DeepSenti v2 是基于深度语义理解构建的新一代情感分析引擎,现已全面支持中文与英文的双语分析,并提供针对不同垂直领域的微调模型,为多样化的文本情感识别场景提供更高效、更精准的技术支持。
核心技术升级
双语情感理解能力增强
v2 版本突破传统单语言处理局限,采用跨语言迁移学习架构,在大规模中英文语料上进行联合训练。该设计不仅能够准确识别中英文混合文本中的情感倾向,还能有效捕捉不同语言文化背景下表达方式的差异性。无论是国内社交媒体的用户评论,还是跨境电商平台上的英文用户反馈,系统均可输出稳定且高质量的情感分析结果。
领域自适应微调模型
为应对各行业文本在语言风格和情感表达上的独特性,我们基于大规模预训练语言模型,实施了领域定向微调(Domain-Adaptive Fine-tuning),并推出以下三类专业优化模型:
- 通用模型:融合新闻、社交媒体、政策文件等多领域数据训练而成,在广泛的应用场景中表现出良好的鲁棒性与一致性。
- 电商模型:专为商品评价与用户反馈优化,深入解析消费者对产品功能、物流体验、价格感知等维度的情感态度,助力企业精准把握市场反馈。
- 学术论文模型:可识别学术文献中的评价性语言,准确判断作者对研究方法、实验结果及理论贡献的认可或质疑,适用于文献综述与科研趋势分析。
推理性能显著提升
通过引入 INT8 模型量化、算子融合以及动态批处理技术,v2 在保障分析精度的前提下,将整体推理速度提升约 3 倍,单条文本处理响应时间缩短至秒级,满足大规模文本实时分析的需求。
精度提升的关键技术路径
- 采用对比学习(Contrastive Learning)策略,强化模型对细微情感差异的判别能力;
- 改进多头自注意力机制(Multi-head Self-Attention),更精确地定位文本中影响情感判断的核心片段;
- 融合预训练模型的深层语义表征,提高对隐喻、反讽等复杂修辞手法的识别准确率。
核心功能特性
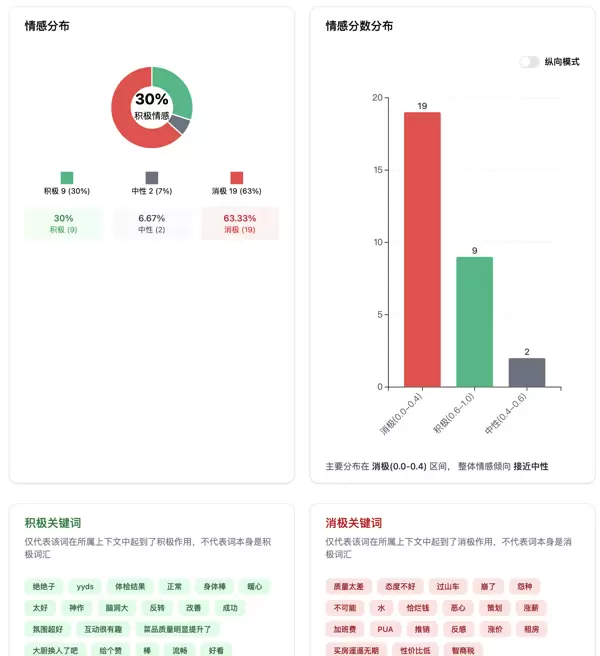
情感倾向分类
支持对输入文本进行积极、中性、消极三类情感划分,并附带置信度评分,便于快速掌握整体情绪分布态势。
情感关键词提取
作为 v2 的重要创新点,系统不仅能输出整体情感判断,还可自动识别每句话中起主导作用的积极或消极关键词。借助注意力权重机制,精准锁定影响情感判定的关键表达,增强分析结果的可解释性。
示例:
原句:"这款手机拍照效果很棒,但续航能力令人失望"
提取结果:积极词汇["拍照效果很棒"],消极词汇["续航能力令人失望"]
此功能有助于深入理解用户真实诉求,识别产品优势与改进空间。
结构化数据输出与可视化支持
系统支持将分析结果以结构化形式导出,便于后续处理与深度挖掘:
- CSV 格式导出:包含原文、情感类别、置信度、积极词汇、消极词汇等字段;
- 可视化分析图表:自动生成情感分布图、趋势变化曲线等图形化展示,直观呈现情感动态;
- 批量分析报告:汇总统计信息,如整体情感占比、高频情感词云等关键指标。
典型应用场景
- 舆情监测:实时追踪公众情绪波动,结合情感关键词快速定位社会关注焦点;
- 电商评论分析:从海量用户评价中提取正负面关键词,精准识别产品亮点与痛点;
- 学术文献研究:批量分析论文立场倾向,提取关键评价语句,辅助科研评估与知识发现;
- 用户体验研究:深度挖掘用户反馈中的情感信号,量化满意度水平;
- 政策反馈评估:分析民众对公共政策的情绪反应,识别引发争议的具体条款或措施。
技术参数概览
- 支持语言:中文、英文(支持混合输入);
- 模型架构:基于 Transformer 的预训练+微调范式;
- 处理能力:支持从单条文本到百万级文档的批量处理;
- 准确率表现:通用场景下 F1 值达 0.89 以上,垂直领域微调模型可达 0.92+;
- 响应速度:平均单条推理时间小于 50ms。
使用方式便捷灵活
- 无需编程,通过网页界面即可完成操作,选择对应领域模型后立即开始分析;
- 支持 TXT、CSV、Excel 等多种格式文件的批量上传;
- 分析完成后自动生成结构化 CSV 数据与可视化图表;
- 结果支持在线预览与一键下载,方便后续研究与汇报使用。
DeepSenti v2,致力于让情感分析更加精准、透明与实用。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





