一、项目简介
本实战项目聚焦于经典的鸢尾花数据集,利用Logistic回归模型实现对三种不同品种鸢尾花的分类任务。该项目涵盖了从数据加载、探索性分析、预处理到模型训练与评估的完整机器学习流程,非常适合作为入门级实践案例。
二、数据加载与初步查看
1. 加载数据集
在任何机器学习项目中,第一步都是正确加载所需的数据集,这一步虽基础却至关重要。
2. 查看标签信息
代码中的变量代表目标变量(target variable),也被称为“标签”或“输出”,即我们希望模型预测的内容。
y
在鸢尾花数据集中,y的具体取值如下:
- 0 → 山鸢尾
- 1 → 变色鸢尾
- 2 → 维吉尼亚鸢尾
由此可见,该数据集属于典型的多分类问题。

3. 小结
上述步骤是整个鸢尾花分类项目的起点,为后续的数据处理和模型构建打下基础。掌握这一环节对于理解完整的机器学习工作流具有重要意义。
4. 完整代码展示
# 导入scikit-learn库中的datasets模块,该模块包含多个经典数据集
from sklearn import datasets
# 加载鸢尾花(Iris)数据集
# 这是一个经典的机器学习数据集,包含3种鸢尾花的测量数据
iris = datasets.load_iris()
# 获取特征数据,输入变量
# X包含4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
# 形状为(150, 4),表示150个样本,每个样本4个特征
X = iris.data
# 获取目标标签(输出变量)
# y包含每个样本对应的鸢尾花品种标签
# 0: 山鸢尾 1:变色鸢尾 2: 维吉尼亚鸢尾
y = iris.target
# 打印目标标签数组y的内容
# 这将显示一个包含150个元素的数组,元素值为0、1或2
# 用于直观了解数据分布和标签编码
print(y)
三、数据集划分
1. 引入train_test_split模块
为了科学地评估模型性能,需将数据划分为训练集和测试集。这里使用sklearn.model_selection中的train_test_split工具完成此操作。
from sklearn.model_selection import train_test_split

