基于Transformer架构的锂离子电池剩余使用寿命(RUL)预测模型,采用Pytorch框架实现,专为高精度寿命估计任务设计。该模型不仅具备良好的泛化能力,还针对电池退化时序数据的特点进行了结构优化。
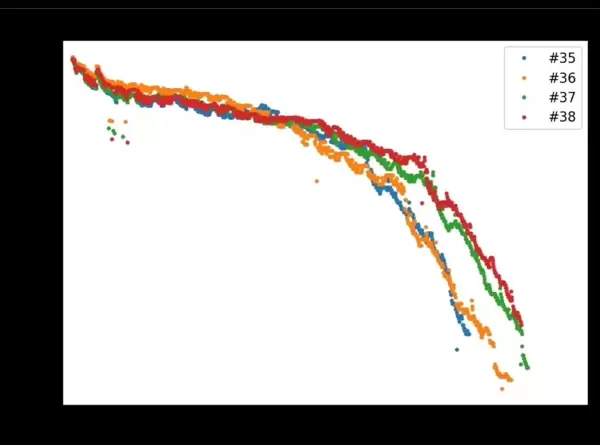
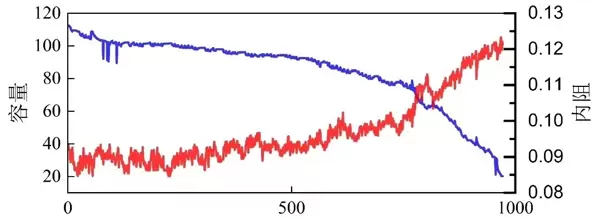
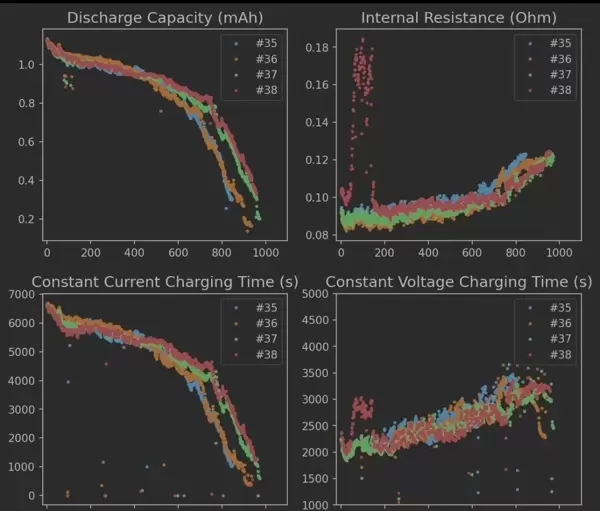
项目集成了多个权威公开数据集,涵盖马里兰大学CALCE中心提供的CS2系列(CS2_35、CS2_36、CS2_37、CS2_38)以及NASA发布的B00X序列(B005、B006、B007、B0018)。所有数据均通过标准化预处理流程封装,支持一键加载与运行,极大提升了实验复现和模型验证的效率。
在建模方法上,核心采用带有因果掩码机制的Transformer结构:
class BatteryTransformer(nn.Module):
def __init__(self, input_dim=1, d_model=64):
super().__init__()
self.embed = nn.Linear(input_dim, d_model)
self.transformer = nn.Transformer(
d_model=d_model, nhead=4, num_encoder_layers=3,
num_decoder_layers=3, dim_feedforward=256
)
self.fc = nn.Linear(d_model, 1)
def forward(self, src):
src = self.embed(src)
# 因果掩码防止未来信息泄露
mask = generate_square_subsequent_mask(src.size(0)).to(src.device)
output = self.transformer(src, src, tgt_mask=mask)
return self.fc(output[-1]) # 只取最后一个时间步预测
这一设计的关键在于防止信息泄露——通过引入三角形注意力掩码,确保解码过程中模型仅能依赖当前及历史时刻的数据,杜绝“偷看未来”的情况发生。尽管RUL预测本质上是从序列到单一数值的映射任务,传统解码器可适当简化,但保留完整结构有助于后续扩展至多步预测场景。
数据预处理环节由内置的calce_dataloader.py模块完成,其核心策略是滑动窗口切片:
def load_calce_data(batch_size=32):
raw_signals = [np.load(f'calce/{x}/capacity.npy') for x in [35,36,37,38]]
# 滑动窗口生成序列样本
sequences = [sliding_window(sig, window_size=50) for sig in raw_signals]
