点击 Get started 按钮。
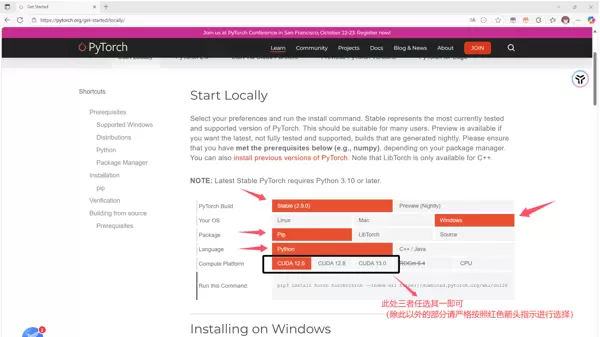
根据系统情况选择对应安装方式:
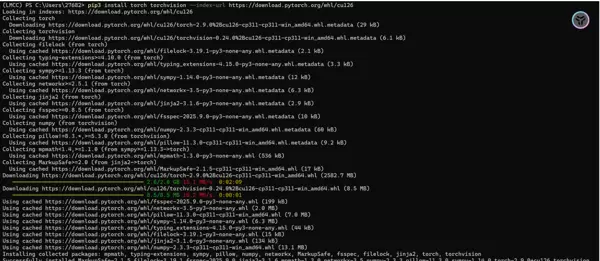
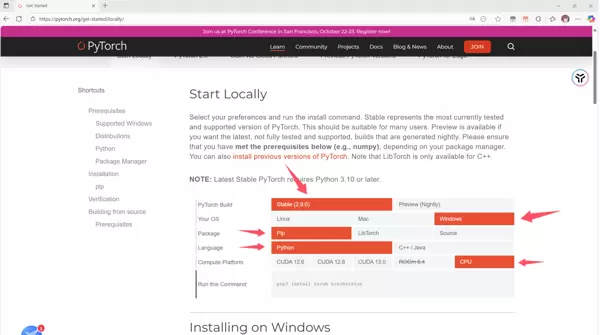
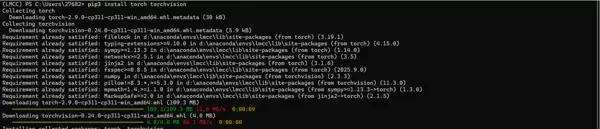
Step 3:Transformers 库安装
在 PowerShell 中执行以下命令:
python -m pip install -U transformers
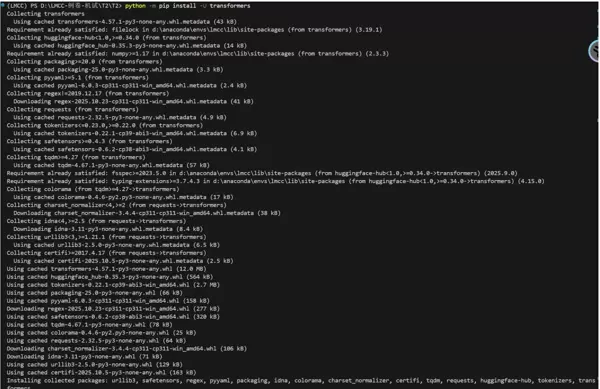
Step 1:Python 环境搭建
打开终端,依次执行以下命令以更新系统并安装必要组件:
sudo apt update sudo apt install -y python3 python3-venv python3-pip build-essential python3-dev git curl libssl-dev libffi-dev python3 -m pip install -U pip setuptools wheel
Step 2:PyTorch 安装
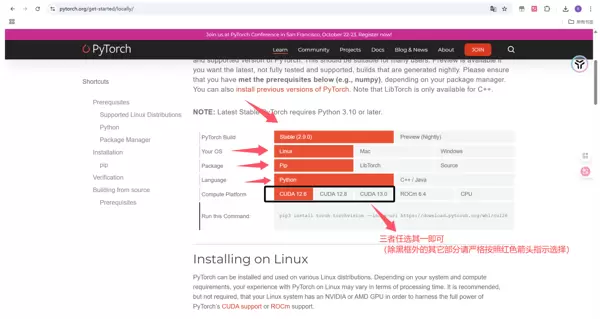
访问 https://pytorch.org/,点击 Get started。
根据硬件条件进行选择:
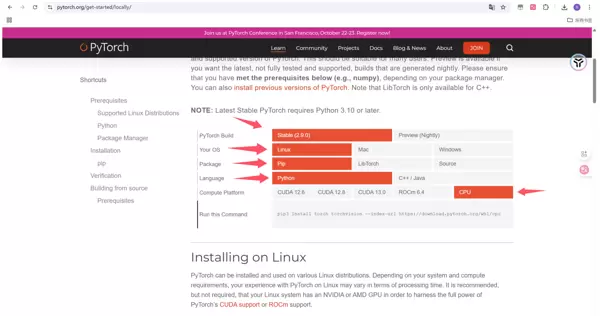
Step 3:Transformers 模块安装
在终端中运行如下命令:
python -m pip install -U transformers
# -*- coding: utf-8 -*-
"""
仅此文件允许考生修改:
- 请在下列函数的函数体内完成实现。
- 不要改动函数名与参数签名。
- 你可以新增少量辅助函数。
"""
# 主要流程包含三部分:
# 1) 构造 system prompt;
# 2) 通过 tokenizer 的 chat 模板拼装单条对话输入;
# 3) 基于 HuggingFace Transformers 的 generate 接口实现单条/批量推理。
from typing import List # 引入 List 用于类型注解(批量文本列表等)
import torch # 引入 PyTorch,用于张量与设备迁移
from transformers import AutoTokenizer, AutoModelForCausalLM # 引入 HF 的分词器与自回归模型抽象
# ============================================================
# 第一部分:Prompt 定义
# ============================================================
def build_system_prompt() -> str:
"""
考生实现:定义 system prompt
- 返回一个 system prompt,要求模型以"[Answer]: "的单行格式给出最终数值。
"""
# ======== 考生实现区域(可修改) ========
return """你是一个精确的数学计算助手。请按照以下步骤严格计算并返回准确的最终数值。
【计算步骤】
步骤1 - 符号转换:
- 将问题中的所有符号转换为标准数学符号
- +, ?, ⊕, 加 → +
- -, 减 → -
- ×, *, 乘 → ×
- ÷, /, 除 → ÷
- ⊕ 不是异或运算,就是普通加法 +
- 输出转换后的标准计算公式
步骤2 - 分步计算:
- 按照运算优先级逐步计算
- 每步只写出计算结果,不要过多解释
步骤3 - 输出答案:
- 使用格式:[Answer]: 数值
- 例如:[Answer]: 42
- 整数直接输出,确保计算准确
"""
# ======== 考生实现区域(可修改) ========
# ============================================================
# 第二部分:模板拼装
# ============================================================
def apply_chat_template_single(
tokenizer: AutoTokenizer,
system_prompt: str,
problem: str,
) -> str:
"""
考生实现:将单个问题转换为模型输入文本
- 使用 tokenizer.apply_chat_template
- 返回拼装好的文本字符串
"""
# ======== 考生实现区域(可修改) ========
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": problem},
]
rendered = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True,
)
return rendered
# ======== 考生实现区域(可修改) ========
# ============================================================
# 第三部分:核心推理实现
# ============================================================
def generate_single(
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer,
