经管之家App
让优质教育人人可得
立即打开


从零开始构建高性能传感器数据流水线,释放Python科学计算核心的真正速度
”
为了学习NumPy,我一直在运行一系列制作迷你项目的项目。我已经建立了一个个人习惯和天气分析项目。但我还没真正有机会体验NumPy的全部实力和能力。我想尝试理解为什么 NumPy 在数据分析中如此有用。为了结束这个系列,我将实时展示这一切。
我会用一个虚构的客户或公司来让事情变得互动。在这个案例中,我们的客户将是EnviroTech Dynamics,一家全球工业传感器网络运营商。
目前,EnviroTech依赖过时的基于循环的Python脚本每天处理超过100万个传感器读数。这一过程极其缓慢,延误了关键的维护决策,影响了运营效率。他们需要一个现代化、高性能的解决方案。
我被委托制作一个基于NumPy的概念验证,以演示如何加速他们的数据流水。
为了验证这一概念,我将使用一个大型模拟数据集,该数据集使用NumPy的随机模块生成,包含以下关键数组的条目:
核心目标是为EnviroTech的数据挑战提供四个清晰、矢量化的解决方案,展示速度与性能。所以我会展示这些:
首先,我们需要一个庞大的数据集来让速度差异显而易见。我会用我们之前计划的100万个温度读数。
import numpy as np
# Set the size of our data
NUM_READINGS = 1_000_000
# Generate the Temperature array (1 million random floating-point numbers)
# We use a seed so the results are the same every time you run the code
np.random.seed(42)
mean_temp = 45.0
std_dev_temp = 12.0
temperature_data = np.random.normal(loc=mean_temp, scale=std_dev_temp, size=NUM_READINGS)
print(f”Data array size: {temperature_data.size} elements”)
print(f”First 5 temperatures: {temperature_data[:5]}”)
输出:
Data array size: 1000000 elements
First 5 temperatures: [50.96056984 43.34082839 52.77226246 63.27635828 42.1901595 ]
现在我们有了记录。让我们来看看NumPy的效果。
假设我们想用标准的 Python 循环计算这些元素的平均值,流程大致如下。
# Function using a standard Python loop
def calculate_mean_loop(data):
total = 0
count = 0
for value in data:
total += value
count += 1
return total / count
# Let’s run it once to make sure it works
loop_mean = calculate_mean_loop(temperature_data)
print(f”Mean (Loop method): {loop_mean:.4f}”)
这种方法没有问题。但速度相当慢,因为计算机必须逐个处理每个数字,不断在Python解释器和CPU之间切换。
为了真正展示速度,我会用命令。这会让代码运行数百次,以提供可靠的平均执行时间。%timeit
# Time the standard Python loop (will be slow)
print(“ — — Timing the Python Loop — -”)
%timeit -n 10 -r 5 calculate_mean_loop(temperature_data)
输出
--- Timing the Python Loop ---
244 ms ± 51.5 ms per loop (mean ± std. dev. of 5 runs, 10 loops each)
使用这个,我基本上是在循环中运行代码10次(以获得稳定的平均值),使用该过程会重复5次(以获得更稳定的稳定性)。 -n 10 -r 5
现在,让我们把它和NumPy矢量化做个对比。而矢量化,意味着整个作(这里指平均值)会一次性对整个数组进行,后台使用高度优化的C代码。
以下是使用 NumPy 计算平均值的方法
# Using the built-in NumPy mean function
def calculate_mean_numpy(data):
return np.mean(data)
# Let’s run it once to make sure it works
numpy_mean = calculate_mean_numpy(temperature_data)
print(f”Mean (NumPy method): {numpy_mean:.4f}”)
输出:
Mean (NumPy method): 44.9808
现在我们来计时。
# Time the NumPy vectorized function (will be fast)
print(“ — — Timing the NumPy Vectorization — -”)
%timeit -n 10 -r 5 calculate_mean_numpy(temperature_data)
输出:
--- Timing the NumPy Vectorization ---
1.49 ms ± 114 μs per loop (mean ± std. dev. of 5 runs, 10 loops each)
这可是巨大的区别。几乎不存在。这就是矢量化的力量。
让我们向客户展示这个速度差异:
“我们比较了两种对一百万个温度读数进行相同计算的方法——传统的Python对应循环和NumPy矢量化作。
差异非常显著:纯Python循环每次运行约需244毫秒,而NumPy版本完成相同任务仅需1.49毫秒。
这大约是速度提升了160×。”
NumPy 的另一个酷炫功能是能够进行基础到高级统计——这样你就能很好地了解数据集中的情况。它提供以下作:
我们已经成功生成了模拟温度数据。压力也一样。计算压力是展示NumPy快速处理多个大阵组能力的绝佳方式。
对我们的客户来说,这也让我有机会展示他们工业系统的健康检查。
此外,温度和气压通常相关。突然的压力下降可能导致温度飙升,反之亦然。计算两者的基线可以让我们判断它们是一起漂移还是独立漂移
# Generate the Pressure array (Uniform distribution between 100.0 and 500.0)
np.random.seed(43) # Use a different seed for a new dataset
pressure_data = np.random.uniform(low=100.0, high=500.0, size=1_000_000)
print(“Data arrays ready.”)