2. 执行数据分割
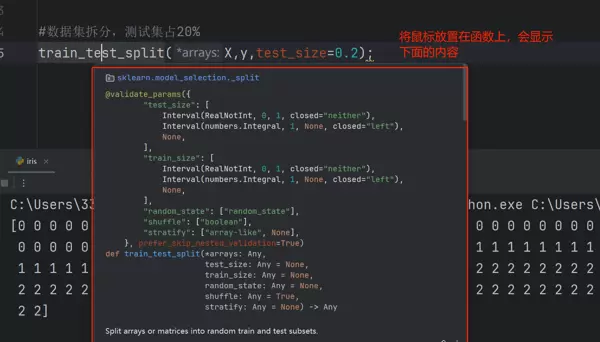
调用train_test_split()函数进行合理的数据划分,确保训练与测试样本分布合理。
将鼠标悬停在函数名上时,会显示其参数说明:
3. 实用小技巧
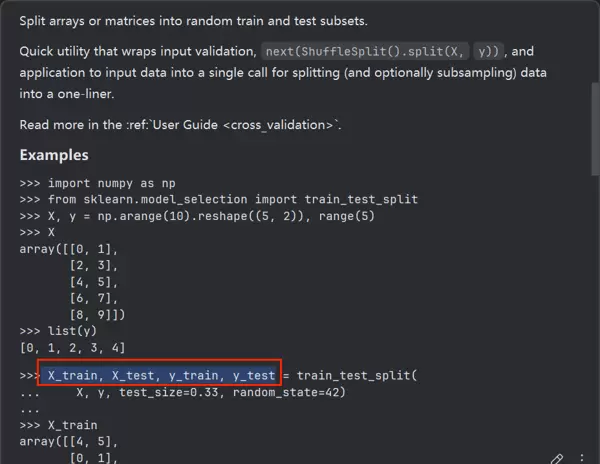
返回的四个变量通常成对出现,建议直接复制整行代码以减少手动输入错误。
train_test_split
X_train, X_test, y_train, y_test
4. 完整源码及注释
# 导入scikit-learn库中的datasets模块,该模块包含多个经典数据集
from sklearn import datasets
# 导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 加载鸢尾花(Iris)数据集
# 这是一个经典的机器学习数据集,包含3种鸢尾花的测量数据
iris = datasets.load_iris()
# 获取特征数据(输入变量)
# X包含4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
# 形状为(150, 4),表示150个样本,每个样本4个特征
X = iris.data
# 获取目标标签(输出变量)
# y包含每个样本对应的鸢尾花品种标签
# 0: setosa(山鸢尾), 1: versicolor(变色鸢尾), 2: virginica(维吉尼亚鸢尾)
# 形状为(150,),表示150个样本对应的类别
y = iris.target
# 打印目标标签数组y的内容
# 这将显示一个包含150个元素的数组,元素值为0、1或2
# 用于直观了解数据分布和标签编码
print(y)
# 将完整数据集划分为训练集和测试集
# X_train, y_train: 用于模型训练的特征和标签
# X_test, y_test: 用于模型评估的特征和标签
# test_size=0.2: 指定测试集占总数据集的20%,训练集占80%
# 随机种子未设置,每次运行划分结果可能不同
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
四、构建逻辑回归模型
1. 导入相关模块
首先需要导入LogisticRegression类,用于创建分类模型。
from sklearn.linear_model import LogisticRegression
2. 初始化模型对象
通过实例化LogisticRegression来创建一个可用于训练的模型。
lr = LogisticRegression();
3. 多分类策略参数详解
Logistic回归中有一个关键参数用于指定如何处理多分类问题,其可选值包括:
multi_class参数介绍
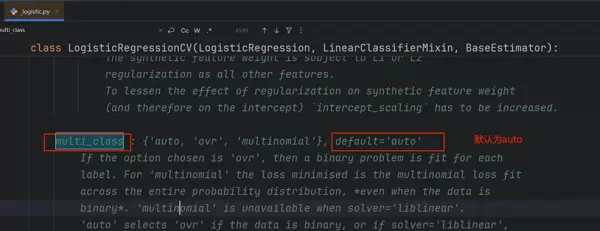
multi_class
- ovr (One-vs-Rest):为每个类别单独训练一个二分类器,将其与其他所有类别区分开。
- multinomial:直接优化多项式损失函数,适用于真正的多分类场景,即使数据为二分类也会采用此方式。
- auto:系统自动选择策略。若为二分类或满足特定条件,则选用ovr;其余情况则使用multinomial。
1)'ovr':
2)'multinomial':
solver='liblinear'
'ovr';
'multinomial';
4. 参数选择建议
- 对于二分类任务,ovr与multinomial效果相近。
1)
2)
面对多分类问题,multinomial通常能提供更精确的概率估计结果。
'multinomial'
当不确定如何选择时,保留默认设置(auto)是最稳妥的做法。
'auto'
5. 应用于当前项目
根据前文分析可知,鸢尾花数据集为多分类类型。