rendered_text: str,
max_new_tokens: int,
do_sample: bool,
) -> torch.Tensor:
# ======== 考生实现区域(可修改) ========
inputs = tokenizer(
rendered_text,
return_tensors="pt",
padding=True
).to(model.device)
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs.get("attention_mask"),
max_new_tokens=max_new_tokens,
do_sample=do_sample,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
return outputs
# ======== 考生实现区域(可修改) ========
def generate_batch(
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer,
rendered_texts: List[str],
max_new_tokens: int,
do_sample: bool,
) -> List[torch.Tensor]:
# ======== 考生实现区域(可修改) ========
all_outputs = []
batch_size: int = 8
for i in range(0, len(rendered_texts), batch_size):
batch_texts = rendered_texts[i:i + batch_size]
batch_inputs = tokenizer(
batch_texts,
return_tensors="pt",
padding=True,
truncation=True,
).to(model.device)
batch_outputs = model.generate(
input_ids=batch_inputs["input_ids"],
attention_mask=batch_inputs.get("attention_mask"),
max_new_tokens=max_new_tokens,
do_sample=do_sample,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
all_outputs.append(batch_outputs)
return all_outputs
# ======== 考生实现区域(可修改) ========# -*- coding: utf-8 -*-
"""
仅此文件允许考生修改:
- 请在下列函数的函数体内完成实现。
- 不要改动函数名与参数签名。
- 你可以新增少量辅助函数。
"""
import torch # 引入 PyTorch 主包,用于张量运算与设备管理
import torch.nn.functional as F # 引入常用函数式 API,这里用于向量归一化
from transformers import AutoTokenizer, AutoModel # 引入 HF 分词器与模型基类
def _last_token_pool(last_hidden_states: torch.Tensor,
attention_mask: torch.Tensor) -> torch.Tensor:
"""
Last-token pooling
参数:
last_hidden_states: 模型输出的最后一层隐藏状态 (batch_size, seq_len, hidden_dim)
attention_mask: 注意力掩码 (batch_size, seq_len)
返回:
句向量 (batch_size, hidden_dim)
"""
# 判断是否使用了“左侧 padding”
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
# 左侧 padding:最后一个位置为有效 token
return last_hidden_states[:, -1]
else:
# 右侧 padding:找到每个样本最后一个有效 token 的索引
seq_lens = attention_mask.sum(dim=1) - 1 # (batch_size,)
batch_size = last_hidden_states.shape[0]
# 高级索引:对每一行取对应的最后有效 token 向量
return last_hidden_states[
torch.arange(batch_size, device=last_hidden_states.device),
seq_lens
]
def compute_similarity(text1: str,
text2: str,
model: AutoModel,
tokenizer: AutoTokenizer) -> float:
"""
计算两个文本之间的相似度(余弦相似度)
步骤:
1. 分词和编码
2. 获取模型输出
3. last-token pooling
4. L2 归一化
5. 向量点积作为余弦相似度
"""
# 获取模型所在设备(CPU/GPU)
device = next(model.parameters()).device
# 1. 编码
inputs = tokenizer(
[text1, text2], # 两个文本作为一个 batch
padding=True, # 自动 padding
truncation=True, # 超长截断
