经管之家App
让优质教育人人可得
立即打开


当前,AI 大模型训练正面临严峻的算力挑战:动辄数千万美元的算力投入、GPU 服务器价格飙升且供应紧张,同时大量已部署的 GPU 资源利用率低下,调度机制不完善——这些已成为行业普遍存在的“算力焦虑”典型表现。
面对这一困境,三种关键技术路径相继浮出水面。其一是以 NVIDIA 提出的 DGX SuperPOD 为代表的 超节点扩展技术,通过硬件聚合构建高密度计算单元,显著提升单任务训练吞吐能力;其二是华为推出的 Flex:ai 容器软件方案,采用约 10% 的细粒度切分 实现算力虚拟化,打破资源孤岛,官方数据显示可使 NPU/GPU 利用率提升约 30%;其三是由北京大学与阿里巴巴联合研发的 Aegaeon 多模型服务系统,宣称在特定场景下可实现高达约 82% 的 GPU 资源节约。
从技术路线来看,超节点代表了“硬件密集型”的纵向扩展方向,强调通过聚合更多物理算力来增强单任务性能;而虚拟化技术则属于“软件驱动型”,聚焦于更精细的资源分配以提高整体利用率。华为 Flex:ai 与阿里 Aegaeon 正是在两者之间探索融合路径的代表——它们不仅重构了 算力分配与调度 的底层逻辑,也为企业降本增效提供了新的可行选择。
本文将深入解析这三大技术体系,剖析在“虚拟化向左,超节点向右”的格局下,当前算力管理领域的最优技术演进方向。
本节简要介绍支撑上述创新的两大基础技术:GPU 虚拟化与超节点架构。
GPU 虚拟化 技术允许多个虚拟机或容器共享同一块物理 GPU 资源,从而提升设备利用率。如下图所示:
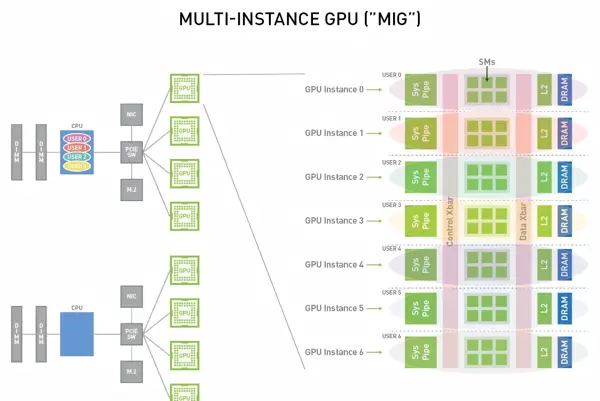
以 NVIDIA 的 MIG(Multi-Instance GPU) 技术为例,单张 GPU 最多可被划分为 7 个相互隔离的虚拟实例,支持多个用户或任务并发使用同一张卡。AMD 方面,则在其数据中心 GPU 中引入 SR-IOV(Single Root I/O Virtualization) 技术,理论上可将一个物理 GPU 分割为最多 16 个 vGPU(虚拟 GPU),实际数量依具体型号而定,每个 vGPU 可独立分配给不同的虚拟机运行环境。
超节点技术 则是另一种解决思路,其核心在于通过高速互联整合大量 AI 加速器(如 GPU 或 NPU),形成规模化、高性能的计算单元。这类系统旨在优化大模型训练中的协同效率和资源利用。如下图所示:
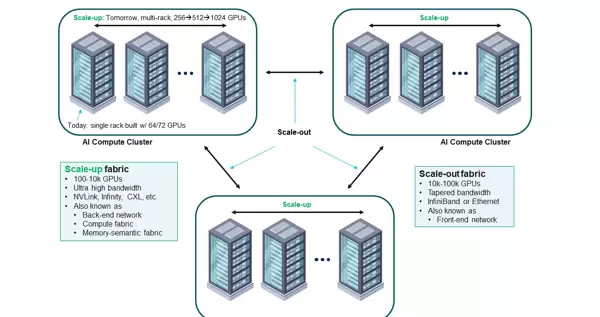
超节点的设计目标包括两个维度:纵向扩展(scale-up) 注重在单个节点或集群内部最大化通信带宽,并尽可能降低加速器之间的通信延迟;横向扩展(scale-out) 则着眼于数据中心级别,实现跨机架甚至跨集群的大规模高效互联与远距离数据传输。典型代表如 NVIDIA NVL72 和华为 CloudMatrix 384 等平台。
尽管超节点、Flex:ai 和 Aegaeon 在实现方式上各具特色,但其共同目标均为解决 GPU 资源利用率低下的问题。三者分别体现了“向右扩张”、“融合协同”、“向左细化”的不同技术取向。
在算力管理体系中,超节点代表了一条“重硬件、强互联”的发展路线,其核心技术特征是“高密度集成 + 低时延互联”。该方案在硬件层采用定制化服务器(如 NVIDIA DGX GB200),在单一节点内集成多张高性能 GPU 并实现 GPU 直连;在网络层则依托 InfiniBand 等高速互联系统,将节点内部及节点间的通信延迟压缩至微秒级,确保大规模并行计算过程中数据流动的高效性。