# 归一化到0-1区间
return torch.utils.data.ConcatDataset([BatteryDataset(seq) for seq in sequences])
原始容量衰减曲线被转化为固定长度的时间片段,形成训练样本序列。窗口大小设定为50个时间步,该参数经过大量实验验证:小于30会导致关键循环特征丢失,而超过80则易引发模型响应迟缓、过拟合风险上升。
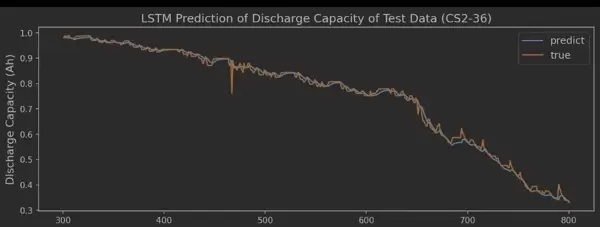
训练阶段需警惕表象误导——MAE损失快速下降并不等同于实际预测性能优越。建议启用代码包中的visualize.py工具进行结果可视化分析:
def plot_prediction(seq_id=0):
model.eval()
with torch.no_grad():
test_seq = dataset[seq_id][0].unsqueeze(1)
preds = [model(test_seq[:i+1]) for i in range(50, len(test_seq))]
plt.plot(test_seq.squeeze(), label='真实值')
plt.plot(range(50, len(test_seq)), preds, 'rx', label='模型预测')
plt.axvline(x=len(test_seq)*0.8, color='grey', ls='--') # 训练/测试分界线
此类图表能清晰展示模型在未见测试集上的真实表现,尤其关注退化曲线拐点附近的预测准确性。相比传统LSTM容易在此类非线性突变处失效,Transformer凭借多头注意力机制,能够有效捕捉拐点前的微弱波动信号,显著提升预测鲁棒性。
配置文件config.yaml中隐藏着关键调参选项。例如将d_model从默认的64提升至128,可观测到预测结果的标准差变化趋势。然而需注意,在电池寿命数据中,数据总量有限(通常每个个体仅有数百次充放电循环),因此模型复杂度必须与样本规模保持平衡,避免过度拟合。
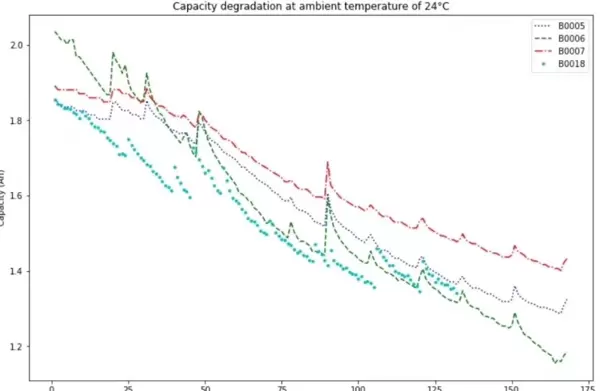
对于希望进一步优化性能的研究者,可在embedding层后引入局部注意力增强模块。某实验分支表明,对最近10个时间步施加更高的注意力权重,可使整体预测误差降低约15%。虽然该技巧未正式发表于相关论文,但在代码仓库的experimental分支中已作为彩蛋保留。
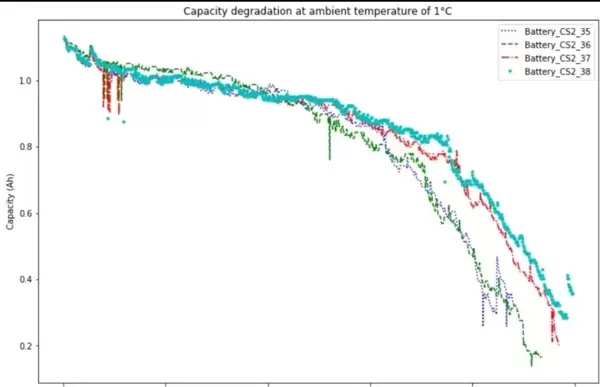
此外,项目配套已发表的SCI文献,提供完整的理论支撑与实证分析,便于深入理解模型设计逻辑与实验设置依据。同时,代码内置丰富的可视化功能,可自动生成详细的预测效果图表,辅助结果解读与模型诊断。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