max_length=8192, # 为长文本模型预留的较大长度
return_tensors="pt",
)
# 把所有输入迁移到模型设备上
inputs = {k: v.to(device) for k, v in inputs.items()}
# 2. 模型前向(无梯度)
with torch.no_grad():
outputs = model(**inputs)
# 3. last-token pooling
last_hidden_states = outputs.last_hidden_state
sentence_embeddings = _last_token_pool(
last_hidden_states, inputs["attention_mask"]
)
# 4. L2 归一化
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
# 5. 余弦相似度(单位向量点积)
similarity = (sentence_embeddings[0] @ sentence_embeddings[1]).item()
return similarityT2 第二部分涉及随机数学题目的生成,实现方式多样。只需确保生成的数据经过与第一部分类似的处理后,整体数据集的平均相似度控制在 0.5 以内即可。以下提供一种可行的实现方案:
import torch # 引入 PyTorch 主包,用于张量运算与设备管理
import torch.nn.functional as F # 引入常用函数式 API,这里用于向量归一化
from transformers import AutoTokenizer, AutoModel # 引入 HF 的自动分词器与自动模型基类
import random, json # 引入随机数与 JSON 序列化库(本文件主要用于构建/落盘数据集)
def generate_dataset(outfile="dataset.jsonl"):
"""
生成一个满足“答案为三位数”的四则运算数据集,并以 JSONL 形式落盘。
参数:
outfile (str): 输出文件名(位于脚本同级目录下的 data/ 子目录中)
返回:
dataset (list[dict]): 内存中的数据列表(每行包含 problem 与 answer)
"""
import os # 局部引入 os,避免污染外部命名空间
target_count = 1024 # 目标样本数量
# 选择推理设备:优先使用 GPU(cuda),否则回退到 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载嵌入模型与分词器
tokenizer = AutoTokenizer.from_pretrained(
"Qwen/Qwen3-Embedding-0.6B", trust_remote_code=True
)
model = AutoModel.from_pretrained(
"Qwen/Qwen3-Embedding-0.6B", trust_remote_code=True
).to(device)
model.eval()
ops = ['+', '-', '*', '/'] # 支持的四则运算符集合
def safe_calc(a, op, b):
"""
安全计算 a (op) b:
- 加减乘按常规返回整数
- 除法仅在 b!=0 且整除时返回整数,否则返回 None
"""
if op == '+':
return a + b
if op == '-':
return a - b
if op == '*':
return a * b
if b == 0 or a % b != 0:
return None
return a // b
def build_binary():
"""
构造二元四则运算表达式,要求结果三位数。
"""
for _ in range(200):
op = random.choice(ops)
if op == '+':
a = random.randint(10, 550)
b = random.randint(10, 550)
elif op == '-':
a = random.randint(200, 1400)
b = random.randint(10, a - 100)
elif op == '*':
a = random.randint(10, 99)
b = random.randint(10, 99)
else:
result = random.randint(100, 999)
b = random.randint(2, 12)
a = result * b
result = safe_calc(a, op, b)
if result is None or result < 100 or result > 999:
continue
return f"{a} {op} {b}", str(result)
return None
def build_ternary():
"""
构造三元(带括号)四则运算表达式。
"""
for _ in range(400):
op1, op2 = random.choice(ops), random.choice(ops)
nums = [random.randint(10, 120) for _ in range(3)]
if random.choice([True, False]):
first = safe_calc(nums[0], op1, nums[1])
if first is None:
continue
result = safe_calc(first, op2, nums[2])
