经管之家App
让优质教育人人可得
立即打开


随着高等教育普及程度不断提升,高校毕业生人数逐年增长,就业形势日益复杂。如何科学分析大学生毕业去向、就业行业分布、薪资水平以及专业与学历对就业的影响,成为教育管理部门、高校及学生个人关注的重点问题。传统的统计方式在面对海量、多源、异构的就业数据时,往往存在处理效率低、分析维度单一等问题。
为此,构建一个高效、智能的数据分析平台显得尤为重要。本系统依托 Hadoop 分布式存储与 Spark 高速计算能力,结合 Python 强大的数据处理生态,设计并实现了一套完整的大学生毕业就业数据处理与可视化解决方案。该系统不仅提升了数据分析的实时性与准确性,还通过丰富的图表展示形式增强了结果的可读性与决策支持价值,为高校优化专业设置、调整人才培养方案提供了数据依据,同时也为学生个体的职业规划提供参考方向。
本系统以 Hadoop 和 Spark 作为底层大数据处理框架,采用 Python 为主要开发语言,后端使用 Django 框架进行服务构建,前端则基于 Vue.js 搭配 ElementUI 组件库与 Echarts 图表工具实现交互式数据可视化。整体架构覆盖从数据采集、清洗、分析到结果呈现的完整流程。
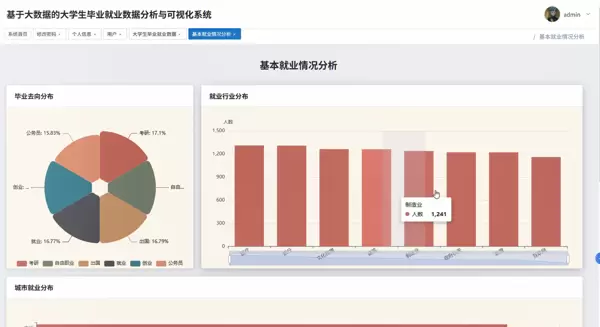
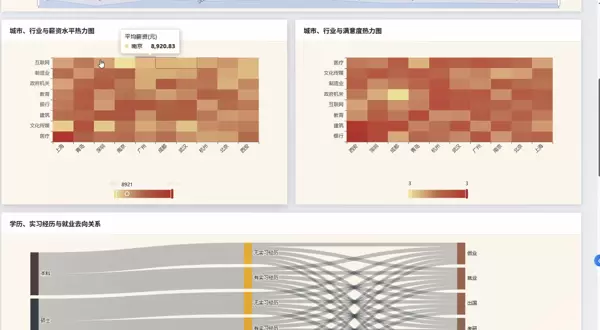
系统主要包含四大核心分析模块:就业基本情况分析、专业与就业关联性研究、学历层次对就业影响评估,以及多因素交叉综合分析。具体功能涵盖毕业去向分布统计(如升学、就业、创业、待业等)、就业岗位所属行业占比分析、不同专业类别下的平均薪资对比、学历与起薪之间的关系建模等。
在数据处理层面,利用 Spark SQL 完成大规模数据的抽取、转换与聚合操作;借助 Pandas 与 NumPy 进行精细化数值运算;分析结果持久化存储于 MySQL 数据库中,便于后续调用与更新。最终通过前端页面将各类柱状图、饼图、折线图、热力图等形式动态渲染,直观展现数据背后的趋势与规律,形成一套适用于计算机类专业毕业设计的大数据应用实践案例。
大数据处理框架:Hadoop + Spark(未使用 Hive,但支持定制扩展)
开发语言:Python、Java(双版本支持)
后端技术栈:Django(Python 版)、Spring Boot(Java 版,集成 Spring + SpringMVC + MyBatis)
前端技术栈:Vue.js、ElementUI、Echarts、HTML、CSS、JavaScript、jQuery
关键技术点:Hadoop、HDFS 分布式文件系统、Spark 核心计算引擎、Spark SQL 查询分析、Pandas 数据处理、NumPy 数值计算
数据库系统:MySQL
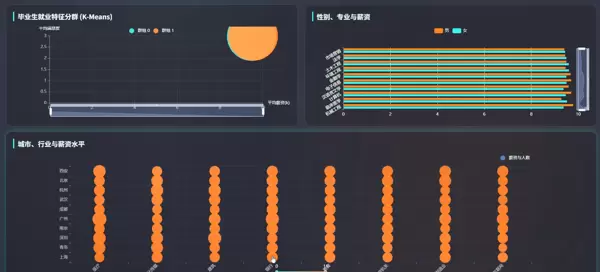
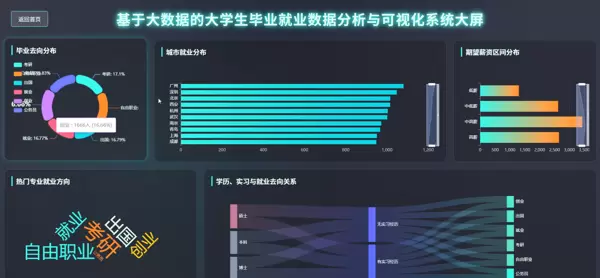
系统前端界面采用响应式布局,适配多种终端设备。主页面分为多个功能区域,包括导航栏、数据概览面板、图表展示区和筛选控件。用户可通过下拉菜单选择年份、地区、学历层次或专业类别,动态加载对应的数据视图。
图表类型丰富多样,包含但不限于:
所有图表均支持鼠标悬停查看详细数值、缩放和平移操作,提升用户体验与数据探索效率。
系统配套演示视频全面展示了从登录界面进入系统后,各项功能的操作流程与交互效果。视频内容包括数据筛选条件设置、图表自动刷新过程、后台任务执行状态监控、Spark 日志输出以及前后端数据通信机制等内容。
视频重点突出系统在处理百万级模拟就业数据时的响应速度与稳定性表现,验证了基于 Spark 的分布式计算在实际场景中的高效性。同时演示了异常数据过滤、空值填充、字段标准化等预处理步骤的实际运行情况,体现整个数据流水线的完整性与鲁棒性。
以下是系统中关键模块的部分示例代码,展示使用 Spark 进行数据清洗与聚合的基本流程:
# 使用 PySpark 加载原始数据
df = spark.read.csv("hdfs://localhost:9000/input/employment_data.csv", header=True, inferSchema=True)
