经管之家App
让优质教育人人可得
立即打开


IO分层架构解析
在数据处理系统中,存储IO常常成为性能瓶颈。由于IO处理能力的发展速度远落后于CPU和内存的提升,因此诸如Memcached、Redis等技术被广泛用于规避或缓解IO带来的延迟问题,从而提升整体系统效率。
典型的IO系统可分为三个主要层次:文件系统、卷管理(VM)以及底层的磁盘存储设备。其结构如下:
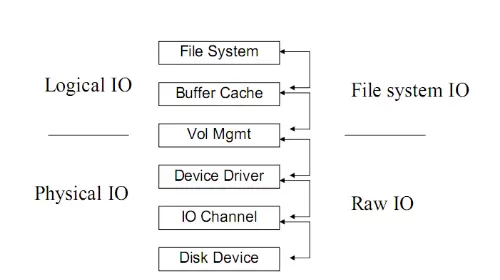
逻辑IO是由操作系统发起的IO请求,目标数据可能来自磁盘,也可能命中文件系统的缓存(如PageCache),并不一定触发实际的磁盘访问。
而物理IO则是由设备驱动发出,真正作用于磁盘设备的操作,意味着数据必须完成从内存到持久化介质的传输。
两者之间并非一一对应关系——一个逻辑IO可能转化为多个物理IO,也可能因缓存命中而不产生任何物理IO。
当应用层发起一次针对磁盘上1GB连续数据的读取请求时,该请求在经过操作系统和底层硬件处理过程中是否会被拆分?答案取决于多层机制的协同作用。
在OS层,请求是否被拆分主要受I/O模式和系统策略的影响:
此外,以下因素也会影响拆分行为:
无论上层如何处理,进入物理层后,请求必然被拆分为固定大小的数据块:
数据在传输过程中依赖总线(如SATA或PCIe)进行串行或并行传送,受限于总线宽度(如64位)和协议限制,无法一次性处理如此庞大的数据单元。
DMA控制器虽能减轻CPU负担,实现内存与磁盘间的直接数据搬运,但也必须按照对齐的块大小(如4KB)分段传输,确保与底层扇区结构匹配。
各类IO处理过程在本质上具有一致性,均可归纳为两个核心阶段:等待与服务,即排队和执行。
IO请求往往需要独占特定资源(如磁盘、内存、文件句柄等)。若这些资源正被其他进程占用且未释放,当前请求将被阻塞,直至资源可用为止。
在此阶段,根据应用程序的行为方式,IO可分为阻塞与非阻塞两种模式:
总体来看,所有IO处理模型的设计目标都是在资源约束下最大化吞吐、降低延迟,并平衡CPU与IO设备之间的协作效率。
在进行IO操作时,应用程序的行为方式可以分为阻塞与非阻塞两种模式。非阻塞IO指的是当发起一个IO请求后,系统不会让程序停下来等待结果,而是立即返回状态信息。若操作尚未完成,应用可继续执行其他任务,并通过轮询机制持续检查IO的完成情况,直至操作结束。
在实际的数据传输阶段——即数据的接收与发送过程中,IO模型又可分为同步和异步两种类型:
同步IO要求应用程序在发出IO指令后必须等待该操作彻底完成才能继续后续处理。这意味着线程会被挂起,直到操作系统返回最终结果。尽管这种方式编程逻辑清晰、实现简单,但效率较低,尤其在高并发场景下容易造成资源浪费。
而异步IO则允许应用在提交IO请求后立刻获得控制权,无需等待操作完成。系统会在底层完成数据读写后,主动通知应用程序并交付结果。这种机制提升了整体吞吐能力,但由于需要处理回调或事件分发,增加了程序设计的复杂度。
从特点角度来看:
阻塞IO虽然使用直观,但存在明显的性能瓶颈:每个连接通常需要独占一个线程。以Java的传统BIO为例,每建立一个Socket连接就要分配一个线程,大量空闲线程的存在导致资源消耗严重,极易引发线程膨胀问题。
相比之下,非阻塞IO通过轮询机制避免了线程长时间阻塞。Java NIO正是基于此原理,利用select等多路复用技术,使单个线程能够监听多个Socket连接,显著减少了线程数量,提高了系统可扩展性。
同步IO无论是在BIO还是NIO中都被广泛采用,其核心特征是“操作结束才返回”,虽保障了流程顺序性,但也限制了并发效率。
异步IO将IO过程拆解为请求发起与结果获取两个阶段,数据先写入缓冲区,是否成功落盘由系统后续完成并通知。虽然这带来了更高的性能潜力,尤其是在高负载环境下表现优异,但对开发者而言,错误处理、状态管理和内存控制变得更加复杂。
在Linux操作系统中,磁盘I/O并不具备绝对意义上的并行执行能力,主要受限于硬件物理特性(如HDD磁头移动)以及共享资源的协调需求。然而,通过多层次的技术整合,系统仍能实现高度的并行化处理效果。