输出:
Data arrays ready.
好了,我们开始计算。
print(“\n — — Temperature Statistics — -”)
# 1. Mean and Median
temp_mean = np.mean(temperature_data)
temp_median = np.median(temperature_data)
# 2. Standard Deviation
temp_std = np.std(temperature_data)
# 3. Percentiles (Defining the 90% Normal Range)
temp_p5 = np.percentile(temperature_data, 5) # 5th percentile
temp_p95 = np.percentile(temperature_data, 95) # 95th percentile
# Formating our results
print(f”Mean (Average): {temp_mean:.2f}°C”)
print(f”Median (Middle): {temp_median:.2f}°C”)
print(f”Std. Deviation (Spread): {temp_std:.2f}°C”)
print(f”90% Normal Range: {temp_p5:.2f}°C to {temp_p95:.2f}°C”)
以下是输出:
--- Temperature Statistics ---
Mean (Average): 44.98°C
Median (Middle): 44.99°C
Std. Deviation (Spread): 12.00°C
90% Normal Range: 25.24°C to 64.71°C
所以,为了解释你现在看到的情况
平均值(平均值):44.98°C,基本上给出了一个大多数读数预期落在的中心点。这很酷,因为我们不必扫描整个大型数据集。有了这个数字,我对我们通常的温度读数有了相当清晰的了解。
如果你注意到,中位数(中位数)44.99°C与平均值非常一致。这告诉我们,没有极端的异常值让平均值过高或过低。
标准差12°C意味着温度与平均值有很大差异。基本上,有些日子比其他日子更热或更凉爽。较低的数值(比如3°C或4°C)会显示更稳定,但12°C则表示变化很大的模式。
对于百分位来说,基本上意味着大多数日子都在25°C到65°C之间徘徊。 如果我要把这个说法给客户,我可以这样说:
“系统(或环境)平均保持约45°C的温度,这是典型运行或环境条件的可靠基线。偏差12°C表示温度水平在平均值附近显著波动。
简单来说,读数并不稳定。最后,90%的读数介于25°C至65°C之间。 这为你提供了“正常”的真实形象,帮助你定义警报或维护的可接受阈值。为了提升性能或可靠性,我们可以识别高波动的原因(例如外部热源、通风模式、系统负载)。”
我们也计算压力。
print(“\n — — Pressure Statistics — -”)
# Calculate all 5 measures for Pressure
pressure_stats = {
“Mean”: np.mean(pressure_data),
“Median”: np.median(pressure_data),
“Std. Dev”: np.std(pressure_data),
“5th %tile”: np.percentile(pressure_data, 5),
“95th %tile”: np.percentile(pressure_data, 95),
}
for label, value in pressure_stats.items():
print(f”{label:<12}: {value:.2f} kPa”)
为了改进代码库,我把所有计算都存储在一个叫做压力统计的字典里,然后简单地循环键值对。
以下是输出:
--- Pressure Statistics ---
Mean : 300.09 kPa
Median : 300.04 kPa
Std. Dev : 115.47 kPa
5th %tile : 120.11 kPa
95th %tile : 480.09 kPa
如果我把这个给客户看。大概是这样的:
“我们的压力读数平均约为300千帕,中位数——即中间值——几乎相同。这说明压力分布总体相当平衡。不过,标准差大约是115千帕,这意味着读数之间存在很大差异。换句话说,有些读数远高于或低于典型的300 kPa水平。 从百分位数来看,我们90%的读数都在120到480 kPa之间。这个范围很宽,表明压力状况并不稳定——在运行过程中可能在低压和高压之间波动。因此,虽然平均值看起来还不错,但变异性可能表明系统表现不一致或环境因素影响了系统。”
我最喜欢NumPy的一个功能是能够快速识别并过滤数据集中的异常。为了证明这一点,我们的虚构客户EnviroTech Dynamics为我们提供了另一个有用的数组,里面包含系统状态码。这告诉我们机器是如何持续运行的。它只是一个代码范围(0–3)。