# 数据清洗:去除缺失值、格式标准化
cleaned_df = df.dropna().filter(df.salary > 0)
# 使用 Spark SQL 进行分组统计:按专业统计平均薪资
cleaned_df.createOrReplaceTempView("employment")
avg_salary_by_major = spark.sql("""
SELECT major, AVG(salary) as avg_salary, COUNT(*) as total
FROM employment
GROUP BY major
ORDER BY avg_salary DESC
""")
# 将结果转为 Pandas DataFrame 并存入 MySQL
result_pd = avg_salary_by_major.toPandas()
import sqlalchemy
engine = sqlalchemy.create_engine("mysql+pymysql://user:password@localhost:3306/graduates")
result_pd.to_sql(name='major_salary_analysis', con=engine, if_exists='replace', index=False)
上述代码体现了从 HDFS 读取数据、Spark 清洗与分析、再到结果写入关系型数据库的典型链路,是整个系统数据处理流程的核心环节之一。
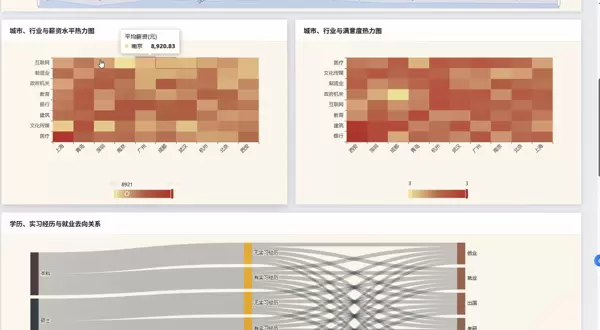
本系统围绕大学生毕业就业这一社会热点问题,融合 Hadoop 与 Spark 的强大数据处理能力,结合 Python 生态中的主流数据分析工具,构建了一个集数据采集、清洗、分析与可视化于一体的综合性平台。项目不仅具备较强的实用性与现实意义,也为计算机相关专业的毕业设计提供了可复用的技术框架与开发范式。
通过该项目的实践,开发者能够深入理解分布式系统的运作原理,掌握 Spark SQL 的查询优化技巧,熟悉前后端分离架构的协作模式,并积累真实场景下的大数据项目经验。未来可进一步引入机器学习模型预测就业趋势,或接入实时流数据进行动态监测,持续拓展系统的功能边界。
随着高校毕业生人数逐年上升,就业数据的规模和复杂性也在不断增加。教育机构及相关管理部门亟需一种更加高效、直观的方式来解读这些数据背后的规律与趋势。传统的数据处理手段,如使用Excel进行简单统计,已难以应对大规模数据集的分析需求,尤其在挖掘变量之间的关联性和进行深度分析方面存在明显局限。
对于计算机相关专业的学生而言,毕业设计不仅是对所学知识的综合运用,也是探索前沿技术实践路径的重要机会。当前,大数据技术因其强大的数据处理能力,成为许多学生选题时的优先方向。然而,在实际操作中,不少学生面临理论与实践脱节的问题:一部分人仅停留在概念理解层面,缺乏系统开发经验;另一部分人虽能实现基础功能,但系统结构单一,应用场景有限。
本课题正是基于上述背景提出,旨在构建一个面向大学生就业数据的分析与可视化系统。该系统融合了Hadoop与Spark等主流大数据处理框架,并结合Python语言进行数据清洗、分析及展示,力求在真实场景中落地应用。通过这一项目,不仅能够整合碎片化的就业信息,还能为学校提供可视化的决策支持工具,辅助教师快速掌握不同专业、学历层次学生的就业去向与薪资水平。
从学习目标来看,该项目有助于深入掌握大数据技术的实际应用流程。课堂上所学的知识多以理论为主,而通过亲手搭建完整的数据处理 pipeline——包括使用 Spark 进行分布式计算、利用 Echarts 实现前端图表渲染——可以显著提升工程实践能力。这种从数据采集、处理到可视化输出的全流程训练,对未来从事数据分析、数据工程等相关岗位具有积极意义。
系统具备多项核心分析功能,例如毕业生去向分布统计、各专业薪资对比、就业地域分布分析等。以“毕业去向”模块为例,系统可自动识别升学、就业、创业、待业等状态,并生成占比图表;在“薪资对比”部分,则可通过分组聚合计算平均薪资,并结合学历、专业维度进行多维交叉分析。
以下为部分关键代码实现示例:
1. 毕业去向分布统计核心代码
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg, round, when
