经管之家App
让优质教育人人可得
立即打开


随着大模型从演示阶段逐步迈向实际生产应用,核心挑战已不再局限于“是否拥有强大的基础模型”,而更多聚焦于“能否高效、稳定地将模型能力转化为可落地的业务价值”。正是在这一背景下,ModelEngine 应运而生——它是一个专注于实现 数据 → 模型 → 应用 全链路工程化的平台。
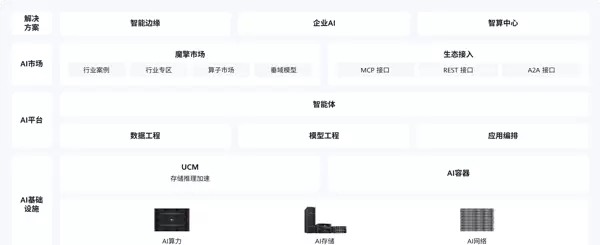
该平台不仅支持数据清洗与知识库构建,还涵盖模型管理、推理服务部署,并提供可视化应用编排及智能体开发能力。整体技术架构可划分为以下三层:
基于上述能力体系,围绕 ModelEngine 可深入探索以下几个关键方向:
接下来,我们将以一条标准化的“标品级”实施路径为切入点,逐步解析其应用逻辑。
本部分将以一个典型企业场景——「内部智能知识助理」为例展开说明。目标是让员工通过自然语言对话查询公司制度、操作流程和技术文档,并能触发自动化任务(如撰写邮件、生成会议纪要等)。
许多团队在初期容易将智能体误解为简单的问答系统。然而,在工程实践中,更准确的理解应为:
智能体 = 具备记忆能力、工具调用权限、环境感知能力和任务规划逻辑的自治执行单元。
在企业知识助理的构建中,需重点打造以下三大核心能力:
在 ModelEngine 平台上,知识库的构建遵循一套标准化流程:
1. 原始数据归集
收集来自不同系统的非结构化文档,包括但不限于:
2. 数据清洗与智能切分
利用平台内置的数据处理算子进行预处理:
系统可根据每个文本片段自动产出多个问答对,并通过内建的质量评分机制进行筛选。用户可设定“保留阈值”(如 0.8 分以上),仅保留高置信度样本。
模拟项目效果示例①(数据清洗与 QA 对生成)
注:以上为模拟项目数据,旨在展示类似配置下企业在 ModelEngine 上可达到的典型处理规模与输出质量。
在知识库建设过程中,有两个关键决策点:
Embedding 模型与向量数据库选型
根据实际需求选择合适的嵌入模型:
检索策略调优
通过参数配置优化召回效果:
借助 ModelEngine 的数据处理节点与应用编排能力,这些策略可通过配置化方式持续迭代,最终形成一条可观测、可调节的 RAG 流水线,避免陷入黑盒式问答的困境。
提示词(Prompt)是决定智能体表现的核心要素之一。当需要维护多个智能体时,手工编写和管理提示词极易失控。因此,推荐建立“提示词自动生成 + 效果评测反馈”的闭环机制。
基础实现方式是将提示词拆解为结构化模块:
针对不同类型的 Agent,可通过参数注入方式复用同一模板,实现快速扩展与统一管理。
你是公司【${dept_name}】的【${agent_role}】助手,主要服务对象为【${target_user}】。
你的职责包括:${duties}
输出时,请严格遵守如下格式与约束:${format_constraints}平台支持基于已有知识库和任务描述,由大模型自动生成初步的提示词草稿,大幅降低人工编写负担。后续结合真实场景测试结果,持续迭代优化,形成动态演进的提示词管理体系。
在 ModelEngine 的应用架构中,可以设计一个“提示词生成工作流”,以实现高效、标准化的智能体开发流程。 **输入内容包括:** - 用自然语言描述的业务需求; - 若干条样例对话; - 明确的目标输出格式要求。 该工作流的主要执行步骤如下: 首先调用大模型,结合预设的系统提示与提供的样例,自动生成一版完整的提示词。随后通过规则引擎或轻量级判别模型,自动检测生成的提示词是否涵盖关键要素,如角色设定、约束条件、拒绝响应策略等。为支持后续评估,系统会进一步生成 A/B 两个版本,用于在线对比测试。
最终,将确认可用的提示词版本写入“提示词仓库”——可为数据库或统一配置中心,并打上对应版本标签,便于追踪和管理。
---
**模拟官方数据示例②:提示词自动生成带来的效率提升**
在一个涉及 18 个业务智能体的实际项目中:
- 传统方式下,每个 Agent 的提示词需人工反复打磨,平均耗时 2–3 小时;
- 引入自动化生成与评测流程后,每个 Agent 的“可用版本”提示词生成时间缩短至 25 分钟以内;
- 综合测算显示,提示词相关的人力投入减少了约 65%。
这表明,通过结构化流程替代手工编写,显著提升了研发效率与一致性。
---
### 2.4 智能体开发与调试:从配置走向工程化
在 ModelEngine 平台上构建智能体,通常包含以下几个核心阶段:
**基础配置阶段:**
- 选择底层模型类型(如大语言模型或多模态模型);
- 关联相应的知识库资源;
