经管之家App
让优质教育人人可得
立即打开


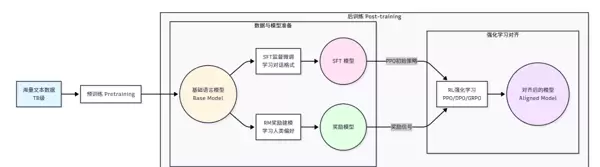
强化学习(Reinforcement Learning,RL)是一种专注于解决序贯决策问题的学习范式。它通过智能体与环境之间的持续交互,在不断“试错”的过程中学习如何最大化长期收益。相较于传统方法,这种机制赋予模型更强的自主性与适应能力。
传统的监督学习面临三大主要局限:首先,训练质量高度依赖数据质量,模型只能模仿已有标注样本,难以突破人类提供的知识边界;其次,缺乏主动探索的能力,无法发现新的解决方案路径;最后,难以有效优化涉及多步推理的长期目标,对中间过程的控制力较弱。
而强化学习则为这些问题提供了新的解决思路。通过让智能体自行生成多个候选答案,并依据其正确性获得奖励信号,系统可以学习到哪些推理路径更为高效、哪些步骤是关键所在,甚至可能发掘出优于人工标注的解题策略[8]。这正是 Agentic RL 的核心理念——将大语言模型(LLM)作为可学习的策略函数,嵌入到智能体的感知-决策-执行闭环中,利用强化学习来提升其在复杂任务中的多步表现能力。
PBRFT 思维聚焦于“如何让模型输出更优质的单一回答”,强调语言表达的流畅性和单步响应的质量;而 Agentic RL 则转向“如何使智能体成功完成端到端的复杂任务”,关注整体任务完成度与行动策略的合理性,支持多步规划与动态调整。这一转变推动了 LLM 从被动的“对话助手”向主动的“自主智能体”演进——它能够主动检索信息、判断何时调用外部工具、为了最终目标执行看似迂回的中间操作,并从失败经验中自我修正。
预训练阶段最常见的任务形式是因果语言建模(Causal Language Modeling),也被称为下一个词预测(Next Token Prediction)。
该任务的目标是:给定一个输入序列 $x_1, x_2, ..., x_t$,模型需预测下一个词 $x_{t+1}$。其损失函数定义为负对数似然:
$\mathcal{L}_{\text{pretrain}} = -\sum_{t=1}^{T} \log P(x_t | x_1, x_2, ..., x_{t-1}; \theta)$
其中:
训练目标是最小化该损失函数,即最大化正确词汇被预测出来的概率。例如,当输入为“The cat sat on the”时,模型应倾向于预测“mat”作为后续词汇。
通过在大规模文本语料上的训练,模型逐步掌握以下能力:
目标:使模型能够准确理解和遵循指令,适配特定对话或任务格式。
训练数据:由(prompt, completion)组成的成对样本。
训练目标:与预训练类似,旨在最大化期望输出的条件概率。
损失函数:
$\mathcal{L}_{\text{SFT}} = -\sum_{i=1}^{N} \log P(y_i | x_i; \theta)$
参数说明:
特点:
目标:构建一个能够评估回答质量的模型,从而反映人类偏好。
训练数据:采用偏好对比数据集,每个样本包含同一问题下的两个不同回答,分别标记为更优(chosen)和较差(rejected)。
损失函数:
$\mathcal{L}_{\text{RM}} = -\mathbb{E}_{(x, y_w, y_l)}[\log \sigma(r_\phi(x, y_w) - r_\phi(x, y_l))]$
参数说明:
在完成预训练、监督微调和奖励建模之后,进入强化学习阶段。此阶段使用如 PPO 等算法,以奖励模型输出的评分为反馈信号,进一步优化语言模型的生成策略。
智能体(即 LLM)根据当前状态生成动作(文本),环境返回奖励,模型据此更新策略参数,目标是最大化累积奖励。整个过程不再依赖固定标签,而是通过试错探索最优行为路径。