expr = f"({nums[0]} {op1} {nums[1]}) {op2} {nums[2]}"
else:
second = safe_calc(nums[1], op2, nums[2])
if second is None:
continue
result = safe_calc(nums[0], op1, second)
expr = f"{nums[0]} {op1} ({nums[1]} {op2} {nums[2]})"
if result is None or result < 100 or result > 999:
continue
return expr, str(result)
return None
serialize = lambda entry: json.dumps(entry, ensure_ascii=True)
dataset, dataset_texts = [], []
used_problems = set()
rejected_problems = set()
max_attempts = target_count * 500
attempts = 0
emb = [] # 保存已接受样本 embedding 向量
while len(dataset) < target_count and attempts < max_attempts:
attempts += 1
builder = build_ternary if random.random() < 0.4 else build_binary
candidate = builder()
if candidate is None:
continue
problem, answer = candidate
if problem in used_problems or problem in rejected_problems:
continue
entry = {"problem": problem, "answer": answer}
entry_text = serialize(entry)
inputs = tokenizer(
entry_text,
padding=True,
truncation=True,
max_length=8192,
return_tensors="pt",
)
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
sentence_embeddings = _last_token_pool(
last_hidden_states, inputs["attention_mask"]
)
entry_vec = (
F.normalize(sentence_embeddings, p=2, dim=1)
.squeeze(0)
.detach()
.cpu()
)
too_similar = False
for text_emb in emb:
similarity = torch.dot(entry_vec, text_emb).item()
if similarity > 0.5:
too_similar = True
break
if not too_similar:
emb.append(entry_vec)
used_problems.add(problem)
dataset.append(entry)
dataset_texts.append(entry_text)
if len(dataset) < target_count:
raise RuntimeError("Unable to generate dataset that satisfies similarity constraints.")
data_dir = os.path.join(os.path.dirname(__file__), "data")
os.makedirs(data_dir, exist_ok=True)
dataset_path = os.path.join(data_dir, outfile)
with open(dataset_path, "w", encoding="utf-8") as f:
for item in dataset:
f.write(json.dumps(item, ensure_ascii=True) + "\n")
return dataset
# 直接运行脚本时执行
generate_dataset()从 https://huggingface.co/ 下载 Qwen3-0.6B 与 Qwen3-Embedding-0.6B 两个模型至本地。
由于 Hugging Face 位于境外,网络访问可能受限导致下载缓慢。可选用国内镜像站点结合迅雷工具进行加速(适用于不熟悉 git 操作的用户),参考教程链接:
https://juejin.cn/post/7541297378126921769此外,也支持通过百度网盘获取资源:
https://pan.baidu.com/s/1NRZ1jpw2zMS8UfQvv9EMAA?pwd=1234下载完成后,请将 Qwen/Qwen3-0.6B 文件夹放置于 T1 目录下,与 submission.py 处于同一层级;将 Qwen/Qwen3-Embedding-0.6B 放置于 T2 所在目录中。
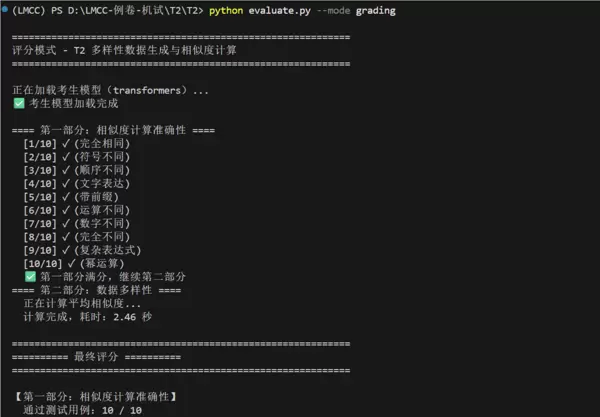
在同级目录下运行以下三条命令中的任意一条,即可执行本地评测:
python evaluate.py
python evaluate.py --mode demo
python evaluate.py --mode grading

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