import pandas as pd
import numpy as np
# 初始化 SparkSession
spark = SparkSession.builder.appName("GradEmploymentAnalysisSystem").master("local[*]").getOrCreate()
def analyze_graduate_destination(data_path):
# 读取就业数据(假设数据格式为 CSV)
df = spark.read.csv(data_path, header=True, inferSchema=True)
# 筛选毕业去向相关字段,排除空值
destination_df = df.select("graduate_id", "graduate_destination").filter(col("graduate_destination").isNotNull())
# 统计各去向人数及占比
destination_count = destination_df.groupBy("graduate_destination").agg(count("graduate_id").alias("count"))
total_count = destination_count.agg(sum("count").alias("total")).collect()[0]["total"]
destination_analysis = destination_count.withColumn("percentage", round((col("count") / total_count) * 100, 2))
# 按人数降序排序
result_df = destination_analysis.orderBy(col("count").desc())
# 将结果转换为 Pandas DataFrame,便于后续存储到 MySQL
result_pd = result_df.toPandas()
# 打印分析结果(实际项目中可注释,仅用于调试)
print("毕业去向分布统计结果:")
print(result_pd)
return result_pd
2. 专业薪资水平对比核心代码
该模块主要用于分析不同专业毕业生的平均薪资差异。通过加载原始就业记录,提取“专业名称”与“月薪”字段,进行分组聚合运算,最终输出各专业的薪资均值并排序。同时支持按学历(本科、硕士)进行细分比较,增强分析颗粒度。
尽管本系统作为毕业设计项目,在性能优化和扩展性方面仍有提升空间——例如面对超大规模数据时可能存在处理延迟问题——但整体已实现了数据导入、清洗、分析、存储与可视化的基本闭环。其架构设计合理,模块划分清晰,具备一定的可复用性。
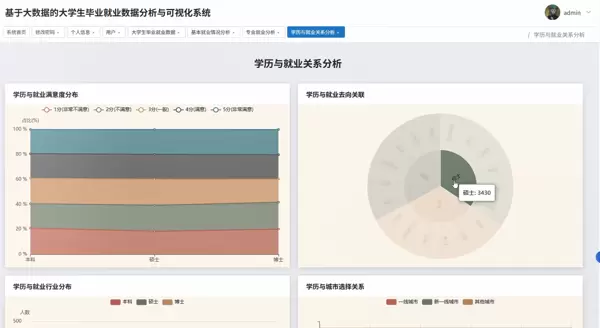
更重要的是,该项目为同专业学生提供了可参考的技术实现范例。无论是技术栈的选择(Hadoop + Spark + Python + Echarts),还是业务逻辑的设计思路,均可作为类似课题的研究起点。希望此案例能在一定程度上启发更多同学将大数据技术应用于教育、社会统计等实际领域。
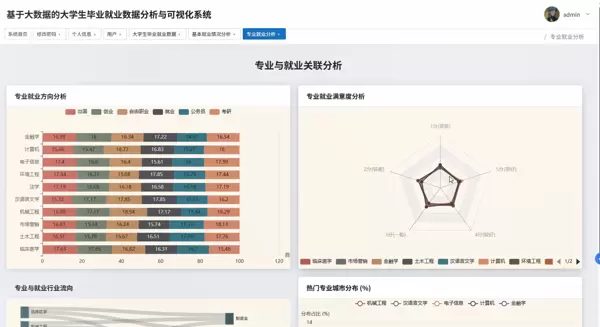
def analyze_major_salary(data_path):
# 读取就业数据
df = spark.read.csv(data_path, header=True, inferSchema=True)
# 筛选专业与期望薪资字段,并剔除空值及无效薪资(如0或负数,单位为元)
salary_df = df.select("major", "expected_salary").filter(
(col("major").isNotNull()) &
(col("expected_salary").isNotNull()) &
(col("expected_salary") > 0)
)
# 按专业分组统计平均期望薪资,保留两位小数,并统计各专业样本数量
major_salary = salary_df.groupBy("major").agg(
avg("expected_salary").alias("avg_salary"),
