基于大数据技术的仓库管理系统的设计与实现
第一章 引言
在现代供应链体系中,仓库作为物资存储与流转的关键节点,其管理效率直接关系到企业的运营成本和市场响应能力。传统的仓库管理模式主要依赖人工记录和经验判断,普遍存在库存周转率低、供需匹配不精准、仓储空间利用率不高以及设备维护不及时等问题,难以满足大规模、精细化物资管理的需求。
随着物联网与大数据技术的不断进步,仓储环节积累了大量多维度数据,包括库存状态、出入库明细、物流轨迹以及设备运行参数等,为实现智能化管理提供了坚实的数据基础。在此背景下,融合大数据技术的智能仓库管理系统应运而生。
该系统通过整合各类仓储数据源,利用大数据分析与挖掘手段,实现库存优化、需求预测、资源调度等核心功能,打破信息孤岛,提升决策科学性与运营效率。本文聚焦于系统的整体设计与实际实现过程,致力于构建一个符合现代仓储发展需求的智能化平台,推动管理模式从“经验驱动”向“数据驱动”转变,助力供应链的数字化升级。
第二章 系统分析
系统分析是确保开发方向与实际业务需求相匹配的基础工作,涵盖功能需求与非功能需求两个层面,并结合可行性进行综合评估。
在功能需求方面,系统需覆盖完整的仓储管理流程:数据采集模块应支持对库存、出入库操作、设备运行状态及物流信息等多源数据的实时获取;数据预处理模块负责完成清洗、去重和格式标准化,保障后续分析的数据质量;核心分析模块需具备库存健康度评估、需求趋势预测、库位优化建议及设备故障预警等功能;数据可视化模块则用于直观展示分析结果,支持自定义报表生成与导出功能。
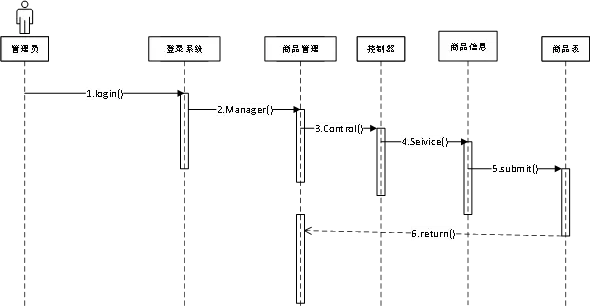
非功能需求方面,系统需具备高效的数据处理能力,以应对海量仓储数据的快速计算与响应;数据存储机制必须安全可靠,防止敏感商业信息泄露;用户界面设计应简洁明了,降低操作人员的学习门槛;同时系统需具备良好的可扩展性,能够灵活适配不同规模仓库的个性化管理需求。
从可行性角度看,技术上已有Hadoop、Spark等成熟的大数据框架和IoT数据采集方案作为支撑;经济上,虽然存在一定的开发投入,但通过优化库存结构、减少损耗、提高空间使用率等方式可显著降低长期运营成本,投资回报明显;操作层面,系统流程紧密贴合仓储日常作业逻辑,无需专业技术人员即可顺利使用,具备广泛的推广价值。
第三章 系统设计
系统设计遵循“数据驱动、架构稳定、操作高效”的原则,采用分层式技术架构与模块化功能划分,确保系统的可维护性与可扩展性。
整体架构划分为四层:数据采集层负责对接IoT传感器、ERP系统、物流平台等多种数据来源,支持结构化与非结构化数据的统一接入;数据存储层采用分布式存储方案,保障海量仓储数据的安全保存与高速检索;数据分析层为核心处理单元,依托大数据算法与预测模型,执行库存优化、需求预测等深度运算;应用层通过Web端界面呈现分析成果与操作入口,便于管理人员进行交互式操作。
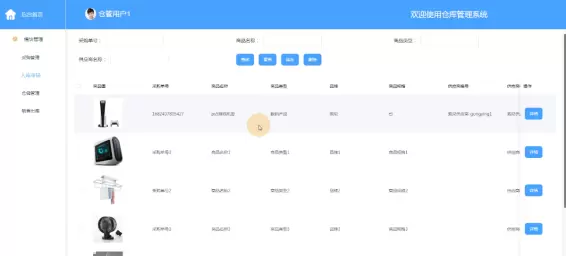
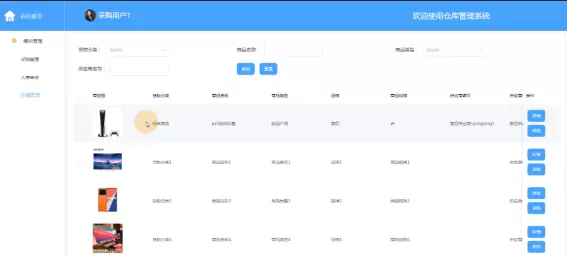
功能模块主要包括四大组成部分:数据采集与预处理模块,确保原始数据的完整性与准确性;智能分析模块,覆盖库存管理、需求预测、设备监控与空间优化等关键场景;数据可视化模块,将复杂分析结果以图表形式清晰展现,并支持报表导出;系统管理模块则承担用户权限配置、系统参数设置、数据备份等运维职责。
在数据安全方面,系统采用加密传输与存储机制保护敏感信息,实施分级权限控制策略,防范未授权访问;同时建立定期备份与灾难恢复机制,保障数据的持久性与可用性,避免因意外导致的数据丢失风险。
第四章 系统实现与展望
系统实现依托成熟的大数据技术生态完成部署:数据采集环节采用IoT传感器结合Flume工具,实现多源数据的实时汇聚,并通过Python脚本进行数据清洗与格式转换;数据存储选用HBase分布式数据库,支持高并发写入与快速查询,保障海量数据的稳定存储;数据分析层基于Spark框架进行分布式计算,集成机器学习模型实现需求预测与库存优化;前端展示部分采用HTML5与ECharts技术构建动态可视化界面,提供直观的数据呈现与交互体验。
经过测试验证,系统在数据处理速度、分析精度与响应性能方面表现良好,能够有效支撑仓库日常运营决策,提升管理自动化水平。
未来,系统仍有进一步优化的空间。在功能深化方面,可引入AI深度学习模型,进一步提升预测准确率与异常识别能力;增加实时监控模块,实现对仓储作业全过程的动态追踪与即时告警。在生态融合方面,可推进与供应链上下游系统的数据互通,打通采购、仓储、配送等环节,实现全链路协同管理;同时开发移动端适配版本,方便管理人员远程查看数据与处理任务。
后续将持续收集用户反馈,持续优化算法模型与交互设计,使系统更贴合行业发展趋势,为仓储管理的智能化演进和供应链整体数字化转型提供强有力的技术支持。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