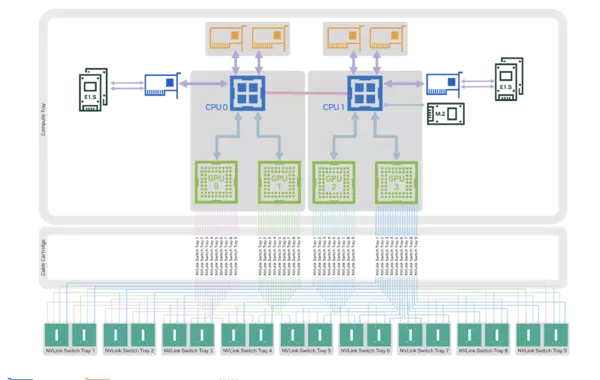
NVIDIA DGX GB200 的机架配置如下图所示,展示了一个包含四个 72-GPU 机架的前视结构:

该架构基于 NVIDIA 的标准机架设计,每个 72-GPU 机架由以下组件构成:
此外,GB200 计算托盘的内部架构框图进一步揭示了其高度集成化的硬件设计逻辑。
Flex:ai 是华为推出的一款容器化软件解决方案,致力于打造跨芯片架构的统一算力池。它通过将物理算力以约 10% 的粒度进行虚拟化切分,实现对 NPU 和 GPU 资源的灵活调度,有效打破不同类型加速器之间的资源壁垒。
该技术的核心优势在于其“软硬协同”的设计理念:一方面兼容多种异构计算设备,另一方面通过精细化资源划分减少空闲浪费。据官方披露,Flex:ai 可使整体加速器利用率提升约 30%,特别适用于多租户、混合负载的企业级 AI 推理与训练场景。
Aegaeon 是由北京大学与阿里巴巴联合提出的一种新型多模型服务系统,专注于提升多任务共存环境下的 GPU 利用效率。其最大亮点在于实现了 Token 级别的动态调度,即根据模型生成过程中的实际需求实时调整资源分配。
传统调度通常以请求或批处理为单位,容易造成资源错配。而 Aegaeon 通过细粒度感知每个 token 的计算消耗,在多个并发模型之间动态调配 GPU 时间片,显著减少了等待与闲置时间。实验表明,该系统在典型负载下可实现最高约 82% 的 GPU 资源节约,尤其适合高并发、低延迟的在线推理服务。
虽然三者均旨在优化算力使用效率,但在适用场景上存在明显差异:
因此,三者的选型应基于业务负载类型、资源分布状况以及性能要求综合判断。
从本质上看,这三项技术并非互斥,而是可以形成互补关系:
理想的技术架构可能是:在由超节点构成的高性能算力底座之上,部署 Flex:ai 进行异构资源整合与池化管理,再结合 Aegaeon 类似的调度系统实现任务级乃至 token 级的智能调度。这种“硬件聚合 + 资源池化 + 精细调度”的三层架构,有望成为未来 AI 基础设施的标准范式。
面对日益加剧的算力供需矛盾,单纯依赖硬件堆叠已难以为继。超节点、Flex:ai 与 Aegaeon 分别从不同维度给出了应对策略:前者强化物理极限,后两者则通过软件手段挖掘现有资源的潜在效能。
未来的算力管理趋势,将是硬件扩展与软件优化深度融合的过程。无论是追求峰值性能,还是关注资源利用率与成本控制,企业都需根据自身业务特点,合理选择并组合运用这些新兴技术,才能在激烈的 AI 竞争中构建可持续的基础设施优势。
在当前大规模人工智能模型的训练与推理场景中,硬件架构的优化成为释放算力潜能的关键。NVIDIA DGX GB200 机架系统采用了一种高度集成的设计,包含 18 个计算节点(即“托盘”),每个托盘搭载两颗 GB200 超级芯片。每颗超级芯片由两块 B200 GPU 和一颗 Grace CPU 构成,整体形成一个统一的 NVLink 域,共集成 72 颗 GPU,构成 72x1 NVLink 拓扑结构。