现代Linux借助先进的硬件协议支持(如NVMe)、内核调度优化(如blk-mq、io_uring)以及合理的应用层设计,在多核CPU与SSD环境中几乎逼近硬件极限,充分发挥出存储设备的并发潜力。
NVMe协议为固态硬盘提供了强大的并行基础。它支持极深的命令队列(可达64K深度)和多队列架构,使得大量I/O请求可以同时提交。更重要的是,每个CPU核心可绑定独立的硬件队列,从而实现真正意义上的硬件级并发处理。
此外,多通道SSD内部结构允许多个NAND闪存通道并行工作,可在物理层面上同时处理多个读写请求。不过,当总负载超过通道承载能力时,依然会出现资源竞争和排队现象。
Linux内核引入了块设备多队列框架(blk-mq),将I/O请求动态分发至多个硬件队列,有效消除传统单一队列带来的锁争用问题,大幅提升多核环境下的并行效率。
在异步I/O模型方面,io_uring提供了一种高性能解决方案。它采用环形缓冲区结构,实现用户态与内核态之间的无锁通信,大幅减少上下文切换开销。配合轮询模式(polling mode),甚至可以绕过中断机制,达到超低延迟的并行处理效果。
传统的AIO(内核级异步I/O)也支持异步提交请求,但在实践中面临回调管理复杂、缓冲区对齐要求高等限制,影响了其实用性。
文件系统的并发控制同样影响整体I/O性能。例如ext4和XFS这类日志型文件系统通过批量提交写日志来提升效率,但在元数据更新时仍需短暂加锁。而像Btrfs这样的新型文件系统则通过细粒度的子树锁机制,进一步增强了并发写入能力。
graph LR
[应用层发起I/O请求]
-->> [内核I/O子系统处理]
-->>{进入OS I/O队列排队}
-->> [驱动层转发至存储设备]
-->>[存储设备物理操作]
-->> [数据返回至应用层]为了最大化利用底层硬件能力,应用程序常采用多线程或多进程方式进行I/O操作。当不同线程访问不同的文件或同一文件的不同区域时,能够充分调动硬件队列深度,实现接近理想的并行读写。
Direct I/O是一种绕过页缓存(Page Cache)的直接访问方式,适用于那些自行管理缓存的高性能数据库系统(如PostgreSQL)。它避免了内核缓存带来的锁竞争,有助于提升大规模并发场景下的稳定性与响应速度。
分散-聚集I/O(Scatter/Gather)则通过readv()和writev()系统调用,允许一次操作涉及多个非连续内存区域,从而减少系统调用次数,提高数据传输效率。
尽管有诸多优化手段,I/O并行仍面临以下几类主要限制:
共享资源竞争:多个进程同时写入同一个文件时,必须依赖文件锁(如fcntl)或日志协调机制,导致部分操作被迫串行化。
硬件瓶颈:机械硬盘由于磁头寻道和盘片旋转的物理限制,本质上只能串行处理请求;而SSD虽然拥有多个并行通道,但带宽有限,过载时仍会产生排队延迟。
元数据操作的串行性:诸如创建、删除文件或修改权限等操作往往涉及全局锁(如inode锁),这些关键路径天然不具备并行执行条件。
总体来看,存储设备的I/O并行能力受到硬件架构、协议设计及资源共享机制的共同制约。尽管无法实现完全的同时执行,但通过NVMe多队列、blk-mq调度、io_uring异步接口等技术组合,已能在现实场景中达成高度有效的并发处理。
[此处为图片3]衡量存储系统性能的关键在于三个核心指标:IOPS、IO响应时间与吞吐量。这些指标共同决定了系统在不同应用场景下的表现能力。
IOPS(Input/Output Operations Per Second)表示每秒钟能够完成的I/O请求数量,通常用于读取或写入数据的操作统计。对于频繁进行随机读写的场景,如小文件存储(例如图片服务)、OLTP数据库以及邮件服务器等,IOPS是评估性能的重要依据。
传统机械硬盘(HDD)在执行I/O操作时,主要受限于以下几个时间因素:
以一块15,000 RPM的机械硬盘为例,平均寻道时间为4ms,旋转延迟约为2ms,总延迟约6ms。据此估算最大理论IOPS为:1000ms ÷ 6ms ≈ 167 IOPS。而在相同接口条件下,SATA SSD和NVMe SSD由于无机械部件,访问延迟极低,IOPS显著提升。