count("major").alias("student_count")
).withColumn("avg_salary", round(col("avg_salary"), 2))
# 过滤掉参与人数少于10的专业,以减少小样本带来的偏差
valid_major_salary = major_salary.filter(col("student_count") >= 10)
# 将结果按平均薪资从高到低排序
result_df = valid_major_salary.orderBy(col("avg_salary").desc())
# 转换为 Pandas DataFrame 便于展示和后续处理
result_pd = result_df.toPandas()
# 输出分析结果
print("专业薪资水平对比结果:")
print(result_pd)
return result_pd
def analyze_education_destination(data_path):
# 加载就业数据文件
df = spark.read.csv(data_path, header=True, inferSchema=True)
# 提取学历层次、毕业去向及毕业生ID,同时排除缺失值记录
edu_dest_df = df.select("education_level", "graduate_destination", "graduate_id").filter(
(col("education_level").isNotNull()) &
(col("graduate_destination").isNotNull())
)
# 定义学历排序规则,确保后续输出符合从低到高的教育层级顺序
education_order = ["专科", "本科", "硕士", "博士"]
# 按学历与毕业去向组合进行人数统计
edu_dest_count = edu_dest_df.groupBy("education_level", "graduate_destination").agg(
count("graduate_id").alias("count")
)
# 计算每个学历层次的毕业生总数
edu_total = edu_dest_count.groupBy("education_level").agg(
sum("count").alias("edu_total")
)
# 关联总人数信息,计算各去向在对应学历中的占比
edu_dest_analysis = edu_dest_count.join(edu_total, on="education_level", how="inner")
edu_dest_analysis = edu_dest_analysis.withColumn(
"percentage", round((col("count") / col("edu_total")) * 100, 2)
)
# 先按学历升序排列,再按人数降序排列,保证结构清晰
result_df = edu_dest_analysis.orderBy(col("education_level").asc(), col("count").desc())
# 转换为 Pandas DataFrame 以便进一步使用
result_pd = result_df.toPandas()
# 应用自定义分类顺序对学历字段进行排序设置
result_pd["education_level"] = pd.Categorical(
result_pd["education_level"],
categories=education_order,
ordered=True
)
result_pd = result_pd.sort_values("education_level")
print("学历与就业去向关联分析结果:")
print(result_pd)
return result_pd
【Hadoop+Spark+Python毕设】基于大数据的大学生毕业就业数据分析与可视化系统——结语

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