每个计算托盘还集成了四个 ConnectX-7(CX-7)网卡,支持 InfiniBand NDR(400Gbps)跨机架互联,并配备两个 BlueField-3(BF3)智能网卡,进一步增强网络处理能力。这种设计使得整个系统具备极强的数据协同和通信效率。
该架构天然适配千亿参数级别大模型的训练需求:在需要数百甚至上千张 GPU 协同工作的场景下,超节点通过集群级硬件优化显著提升了整体算力聚合效能。以 NVIDIA DGX SuperPOD 为例,其技术架构通常可分为三个层次:
使用定制化服务器节点,单节点集成 8 张 A100 或 H100 GPU,并借助 NVLink 技术实现节点内部 GPU 间高达 200 GB/s 的直连带宽,有效缓解了数据传输瓶颈。在集群部署上,采用高密度机架设计,每 4 个节点组成一个“计算单元”,从而提升空间利用率与散热效率。
基于 InfiniBand HDR200 高速网络构建,节点间链路带宽可达 200 GB/s,端到端延迟低至 1.2 微秒,相较传统以太网性能提升超过一个数量级。通过对网络拓扑的精细化设计,确保任意两个节点之间的通信延迟基本一致,保障大规模并行任务中的负载均衡与高效通信。
配套部署 NVIDIA AI Enterprise 软件套件,内置模型并行与数据并行优化工具,能够自动将大模型参数分布到多个 GPU 上,并对训练数据进行分片与调度,最大化利用集群算力资源。
在实际应用中,这类超节点架构展现出卓越性能。例如,OpenAI 在训练 GPT-3 模型时采用了具备超节点特征的高性能集群,成功将原本可能耗时“数年”的训练周期压缩至“数月”。国内部分大型科技企业基于 DGX SuperPOD 构建的超节点系统,在千亿参数模型训练上的效率相比普通 GPU 集群提升了约 45%。
然而,极致性能的背后是高昂的成本。一套由 512 张 A100 GPU 组成的 DGX SuperPOD,采购成本通常超过 2 亿元人民币,且每年运维费用约占初始投入的 15%~20%。
此外,随着超节点向更大规模、更高性能方向发展(即“向右”演进),也暴露出若干局限性:
Flex:ai 并非传统的 NPU/GPU 管理工具,而是构建于 Kubernetes 之上的 XPU 算力调度系统,具备“算力切分 + 全局池化 + 智能调度”的核心能力,突破了物理节点与硬件架构之间的隔离边界。

其核心技术主要体现在以下两个方面:
支持将单张 GPU 或 NPU 按 10% 的粒度划分为多个虚拟算力单元,使一张加速卡可同时承载多个 AI 工作负载。根据业务优先级或资源需求,动态调整各虚拟单元的算力配比,避免“一卡一模型”造成的资源闲置。
将集群中所有节点的空闲 XPU 算力整合为统一的“共享算力池”,实现跨节点、跨架构的全局资源调度,让零散的闲置算力也能被高效复用。
在混合异构算力环境中,Flex:ai 展现出明显优势:全面兼容多种架构,既可调度英伟达 GPU,也能接入昇腾 NPU 及其他第三方 AI 芯片,打破单一厂商生态垄断,提升企业在硬件选型上的灵活性。
Aegaeon 的技术价值已在计算机系统领域顶级会议 SOSP 上发表。其论文《SOSP-2025 Aegaeon: Effective GPU Pooling for Concurrent LLM Serving on the Market》详细阐述了该系统如何实现高效的并发大模型服务。
作为一款面向大模型推理场景的调度系统,Aegaeon 实现了 Token 级别的精细化调度能力,能够在多个模型请求之间动态共享 GPU 资源,大幅提升 GPU 利用率与服务吞吐量,尤其适用于多租户、高并发的在线推理平台。