- 设置记忆机制,例如会话级记忆、长期记忆或无记忆模式。
**工具与 MCP 服务集成:**
- 接入企业内部 REST API 接口;
- 集成基于 MCP(Model Context Protocol)协议的服务,实现对工具、数据库及第三方系统的标准访问;
- 对各类工具设置权限控制与调用频率限制,保障系统稳定性与安全性。
**多智能体协作拓扑设计:**
- 设计“协调者 Agent”(Planner),负责任务分解与流程调度;
- 配置多个“执行者 Agent”(Executor),例如:
- 文档解析 Agent;
- 知识检索与问答 Agent;
- 邮件内容生成 Agent;
- 审核决策 Agent。
**可视化调试与日志监控:**
- 在图形化编排界面中查看各节点的输入与输出;
- 对关键环节进行可视化展示,如检索结果、外部工具返回值、Agent 中间推理过程,帮助识别“幻觉”或错误调用;
- 自动聚合失败案例并记录日志,形成闭环反馈机制,支撑持续优化。你是公司【${dept_name}】的【${agent_role}】助手,主要服务对象为【${target_user}】。
你的职责包括:${duties}
输出时,请严格遵守如下格式与约束:${format_constraints}在工作流体系中,每个节点或分支通常代表一个具体的功能单元,开发者可以直观查看“前序节点的输入”与“当前节点的输出”之间的数据流转关系。
许多常见业务场景可被抽象为标准化的“子流程”或“组件化工作流”,例如:
基于12个典型业务流程进行评估:
典型实施路径包括:
该模式的核心价值体现在:
智能表单是极具代表性的高效实践之一,具备以下能力:
典型案例:“需求收集与排期助手”:
以下是围绕 ModelEngine 的智能体与流程编排能力打造的三组真实应用场景,均可直接用于方案阐述。
目标:显著降低知识检索与文档处理的时间成本。
核心功能:
目标:让智能体不仅能够“回答问题”,更能“执行事务”。
实践架构:
| 指标 | 上线前 | 上线后(试运行8周) |
|---|---|---|
| 人工客服占比 | 100% | 42% |
| 一次性解决率(含智能体) | 71% | 89% |
| 单笔工单平均处理时长 | 9.5 分钟 | 3.2 分钟 |
| 用户满意度(5分制) | 3.8 | 4.6 |
应用场景:市场与运营团队希望借助大模型获取数据洞察并辅助内容生产,但缺乏 SQL 编写能力。
解决方案:
在工程实践中,真正决定平台能否长期支撑企业级应用的,往往是那些“看似平淡却至关重要”的底层能力。
ModelEngine 提供了基于 SDK 的多语言插件开发能力,支持 Java、Python 等主流语言,便于将企业内部服务与第三方系统无缝接入统一的流程编排体系。
实践亮点包括:
面对复杂任务场景,平台采用“编排层 + Agent 层”的双层架构设计:
编排层职责:
Agent 层职责:
为避免多智能体之间产生资源冲突或引发不可控成本,实际工程中总结出以下有效经验:
你是公司【${dept_name}】的【${agent_role}】助手,主要服务对象为【${target_user}】。
你的职责包括:${duties}
输出时,请严格遵守如下格式与约束:${format_constraints}面向企业上云的实际需求,平台需解决的核心问题涵盖以下几个方面:
多源工具统一集成:
安全与权限管控:
监控与可观测性建设:
本部分从开发者角度出发,对 ModelEngine 与其他主流平台进行对比分析。参考公开资料,简要概括各平台定位:
基于上述信息,结合模拟项目中的使用体验,对各平台进行主观评分(满分 5 分):
| 维度 | ModelEngine | Dify | Coze | Versatile |
|---|---|---|---|---|
| 可视化应用编排 | 4.8 | 4.7 | 4.2 | 4.6 |
| 智能体/Agentic 支持 | 4.6 | 4.8 | 4.3 | 4.7 |
| 知识库与 RAG 能力 | 4.7 | 4.8 | 4.0 | 4.5 |
| 插件与工具集成 | 4.6 | 4.7 | 4.4 | 4.8 |
| 企业级能力(权限、安全) | 4.7 | 4.3 | 4.0 | 4.9 |
| 多云/本地化部署灵活性 | 4.6 | 4.5 | 3.8 | 4.8 |
| 面向非技术用户友好度 | 4.3 | 4.5 | 4.8 | 4.2 |
说明:

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