| 硬盘类型 | 典型IOPS(4K随机) | 响应时间 | 接口/协议 |
|---|---|---|---|
| HDD (7,200 RPM) | 50~200 | 5~20 ms | SATA/SAS |
| SATA SSD | 读: 50K~100K 写: 20K~80K |
0.05~0.3 ms | SATA 3.0 (6 Gbps) |
| NVMe SSD (消费级) | 读: 200K~500K 写: 150K~400K |
0.02~0.1 ms | PCIe 4.0/5.0 |
| NVMe SSD (企业级) | 读: 500K~1.5M+ 写: 300K~800K+ |
<0.1 ms | PCIe 4.0/5.0 |
IOPS的实际表现受到多种软硬件层面因素的影响,主要包括:
由于上述因素交织作用,实际IOPS值难以通过理论精确预测,通常需结合具体业务场景进行实测验证才能获得准确结果。
IO响应时间指从操作系统内核发出I/O请求开始,到接收到存储设备返回响应为止的整个耗时周期。该指标直接影响用户体验和事务处理效率。
在OLTP类系统中,普遍认为10ms以内的响应时间为较优实践标准。现代NVMe SSD的响应时间可低至0.02ms以下,远优于传统HDD的毫秒级延迟。
吞吐量代表单位时间内成功传输的数据总量,常以MB/s或GB/s为单位,类似于网络带宽概念。它反映的是系统在连续读写大文件时的数据搬运能力,适用于视频流、大数据分析等顺序I/O密集型应用。
尽管现代SSD(尤其是NVMe架构)支持高度并行的I/O处理,但“绝对并行”并不存在,其性能仍受限于多个层次的约束:
NVMe SSD通过多队列机制(每个CPU核心绑定独立队列)实现高并发I/O处理,企业级产品可达百万级IOPS。然而,这种并行能力受限于控制器算力和物理通道数量,无法无限扩展。
SSD内部采用多通道并行访问NAND闪存芯片,理论上可提升整体吞吐。但在实际运行中,写入放大效应、垃圾回收(GC)过程及磨损均衡算法会中断正常的并行数据流,造成性能波动。
SSD控制器需要同时处理来自多个主机队列的请求,执行FTL(Flash Translation Layer)地址映射,并协调各个闪存通道的读写操作。在高负载情况下,控制器本身可能成为性能瓶颈。
综上所述,并行性是一种有限的优化手段,而非无条件成立的特性。真正的高性能I/O系统需综合考虑硬件能力、协议设计、操作系统调度与应用模式之间的协同关系。
在存储性能分析中,不同大小的IO请求对速度的影响存在明显差异。例如,一个8K的IO操作由于数据量较小,读取所需时间更短,因此会比一个64K的IO更快完成。
然而,当对比单个64K IO与八个8K IO时,前者通常表现更优。这是因为虽然总数据量相同,但单次IO请求只需一次完整的系统调用和设备操作流程,而后者需要发起八次独立的IO操作,带来更高的上下文切换、调度开销和协议处理延迟。
graph LR
[应用层发起I/O请求]
-->> [内核I/O子系统处理]
-->>{进入OS I/O队列排队}
-->> [驱动层转发至存储设备]
-->>[存储设备物理操作]
-->> [数据返回至应用层]应用层请求提交阶段:
该阶段主要涉及用户态到内核态的系统调用开销,如执行read()或write()函数时发生的上下文切换时间。
内核I/O调度与队列等待:
这是影响延迟的关键瓶颈之一。IO请求在操作系统I/O队列中的等待时间随队列深度非线性增长——尤其当系统负载超过70%后,延迟会出现显著飙升。
此外,还包括文件系统的元数据锁竞争、日志提交开销,以及块设备层采用的调度策略(如CFQ)所带来的额外处理时间。
驱动层传输阶段:
此阶段涵盖协议封装过程(例如SCSI命令转换)、数据从主机传输至HBA控制器的时间,以及总线本身的传输延迟(如PCIe通道带来的时延)。
存储设备物理操作阶段:
对于HDD设备,主要包括:
- 寻道时间(磁头移动:3–15ms)
- 旋转延迟(盘片转动:2–8ms)
- 数据传输时间(约0.1ms级)
对于SSD设备,则包括:
- NAND闪存电荷读写延迟(约50–150μs)