Aegaeon 是一项面向 AI 大模型服务场景的创新性架构设计,其核心在于通过重构服务流程,实现 GPU 资源在多模型环境下的高效共享与精细化调度。该系统引入了“Token 级调度、阶段化计算、缓存复用以及弹性扩缩容”等多层次协同机制,从根源上缓解传统架构中存在的资源浪费问题,推动 GPU 资源向高度池化方向演进。
其整体架构示意图如下所示: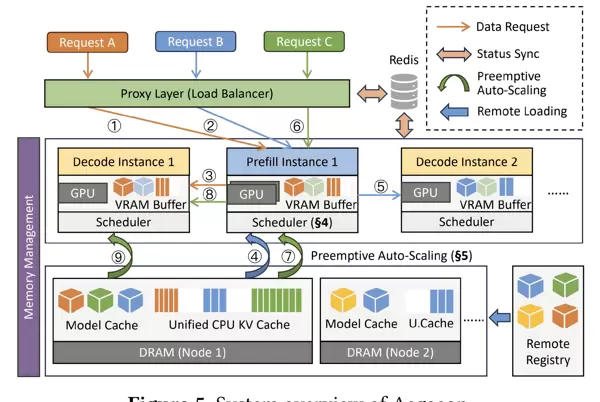
在实际运行中,Aegaeon 以单个 Token(即大模型处理文本的基本单元)作为最小调度单位,动态分配 GPU 计算资源。这种细粒度调度方式打破了传统模型级独占资源的模式,类似于将快递分拣系统从“按批次处理”升级为“每个包裹实时路径规划”,显著提升了资源响应的灵活性与利用率。
系统内置自动扩缩容模块,可根据实时请求流量动态调整各模型所占用的算力比例,在保障服务质量的同时,最大限度减少空转和闲置损耗。实验数据显示:在同时承载 10 个不同模型的服务场景下,所需 GPU 数量由原先的 1192 张降至仅 213 张,资源节约高达 82%,远超当前行业平均水平。
为了抵消精细调度可能带来的性能开销,Aegaeon 采用了一系列优化手段构成“组合拳”策略。例如通过预加载模型参数、优化显存调度逻辑等方式,将模型间切换带来的额外开销降低达 97%,确保高调度精度不以牺牲整体吞吐为代价。
当前主流的算力管理方案主要围绕 GPU 虚拟化与超节点展开,而华为 Flex:ai 和阿里 Aegaeon 则在此基础上探索出融合或细化的新路径。以下从七个关键维度对这四类方案进行系统性比较,帮助厘清各自的技术边界与适用场景:
| 对比维度 | GPU 虚拟化(向左) | 超节点(向右) | 华为 Flex:ai(融合) | 阿里 Aegaeon(细化) |
|---|---|---|---|---|
| 核心目标 | 实现算力资源的灵活复用 | 追求极致并行计算性能 | 兼顾性能与部署灵活性 | 最大化多模型服务效率 |
| 硬件依赖 | 通用 GPU,依赖厂商驱动支持 | 专用服务器 + 高速互联(如 DGX + InfiniBand) | 兼容通用 GPU/NPU,无特殊硬件要求 | 普通 GPU,需软件层面适配 |
| 资源调度粒度 | MIG 或 SR-IOV 固定切片(如 7/8/16 卡) | 整节点或整集群起步(通常 8 张 GPU 起) | 可划分至单卡 10% 的算力单元 | 以 Token 为单位进行调度(解码最小粒度) |
| 典型应用场景 | 单模型稳定推理任务 | 千亿级以上参数模型训练 | 混合负载、多类型任务共存集群 | 多模型并发服务、流量波动明显场景 |
| 成本结构 | 中等采购 + 中等运维(存在资源碎片化浪费) | 高采购 + 高运维(适合大型科技企业) | 低采购 + 低运维(普惠型部署) | 中等采购 + 低运维(聚焦效率优化) |
| 性能损耗 | <10%(主要来自硬件隔离开销) | <5%(得益于深度硬件优化) | 5~10%(轻量级虚拟化带来轻微损耗) | 约 3%(经软件优化后控制良好) |
| 核心矛盾 | 灵活性与执行效率之间的权衡 | 高性能与高成本之间的冲突 | 无明显短板,强调均衡性 | 在特定场景下达到最优,但泛化能力较弱 |
