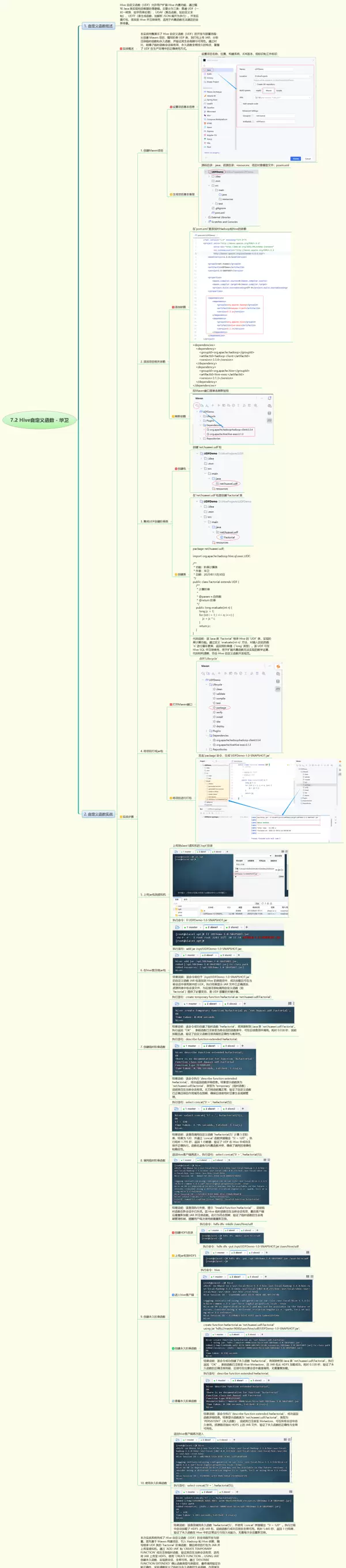
1. 实战概述
本实战全面展示了 Hive 自定义函数(UDF)从开发到部署的完整流程。涵盖 Maven 项目的创建、阶乘功能的 UDF 编写、JAR 包的生成与上传,并分别实现临时函数与永久函数的注册操作。通过实际验证两种函数在生命周期和可用范围上的差异,深入理解了临时函数仅在当前会话生效、而永久函数具备全局持久性的特点,从而掌握 UDF 在生产环境中的规范使用方法。
2. 实战步骤
3. 实战总结
本次实践系统性地完成了 Hive 自定义函数(UDF)的全流程操作。首先利用 Maven 构建项目结构,引入必要的 Hadoop 与 Hive 依赖包,编写实现了继承自 UDF 类的阶乘计算逻辑。
Factorial
随后将项目打包成 JAR 文件并上传至虚拟机环境中。
ADD JAR
CREATE TEMPORARY FUNCTION
通过上述命令成功注册了临时函数,测试表明其作用范围仅限于当前会话;为进一步实现跨会话调用,将该 JAR 文件上传至 HDFS 分布式文件系统,并使用以下命令:
CREATE FUNCTION ... USING JAR
创建永久函数,使其在整个集群范围内长期可用。最后通过元数据查询命令:
DESCRIBE FUNCTION EXTENDED
确认所注册函数的类型信息及对应的类路径,并完成最终的功能调用验证,确保逻辑正确无误。
整个实验清晰地区分了临时函数与永久函数在生命周期、作用域以及部署方式上的关键区别,切实掌握了 UDF 在大数据分析场景中的扩展应用技能,为后续开发复杂的自定义数据处理逻辑打下了坚实基础。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