PBRFT(Prompt-Based Response Fine-Tuning)注重单轮响应质量的优化,强调语言自然度与准确性,适用于问答、摘要等一次性输出任务。而 Agentic RL 更关注跨步骤的任务执行效率与整体成功率,强调策略选择、工具调用与错误恢复能力,适用于需要多跳推理或外部交互的复杂场景。
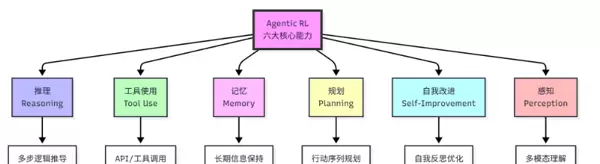
一个完整的 Agentic RL 架构要求 LLM 智能体具备以下六项关键能力:
设计有效的奖励函数是 Agentic RL 成败的关键。理想奖励应同时涵盖:
实践中常采用稀疏奖励结合稠密奖励 shaping 技术,帮助智能体更快收敛。
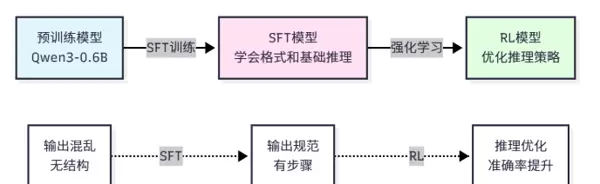
直接进行强化学习容易因初始策略过差导致训练不稳定。因此,在正式进入 RL 阶段前,通常会进行一轮专门的冷启动 SFT,使用高质量的轨迹数据(包括成功任务路径、工具使用记录等)对模型进行初步引导,使其具备基本的任务执行能力,为后续策略优化奠定基础。
GRPO(Group Relative Policy Optimization)是一种适用于 Agentic RL 的新型训练方法。它不依赖显式的奖励模型,而是通过比较同一问题下多个生成路径的相对优劣,计算组内排序差异作为优化信号。这种方法降低了对精确打分的需求,增强了训练稳定性,尤其适合缺乏绝对标准答案但存在明显优劣对比的复杂任务场景。
[8] 相关研究指出,强化学习可用于发现超越人类标注的解题路径。
sigmoid函数
目标:通过强化学习对语言模型进行优化,以生成更高质量的回复。
算法:采用PPO(Proximal Policy Optimization,近端策略优化)算法。
目标函数:
\[ J_{\text{PPO}} = \mathbb{E}_{x, y \sim \pi_{\theta}}\left[r_{\phi}(x, y)\right] - \beta \cdot D_{KL}\left(\pi_{\theta} \| \pi_{\text{ref}}\right) \]
参数说明:
目标含义:在最大化奖励的同时,避免策略过度偏离原始模型,确保输出的稳定性与可控性。
传统的后训练方法(称为PBRFT:基于偏好的强化微调)主要聚焦于单轮对话质量的提升。其流程是:给定用户问题,模型生成一个回答,并根据该回答获得一次性奖励。这种方法适用于优化通用对话助手,但在面对需要多步推理、工具调用和长期规划的复杂任务时存在明显局限。
相比之下,Agentic RL 强调智能体在动态环境中的持续交互能力,具备以下关键特征:
强化学习通常基于马尔可夫决策过程(Markov Decision Process, MDP)进行建模。MDP由五元组 (S, A, P, R, γ) 构成,包括:
从MDP框架出发,我们可以对PBRFT与Agentic RL进行系统性比较:
状态(State)方面:
PBRFT的状态 s0 仅由初始用户提示构成,整个过程为单步(T=1),状态不发生变化,表示为 s = prompt。
而Agentic RL的状态 st 包含完整的交互历史和上下文信息,具有较长的时间跨度(T 1),并随每一步行动不断演化,形式为:
st = (prompt, o1, o2, ..., ot),其中 ot 表示第 t 步的观察结果(如工具返回内容或环境反馈)。
行动(Action)方面:
PBRFT的行动空间仅限于文本生成,属于单一类型的动作,表示为 a = y πθ(y | s0)。
Agentic RL则拥有更丰富的行动空间,涵盖文本生成、工具调用、环境操作等多种行为类型,表示为:
at ∈ {attext, attool},例如:
- attext:输出思考过程或最终回答
- attool:调用计算器、搜索引擎等外部工具
状态转移函数(Transition Function)方面:
PBRFT不存在真正的状态转移,执行完生成动作后直接进入终止状态,表示为:
P(s′|s,a) = δ(s′ sterminal)。
而在Agentic RL中,状态会根据智能体的行动和环境响应动态更新,即:
st+1 P(st+1 | st, at),例如:执行一次搜索操作后,新状态将包含返回的搜索结果。
奖励机制(Reward)方面:
PBRFT仅在任务结束时提供一次性的单步奖励,形式为 r(s0, a),整体奖励记作 RPBRFT = r(s, y)。
Agentic RL则支持多步奖励,每一步都可能获得反馈信号,总奖励为各步奖励的折现累加,更有利于长期目标的学习。

在强化学习与大语言模型(LLM)的结合中,PBRFT 与 Agentic RL 在奖励机制和训练目标上存在本质差异。PBRFT 的单步奖励定义为:
\[ R_{\text{PBRFT}} = r(s_0, y) \]
该奖励通常由奖励模型提供,形式为:
\[ r(s_0, y) = r_\phi(s_0, y) \]
相比之下,Agentic RL 引入了多步奖励机制,能够在执行过程中的各个阶段给予反馈,即 \( r(s_t, a_t) \),从而支持更复杂的任务决策。其总奖励表示为累积折扣奖励:
\[ R_{\text{Agentic}} = \sum_{t=0}^T \gamma^t r(s_t, a_t) \]
其中,\( \gamma \in [0,1] \) 为折扣因子,用于平衡当前与未来奖励的重要性。奖励函数 \( r(s_t, a_t) \) 可以设计为稀疏奖励(仅在任务完成时触发,例如答案正确+1)、密集奖励(每一步均有反馈,如工具调用成功+0.1),或两者的混合形式。
从训练目标来看,PBRFT 的优化目标是最大化单步期望奖励:
\[ J_{\text{PBRFT}}(\theta) = \mathbb{E}_{s_0, y \sim \pi_0}[r(s_0, y)] \]
而 Agentic RL 则致力于最大化整个轨迹上的累积折扣奖励:
\[ J_{\text{Agentic}}(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}\left[\sum_{t=0}^T \gamma^t r(s_t, a_t)\right] \]
其中,轨迹 \( \tau = (s_0, a_0, s_1, a_1, \ldots, s_T) \) 表示智能体在整个任务过程中经历的状态与动作序列。
这种目标函数的转变反映了思维范式的演进:PBRFT 关注“如何让模型生成更优的单一回答”,强调语言表达质量与单步决策能力;而 Agentic RL 聚焦于“如何使智能体完成复杂任务”,注重行动策略与多步规划能力。这一转变推动 LLM 从传统的“对话助手”角色进化为具备自主性的“智能体”,能够主动获取信息、判断何时调用外部工具、接受中间过程的迂回路径,并从失败经验中持续学习。
奖励函数的设计对训练效果具有决定性影响。一个高质量的奖励函数应满足以下条件:明确界定成功的标准、提供有效的梯度信号、保持较低的方差、易于调整与组合。反之,设计不当的奖励可能导致多种问题:仅在任务终点给予反馈,导致中间步骤缺乏指导;出现奖励欺骗现象,使得智能体通过非预期方式获取高分;多个目标之间相互冲突;或因方差过大而导致训练难以收敛。
在进行强化学习之前,通常需先通过监督微调(SFT)进行冷启动。SFT 阶段可采用 LoRA 等参数高效微调方法。关键训练参数包括:
LoRA 相关配置建议如下:
在训练过程中,需重点关注以下指标以确保训练稳定有效:
在训练过程中,若发现损失不下降,可尝试增大学习率、检查数据格式是否正确,或适当增加训练轮数以提升模型收敛效果。当出现过拟合现象时,建议增大 weight_decay 参数以增强正则化,减少训练轮次,或引入更多训练数据来提升泛化能力。
GRPO(Group Relative Policy Optimization)是一种策略优化方法,其目标函数定义如下:
JGRPO(θ) = s,a πθ[ (πθ(a|s) / πref(a|s)) · (r(s,a) - rgroup) ] - β · DKL(πθ ∥ πref)
其中,rgroup 表示组内平均奖励,用于计算相对奖励信号;β 为 KL 散度惩罚系数,用以约束当前策略 πθ 相对于参考策略 πref 的偏离程度。与 PPO 不同,GRPO 不依赖优势函数 A(s,a),而是直接使用奖励与组内均值的差值作为优化信号,从而避免了对 Value Model 的依赖。
PPO 的目标函数形式为:
JPPO(θ) = s,a πθ[ min( (πθ(a|s)/πold(a|s)) A(s,a), clip(πθ(a|s)/πold(a|s), 1ε, 1+ε) A(s,a) ) ]
其中优势函数 A(s,a) = Q(s,a) - V(s) = r(s,a) + γV(s') - V(s),需要借助额外的价值网络进行估计。相比之下,GRPO 通过组内相对奖励机制有效降低方差,并结合 KL 惩罚项防止策略更新幅度过大,提升了训练稳定性。

在 GRPO 训练中需重点关注以下指标:
平均奖励(Average Reward):应呈现逐步上升趋势。若奖励停滞不前,可能原因包括学习率设置过小、KL 惩罚过强、或奖励函数设计不合理;若奖励先升后降,则可能存在过拟合或发生奖励崩塌现象。
KL 散度(KL Divergence):理想范围通常在 0.01 至 0.1 之间。若 KL 散度过高(>0.5),表明策略已严重偏离初始分布,建议增大 kl_coef 或调低学习率;若 KL 散度过低(<0.001),说明策略更新不足,可尝试减小 kl_coef 或提高学习率以促进探索。
准确率(Accuracy):作为反映模型性能的核心指标,应在训练过程中持续提升,体现模型推理与生成能力的增强。
生成质量(Generation Quality):需人工评估生成结果,确保输出内容格式规范、逻辑清晰、语义连贯。
常见问题及应对策略:
当训练中奖励未见增长时,可能原因是学习率偏低或 KL 惩罚过重限制了策略更新,也可能源于奖励函数设计缺陷或 SFT 模型基础质量较差。此时可尝试将学习率从 1e-5 提升至 5e-5,或将 kl_coef 从 0.1 调整为 0.05,同时检查奖励逻辑或重新训练监督微调阶段的模型。
若出现 KL 散度爆炸(超过 0.5 甚至达到 1.0),导致生成文本结构混乱、格式异常,通常由学习率过高、KL 惩罚不足或奖励函数过于激进引起。应对措施包括:将学习率从 5e-5 降至 1e-5,增大 kl_coef(如从 0.05 升至 0.1),优化奖励函数设计,或引入梯度裁剪技术以稳定训练过程。
在 GRPO 训练过程中,显存消耗通常高于 SFT,主要原因在于需要并行生成多个回答,同时保存参考模型的输出结果,这容易导致显存溢出(OOM)。为缓解这一问题,可采取多种优化策略:降低 num_generations 参数(例如从 8 调整为 4)、减小 batch_size(如由 4 改为 2)、缩短 max_new_tokens(如从 512 减至 256),或启用梯度检查点与混合精度训练技术以减少内存占用。
当模型生成质量下降时,尽管准确率可能有所提升,但常伴随格式混乱、推理逻辑不清晰等问题。这种情况可能源于奖励函数设计不合理——仅聚焦于准确率而忽视了其他关键质量维度;也可能是 KL 惩罚系数过小,导致当前策略模型过度偏离监督微调(SFT)阶段的原始分布;此外,训练轮数过多引发的过拟合同样可能导致此类现象。针对上述问题,建议采用组合式奖励函数,综合优化多项评价指标,适当增大 kl_coef 以增强输出稳定性,同时考虑减少训练迭代次数或扩充高质量训练数据来提升泛化能力。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