它们每天接收数百万次读数,我们的任务是找到每台既处于临界状态又危险过热的机器。 手动作,甚至用环路作,都会花费很长时间。这时布尔索引(掩蔽)就派上用场了。它让我们能够在毫秒级内直接对数组应用逻辑条件,无需循环,从而过滤大量数据集。
之前,我们生成了温度和压力数据。我们对状态代码也做同样的处理。
# Reusing 'temperature_data' from earlier
import numpy as np
np.random.seed(42) # For reproducibility
status_codes = np.random.choice(
a=[0, 1, 2, 3],
size=len(temperature_data),
p=[0.85, 0.10, 0.03, 0.02] # 0=Normal, 1=Warning, 2=Critical, 3=Offline
)
# Let’s preview our data
print(status_codes[:5])
输出:
[0 2 0 0 0]
现在每个温度读数都有匹配的状态码。这使我们能够准确定位哪些传感器报告问题及其严重程度。
接下来,我们需要某种阈值或异常标准。在大多数情况下,平均值+3×标准差以上的值都被视为严重异常值,这种读数你不希望系统中出现。计算
temp_mean = np.mean(temperature_data)
temp_std = np.std(temperature_data)
SEVERITY_THRESHOLD = temp_mean + (3 * temp_std)
print(f”Severe Outlier Threshold: {SEVERITY_THRESHOLD:.2f}°C”)
输出:
Severe Outlier Threshold: 80.99°C
接下来,我们将创建两个滤波器(掩码)来隔离符合条件的数据。一个用于系统状态为“临界”(代码2)的读数,另一个用于温度超过阈值的读数。
# Mask 1 — Readings where system status = Critical (code 2)
critical_status_mask = (status_codes == 2)
# Mask 2 — Readings where temperature exceeds threshold
high_temp_outlier_mask = (temperature_data > SEVERITY_THRESHOLD)
print(f”Critical status readings: {critical_status_mask.sum()}”)
print(f”High-temp outliers: {high_temp_outlier_mask.sum()}”)
幕后情况如下。NumPy 创建两个数组,分别填充 True 或 False。每一个真理都标记了一个满足该条件的解读。真表示为1,假表示为0。快速加总后,可以统计匹配的数量。
以下是输出:
Critical status readings: 30178
High-temp outliers: 1333
在打印最终结果之前,先把这两个异常结合起来。我们希望读数既关键又过于高温。NumPy 允许我们利用逻辑算符在多种条件下进行过滤。在这种情况下,我们将使用表示为 AND 函数的函数&.
# Combine both conditions with a logical AND
critical_anomaly_mask = critical_status_mask & high_temp_outlier_mask
# Extract actual temperatures of those anomalies
extracted_anomalies = temperature_data[critical_anomaly_mask]
anomaly_count = critical_anomaly_mask.sum()
print(“\n — — Final Results — -”)
print(f”Total Critical Anomalies: {anomaly_count}”)
print(f”Sample Temperatures: {extracted_anomalies[:5]}”)
输出:
--- Final Results ---
Total Critical Anomalies: 34
Sample Temperatures: [81.9465697 81.11047892 82.23841531 86.65859372 81.146086 ]
我们把这个给客户介绍
“在分析了一百万次温度读数后,我们的系统检测到了34个关键异常——这些读数既被机器标记为'临界状态',又超过了高温阈值。
前几个读数介于81°C到86°C之间,远高于我们正常的45°C作范围。 这表明少数传感器报告了危险的峰值,可能表明过热或传感器故障。 换句话说,虽然我们99.99%的数据看起来都很稳定,但这34点正是我们应该重点维护或进一步调查的重点。”
我们用 matplotlib 快速想象一下
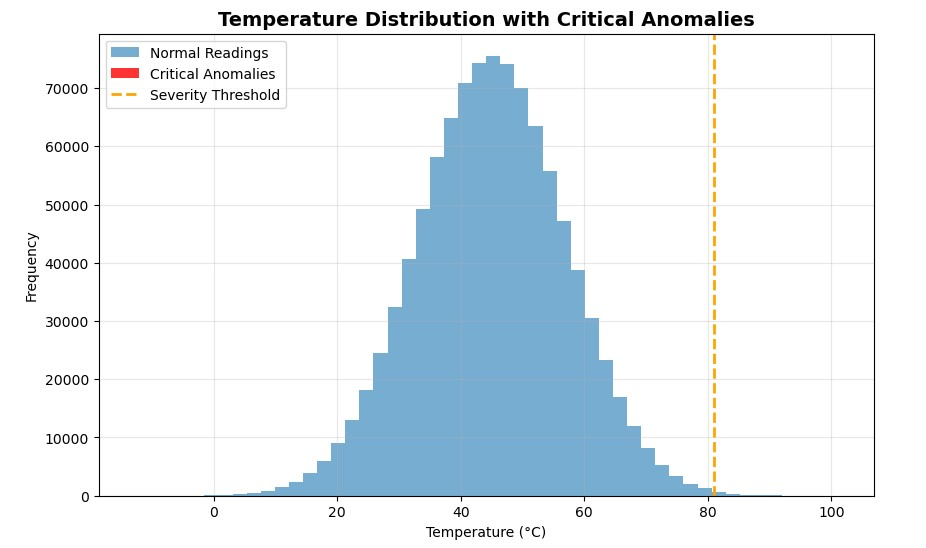
当我第一次绘制结果时,我本以为会看到一簇红色条,显示我的关键异常。但没有。