企业在选型时,本质上是在“性能需求、成本预算与业务复杂度”三者之间寻找平衡点。超节点、Flex:ai 与 Aegaeon 并非替代关系,而是分别对应训练、推理及混合负载等多样化场景的互补方案。
从技术路径来看:
综上所述,三者并非互斥,而是可根据实际业务需求形成组合策略:例如在训练阶段采用超节点保障吞吐,在推理侧部署 Aegaeon 提升资源利用率,中间辅以 Flex:ai 实现异构任务统一调度,从而构建覆盖全链路的高效算力管理体系。
在算力需求迅猛增长的背景下,Flex:ai 融合了超节点的算力聚合思想,通过软件手段实现跨节点资源池化,提升整体利用效率。同时,它引入虚拟化技术中的灵活切分机制,以大约 10% 的调度粒度精准匹配多样化的负载类型,增强系统适配能力。
该方案具备广泛的硬件兼容性,既避免了超节点架构封闭、成本高昂的问题,也弥补了 Aegaeon 在通用场景支持上的局限性,因而成为适用于多数应用环境的普适性解决方案。
超节点:服务于大型科技企业的高性能需求
超节点主要面向资金实力雄厚的大型科技公司,如谷歌、Meta 及国内部分头部互联网企业。其核心优势在于显著压缩大模型训练所需周期,为企业赢得关键的时间窗口,在激烈竞争中占据先机。尽管单套系统的采购成本接近 2 亿元,但对于这些企业而言,属于可承受的战略性支出。
Aegaeon:聚焦特定业务场景的高效赋能
Aegaeon 主要应用于云服务商的 AI API 平台以及企业级多模型部署等具体场景。以阿里云为例,在采用 Aegaeon 的调度策略后,10 个常用模型共减少约 900 张 GPU 的使用量,年均节省运维开支近 1 亿元,堪称此类场景下的效率标杆。
Flex:ai:推动普惠算力的开源路径
与前两者不同,Flex:ai 采取开源模式,大幅降低中小企业接入门槛。其跨架构兼容特性允许企业复用现有硬件资源,无需额外投入即可完成升级。实际部署数据显示,GPU 集群利用率可从原有的 35% 提升至 82%,相当于节省约 600 万元的硬件采购费用。凭借低门槛和高适应性,Flex:ai 能够满足从互联网中大型企业到传统行业各类组织的算力管理需求。
面对“向左还是向右”的选择困境,真正的答案始终根植于企业的实际需求之中。超节点通过“纵向扩展”为大模型训练提供强劲性能支撑;Aegaeon 借助“横向细化”实现多模型推理服务的高效运行;而 Flex:ai 则采用“动态均衡”策略,应对混合负载带来的调度挑战。
实践中,企业可采取综合技术路线:利用超节点保障核心大模型训练的性能要求,借助 Aegaeon 提升多模型并发推理的服务效率,并通过 Flex:ai 构建统一的全局算力资源池,实现对各类任务的集中调度。这种整合方式能够在保证性能的同时,最大化资源利用率。
随着人工智能技术持续演进,算力正逐步演变为如同水电一样的基础性设施。Flex:ai 与 Aegaeon 的技术探索,正在加速推进“算力即服务”(Computing Power as a Service)愿景的落地进程。企业将不再受限于底层算力资源的获取与管理复杂性,转而专注于 AI 应用创新与业务价值实现,其余的调度与运维工作则由智能算力管理平台自动完成。
这正是当前算力智能化变革的核心意义所在——让技术回归本质,释放创造力,驱动产业跃迁。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