- 控制器处理时间
- FTL(Flash Translation Layer)映射表查询开销
关键观察点:
- 队列等待是延迟中最不稳定的变量,尤其在高负载环境下,可能造成延迟成倍上升;
- 协议设计差异显著影响性能,NVMe通过去除传统SCSI等中间协议层,并支持更深的并行队列,可将驱动层延迟压缩至传统协议的十分之一以下;
- TLC/QLC类型的SSD在垃圾回收过程中可能出现写放大效应,导致写入延迟突发性升高至毫秒级别。
| 阶段 | HDD延迟 | SATA SSD延迟 | NVMe SSD延迟 |
|---|---|---|---|
| OS队列等待(满载) | 5~50 ms | 0.1~2 ms | 0.02~0.3 ms |
| 设备物理操作 | 5~20 ms | 0.05~0.3 ms | 0.01~0.1 ms |
| 端到端总延迟 | 10~70 ms | 0.1~3 ms | 0.03~0.5 ms |
吞吐量表示系统在单位时间内能够传输的最大数据量,它是一个理论上限值,而非动态变化指标。该参数在顺序访问或大块数据连续读写的场景下尤为重要,特别是在大数据量写入任务中尤为关键。
典型关注吞吐量的应用包括:
这些应用场景以连续的大数据流读写为主,其性能往往可以逼近硬件吞吐能力上限。相比之下,随机小IO操作常因IOPS先达到极限,无法充分发挥吞吐潜力。
相较于IOPS受多种动态因素影响,吞吐量受限于较为固定的硬件条件,主要包括:
实际吞吐量通常由上述环节中最薄弱的一环决定。
阵列架构:
现代存储阵列多采用光纤通道架构,其内部具有类似PC系统总线的“内部带宽”。尽管各厂商设计不同,但一般内部带宽都足够充裕,较少成为性能瓶颈。
光纤通道容量:
在数据仓库等高流量需求环境中,光纤卡带宽至关重要。例如:
硬盘数量与性能:
当其他环节不再构成限制时,硬盘本身成为决定性因素。以下是不同类型硬盘的大致持续传输速率:
| 硬盘类型 | 10K rpm | 15K rpm | ATA |
|---|---|---|---|
| 持续吞吐率 | 10 MB/s | 13 MB/s | 8 MB/s |
举例说明:
若某存储阵列配备120块15K rpm光纤硬盘,则理论上最大支撑流量为:
120 × 13 MB/s = 1560 MB/s
对应所需光纤卡数量:
- 使用2Gb卡:至少需6块(每块250MB/s)
- 使用4Gb卡:仅需3–4块即可满足
不同的业务场景应关注不同的性能指标,某些指标在特定情境下可能不具备参考价值。
随机访问场景 —— 关注IOPS:
在此类应用中,IO请求分布零散,IOPS容易成为系统瓶颈。此时即使吞吐量远未达到理论峰值,系统也可能已不堪重负。
顺序访问场景 —— 关注吞吐量:
此类应用以连续大块数据读写为主,吞吐量易达到硬件上限(受限于磁盘性能或传输带宽),而IOPS数值则相对较低。
IOPS与IO响应时间密切相关。通常情况下:
当IOPS接近存储设备理论最大值时,IO响应时间会呈现非线性增长,实际延迟将远超预期。在实际应用中,通常采用70%作为性能预警阈值——即当系统IO负载超过其最大承载能力的70%时,就必须考虑优化或硬件升级。值得注意的是,该经验法则同样适用于CPU使用率监控:一旦CPU利用率持续高于70%,系统整体响应速度将显著下降,用户体验急剧恶化。
不同监控工具所反映的指标存在差异:
指单次IO请求所涉及的数据量大小。一个完整的IO过程从请求发出开始,直至数据返回结束。IO Chunk Size与具体应用和业务逻辑密切相关。以Oracle数据库为例,其默认block size为8KB,读写操作均以此为单位,因此该系统的典型IO Chunk Size即为8KB。
不同的IO块大小对系统性能要求不同:
类似于数据库支持批量提交SQL语句以提升效率,IO请求也可以累积多个操作后一次性提交至存储层。这种方式有助于合并相邻的数据块访问,减少物理IO次数,提高整体效率。Queue Depth正是用于控制同时提交的IO请求数量,通常在IO驱动层面进行配置。