因此,在初始化模型时应合理设定multi_class参数。
lr = LogisticRegression(multi_class='multinomial');
6. 完整代码示例与注释
# 导入scikit-learn库中的datasets模块,该模块包含多个经典数据集
from sklearn import datasets
# 导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 导入LogisticRegression类,用于创建逻辑回归分类模型
from sklearn.linear_model import LogisticRegression
# 加载鸢尾花数据集
# 这个数据集包含3种不同品种鸢尾花的测量数据
iris = datasets.load_iris()
# 获取特征数据 - 花瓣和花萼的尺寸测量值
X = iris.data
# 获取目标标签 - 每朵花对应的品种(0=山鸢尾,1=变色鸢尾,2=维吉尼亚鸢尾)
y = iris.target
# 打印目标标签,查看数据中包含哪些品种
print(y)
# 将数据分成训练集和测试集
# 80%的数据用于训练模型,20%的数据用于测试模型效果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建一个逻辑回归分类器
# multi_class='multinomial'表示使用多分类方法处理3种花的问题
lr = LogisticRegression(multi_class='multinomial')
7. 小结
以上代码完成了AI模型训练前的所有准备工作,相当于为模型搭建好了学习框架。接下来只需将训练数据输入模型即可开始学习过程。
五、模型训练阶段
1. 引入准确率评估函数
导入accuracy_score函数,以便后续计算模型预测结果的准确率。
from sklearn.metrics import accuracy_score
2. 启动模型训练
使用训练集数据对逻辑回归模型进行训练,使其学会根据花瓣和花萼的尺寸特征判断鸢尾花的种类。
lr.fit(X_train,y_train)
3. 完整代码与详细注释
# 导入scikit-learn库中的datasets模块,该模块包含多个经典数据集
from sklearn import datasets
# 导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 导入LogisticRegression类,用于创建逻辑回归分类模型
from sklearn.linear_model import LogisticRegression
# 导入accuracy_score函数,用于计算模型预测的准确率
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
# 这个数据集包含3种不同品种鸢尾花的测量数据
iris = datasets.load_iris()
# 获取特征数据 - 花瓣和花萼的尺寸测量值
X = iris.data
# 获取目标标签 - 每朵花对应的品种(0=山鸢尾,1=变色鸢尾,2=维吉尼亚鸢尾)
y = iris.target
# 打印目标标签,查看数据中包含哪些品种
print(y)
# 将数据分成训练集和测试集
# 80%的数据用于训练模型,20%的数据用于测试模型效果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建一个逻辑回归分类器
# multi_class='multinomial'表示使用多分类方法处理3种花的问题
lr = LogisticRegression(multi_class='multinomial')
# 使用训练数据训练逻辑回归模型
# 模型会学习如何根据花的特征(花瓣、花萼尺寸)来识别花的品种
lr.fit(X_train, y_train)
4. 小结
此部分实现了AI模型的核心训练流程,使模型掌握了区分三种鸢尾花的能力。下一步将使用测试集——相当于“考试卷”——来检验模型的学习成果。
六、模型预测与性能评估
1. 对测试集进行预测
利用已训练好的模型对测试集中的样本进行类别预测,模型会依据所学规律判断每朵花的品种。
y_pred = lr.predict(X_test)
2. 输出预测准确率
准确率反映了模型正确分类的比例,是衡量分类模型性能的关键指标之一。
print("准确率:%.2f" % accuracy_score(y_test, y_pred))
3. 完整代码与注释说明
# 导入scikit-learn库中的datasets模块,该模块包含多个经典数据集
from sklearn import datasets
# 导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 导入LogisticRegression类,用于创建逻辑回归分类模型
from sklearn.linear_model import LogisticRegression
# 导入accuracy_score函数,用于计算模型预测的准确率
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
# 这个数据集包含3种不同品种鸢尾花的测量数据
iris = datasets.load_iris()
# 获取特征数据 - 花瓣和花萼的尺寸测量值
X = iris.data
# 获取目标标签 - 每朵花对应的品种(0=山鸢尾,1=变色鸢尾,2=维吉尼亚鸢尾)
y = iris.target
# 打印目标标签,查看数据中包含哪些品种
print(y)
# 将数据分成训练集和测试集
# 80%的数据用于训练模型,20%的数据用于测试模型效果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建一个逻辑回归分类器
# multi_class='multinomial'表示使用多分类方法处理3种花的问题
lr = LogisticRegression(multi_class='multinomial')
# 使用训练数据训练逻辑回归模型
# 模型会学习如何根据花的特征(花瓣、花萼尺寸)来识别花的品种
lr.fit(X_train, y_train)
# 使用训练好的模型对测试集进行预测
# 模型会根据学习到的规律,预测测试集中每朵花的品种
y_pred = lr.predict(X_test)
# 计算并显示模型在测试集上的准确率
# 准确率表示模型预测正确的比例,是评估模型性能的重要指标
print("准确率:%.2f" % accuracy_score(y_test, y_pred))
4. 小结
本节完整展示了如何训练一个能够识别鸢尾花品种的AI模型,并对其识别能力进行量化评估。通过这一流程,我们可以清晰了解模型是否真正掌握了分类规律及其实际表现水平。
七、最终预测结果展示

八、常见问题排查
1. 缺失scikit-learn库的问题
在PyCharm中运行from sklearn import datasets时,若出现红色波浪线或程序报错,通常意味着未安装scikit-learn库。
缺少该库会导致无法正常使用相关功能,例如:

运行代码后可能出现如下错误提示:
ModuleNotFoundError: No module named 'sklearn'
遇到此类问题无需紧张,这是初学者常见的环境配置问题之一。

根本原因在于:本地Python环境中尚未安装scikit-learn库。
解决方案如下:
- 检查库是否存在:在终端执行以下命令确认是否已安装:
pip show scikit-learn

若返回结果显示未找到该库,则需进行安装。

- 安装scikit-learn库:在终端中运行以下命令进行下载与安装:
pip install scikit-learn

按下回车键后,若出现以下界面内容,则说明下载已成功完成。

接着,可通过执行以下命令来验证 scikit-learn 库是否已正确安装:
pip show scikit-learn
如果系统返回如下所示的信息,则表明 scikit-learn 库已经成功存在于当前环境中,并且信息中还包含了该库的具体版本号。



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