起初我以为有什么不对劲,但随后我明白了。在一百万次读数中,只有34次为危急。这就是布尔掩蔽的美妙之处:它能检测到你眼睛无法察觉的东西。即使异常隐藏在数百万正常值中,NumPy 也能在毫秒级内标记它们。
最后,NumPy 允许你去除不一致和不合理的数据。你可能听说过数据分析中的数据清理概念。在 Python 中,NumPy 和 Pandas 常用于简化这一作。
为证明这一点,我们的条目中含有值为3(错误/缺失)的条目。如果我们在整体分析中使用这些错误的温度读数,它们会偏离我们的结果。解决方案是用一个统计学上合理的估计值替换错误读数。status_codes
第一步是确定我们应该用什么值来替换错误数据。中位数总是个好选择,因为与均值不同,中位数不受极端值的影响。
# TASK: Identify the mask for ‘Valid’ data (where status_codes is NOT 3 — Faulty/Missing).
valid_data_mask = (status_codes != 3)
# TASK: Calculate the median temperature ONLY for the Valid data points. This is our imputation value.
valid_median_temp = np.median(temperature_data[valid_data_mask])
print(f”Median of all valid readings: {valid_median_temp:.2f}°C”)
输出:
Median of all valid readings: 44.99°C
现在,我们将使用强函数进行条件替换。这是该函数的典型结构。np.where()
np.where(Condition, Value_if_True, Value_if_False)
就我们而言:
# TASK: Implement the conditional replacement using np.where().
cleaned_temperature_data = np.where(
status_codes == 3, # CONDITION: Is the reading faulty?
valid_median_temp, # VALUE_IF_TRUE: Replace with the calculated median.
temperature_data # VALUE_IF_FALSE: Keep the original temperature value.
)
# TASK: Print the total number of replaced values.
imputed_count = (status_codes == 3).sum()
print(f”Total Faulty readings imputed: {imputed_count}”)
输出:
Total Faulty readings imputed: 20102
我没想到缺失值会这么多。这可能在某种程度上影响了我们上面的阅读。幸好我们几秒钟内就换了新。
现在,让我们通过检查原始数据和清理数据的中位数来验证修复方法
# TASK: Print the change in the overall mean or median to show the impact of the cleaning.
print(f”\nOriginal Median: {np.median(temperature_data):.2f}°C”)
print(f”Cleaned Median: {np.median(cleaned_temperature_data):.2f}°C”)
输出:
Original Median: 44.99°C
Cleaned Median: 44.99°C
在这种情况下,即使清理了超过2万条错误记录,中位温度仍稳定在44.99°C,表明数据集在统计上是健全且平衡的。
让我们向客户介绍一下:
“在一百万个温度读数中,有20,102个被标记为故障(状态代码=3)。我们没有删除这些有缺陷的记录,而是用中位温度值(≈ 45°C)来替代——这是一种标准的数据清理方法,既保持数据集的一致性又不扭曲趋势。 有趣的是,清洁前后中位温度保持不变(44.99°C)。这是一个好迹象:这意味着错误的读数没有扭曲数据集,替换也没有改变整体数据分布。”
好了!我们启动该项目,旨在解决EnviroTech Dynamics面临的关键问题:对更快、无循环的数据分析需求。NumPy 数组和矢量化的强大功能使我们能够修复问题,并为他们的分析流程做好未来保障。
NumPy ndarray 是整个 Python 数据科学生态系统的静默引擎。每个主要库,如Pandas、scikit-learn、TensorFlow和PyTorch,都以NumPy数组为核心,实现快速数值计算。
掌握NumPy后,你已经建立了强大的分析基础。对我来说,下一步是从单一数组转向使用Pandas库的结构化分析,它将NumPy数组组织成表格(Datafr ames),方便标记和操作。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