Queue Depth与IOPS密切相关。只有在IOPS成为系统瓶颈的情况下,增加队列深度才有明显意义;若系统已受限于大IO下的磁盘吞吐能力,则提升Queue Depth效果有限。一般情况下,随着Queue Depth增大,IOPS峰值也会有所上升,但增幅并不显著,实践中建议值通常不超过256。
随机IO的特点是每次请求的数据分布在磁盘的不同位置(如多个离散扇区),因此即便请求的是极小数据块(如1KB),也需要发起多次独立IO操作来完成读取。
而顺序IO则相反,请求的数据在存储介质上连续分布。当系统发起多个小IO请求时,由于单次IO本身具有开销,系统往往会预读更大块的数据(如4KB或8KB)。这意味着首次IO完成后,后续请求的数据可能已经加载完毕,从而减少了总的IO次数——这就是所谓的“预取”机制。
IO模式由上层应用决定:
传统机械硬盘在连续读写方面表现优异,但在随机读写场景下性能较差。原因在于磁头需要花费大量时间移动到目标磁道,频繁的寻道操作导致有效数据传输时间被严重压缩,整体性能低下。
大多数文件系统默认采用缓存IO机制。在Linux系统中,数据首先从磁盘复制到内核空间的缓冲区,再从缓冲区拷贝至用户应用程序地址空间。
读操作流程:系统先检查内核缓冲区是否已缓存所需数据,若有则直接返回;否则从磁盘读取并缓存后再提供给应用。
写操作流程:数据先被复制到内核缓冲区,此时即向用户程序返回写入成功状态,后续由操作系统决定何时将数据真正落盘,除非显式调用sync命令强制同步。
优点:
缺点:在数据传输过程中,无法实现用户空间与磁盘之间的直接传输。即使使用DMA技术可将数据从磁盘搬移到页缓存或反向写回,仍需经历多次内存拷贝过程。这些额外的数据复制带来了显著的CPU占用和内存资源消耗。
直接IO允许应用程序绕过内核缓冲区,直接与磁盘交互数据,避免了从内核缓存到用户空间的二次复制开销。这类机制常见于数据库管理系统等专业软件,因其往往具备比通用操作系统更精准的数据访问模式认知,能够设计出更高效的自定义缓存策略,从而优化整体数据读写性能。
缺点:如果所需数据未存在于应用层缓存中,每次都会触发直接磁盘读取,效率较低。因此,直接IO通常与异步IO结合使用,以获得更好的并发处理能力和系统响应性。异步IO允许线程在发出IO请求后立即继续执行其他任务,而非阻塞等待结果返回。
rpm(Revolution Per Minute)表示每分钟的转数,指的是磁盘在单位时间内旋转的圈数。这一参数对磁盘的数据读取速度有重要影响。常见的磁盘转速包括5400转/分、7200转/分、10000转/分以及15000转/分等。
寻道时间(Tseek)是指将读写磁头移动到目标磁道所需的时间。该时间越短,磁盘进行I/O操作的速度就越快。目前主流磁盘的平均寻道时间通常介于3ms至15ms之间。
不同转速硬盘的典型物理寻道时间如下:
旋转延迟(Trotation)指盘片旋转至请求数据所在的扇区到达读写磁头下方所需的时间。该延迟与磁盘转速密切相关,通常以旋转一周所需时间的一半来估算平均延迟。
例如:
graph LR
[应用层发起I/O请求]
-->> [内核I/O子系统处理]
-->>{进入OS I/O队列排队}
-->> [驱动层转发至存储设备]
-->>[存储设备物理操作]
-->> [数据返回至应用层]数据传输时间(Ttransfer)是完成所请求数据传输所需的时间,其长短取决于数据传输速率。计算公式为:传输时间 = 数据大小 ÷ 数据传输率。当前IDE/ATA接口的传输率可达133MB/s,而SATA II接口则可达到300MB/s。由于这部分耗时通常远小于寻道时间和旋转延迟,在粗略估算中常可忽略不计。
磁盘服务时间是指磁盘完成一次I/O请求所需的总时间,由三部分组成:寻道时间、旋转延迟和数据传输时间。
单块磁盘理论最大IOPS的计算方式如下:
IOPS = 1000 ms / (寻道时间 + 旋转延迟)
由于数据传输时间相对较短,一般在计算中予以忽略。
根据上述公式,不同转速磁盘对应的理论最大IOPS分别为:
[此处为图片3]

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




