经管之家App
让优质教育人人可得
立即打开


在进行网页自动化或简易爬虫开发时,多数人首先想到的是 Selenium。然而,在 Python 的生态体系中,还有一个更加轻便且易于上手的替代方案——DrissionPage。
本文将通过三个逐步深入的代码实例,引导你完成一条完整的自动化流程:
不堆砌理论术语,重点聚焦于“代码实际做了什么”以及“其背后的实现逻辑”。
本部分以 Windows 操作系统为例,介绍如何完成 DrissionPage 的安装及基础功能验证。前提是已正确安装 Python 3 环境。
在 Windows 系统中,可通过以下步骤打开命令提示符:
cmd;
后续所有安装与测试命令均在此窗口中执行。
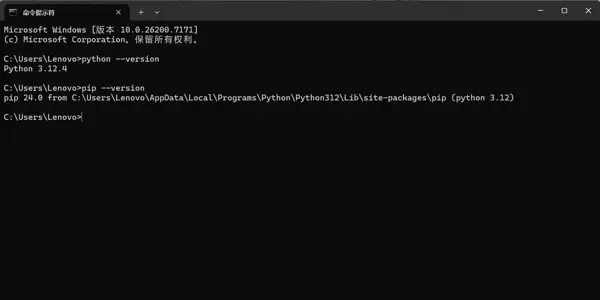
在终端中依次运行以下两条命令:
python --version
pip --version若返回结果类似如下输出:
Python 3.x.x pip 24.x from ...
则表明 Python 解释器和包管理工具 pip 均处于正常工作状态,可以继续下一步操作。
如果出现“不是内部或外部命令”等错误提示,则需先配置或修复 Python 运行环境。
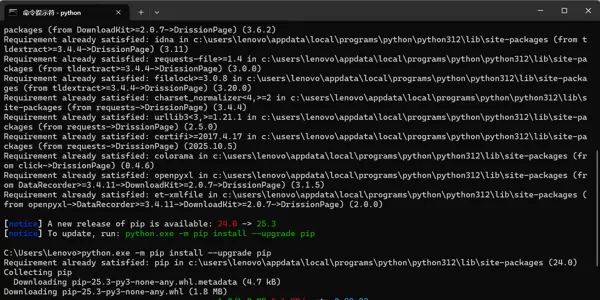
为提升下载速度与稳定性,推荐使用阿里云 PyPI 镜像源进行安装:
pip install DrissionPage -i https://mirrors.aliyun.com/pypi/simple/
各参数含义如下:
安装成功后,终端通常会显示 Successfully installed DrissionPage-... 提示信息。
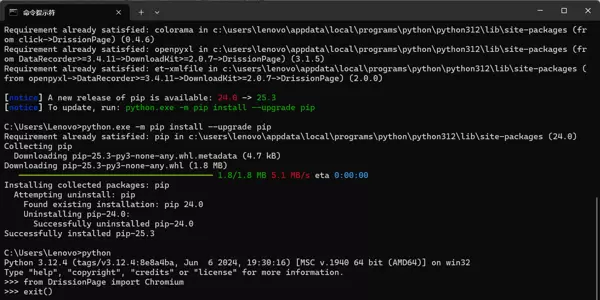
建议安装完成后进行一次最小化测试:
在命令行中启动 Python 交互环境并输入:
pythonfrom DrissionPage import Chromium
如果没有任何报错信息,说明 DrissionPage 已可以正常导入。若无报错,则说明模块导入成功。输入 exit() 或按下 Ctrl + Z 后回车退出交互模式。
至此,DrissionPage 的安装与基础环境校验已完成,可进入下一阶段的浏览器控制实践。
确认环境配置无误后,接下来让程序真正启动一个浏览器实例,并加载指定网页。以下是基础示例代码。
from DrissionPage import Chromium
# 创建浏览器对象
page = Chromium()
# 获取当前标签页
tab = page.get_tab()
# 访问百度首页
tab.get("https://www.baidu.com")
from DrissionPage import Chromium
从 DrissionPage 模块中引入 Chromium 类,该类用于创建基于 Chromium 内核的浏览器实例。
page = Chromium()
实例化一个浏览器对象 page。执行此语句时,系统会自动启动一个由 DrissionPage 控制的浏览器进程,通常可见独立窗口弹出。
tab = page.get_tab()
获取当前默认激活的标签页对象。后续所有页面级操作(如跳转、元素查找等)都将通过该 tab 对象完成。
tab.get("https://www.baidu.com")
指令该标签页访问百度主页 URL,完成页面加载动作。
网页自动化常涉及对特定元素的识别与提取,XPath 是一种高效精准的定位方式。以下展示如何结合开发者工具与 DrissionPage 实现热搜词抓取。
# 假设 tab 已存在且已打开百度首页
hot_search_elements = tab.eles('xpath://div[@class="title-content"]//a')
for item in hot_search_elements:
print(item.text)
在浏览器中打开百度首页,右键点击热搜词条并选择「检查」或「审查元素」,调出开发者工具面板。观察对应 HTML 节点结构,找到具有唯一性特征的路径表达式,例如包含特定 class 名称的 div 或 a 标签。
通过复制完整 XPath 或手动编写更简洁的选择器,确保能准确匹配目标节点集合。
使用 tab.eles() 方法传入 XPath 字符串,返回符合条件的所有元素列表。若只需单个元素,可使用 tab.ele()。
每个元素对象提供多种属性与方法,如 .text 获取文本内容,.href 获取链接地址等。
进一步拓展应用场景,演示如何进入详情页抓取结构化内容,并实现本地持久化存储。
# 进入某新闻链接
tab.get("https://example-news-site.com/article/123")
# 提取标题与正文
title = tab.ele('tag:h1').text
content = tab.ele('tag:article').text
# 写入本地文件
with open('news.txt', 'w', encoding='utf-8') as f:
f.write(f"标题:{title}\n\n正文:\n{content}")
通过 tab.get(url) 跳转至具体新闻页面,等待页面加载完毕后再执行元素提取操作。
使用 Python 内置的 open() 函数以写入模式打开文件,指定 UTF-8 编码防止中文乱码。将提取的标题与正文按格式拼接后写入磁盘,形成可长期保存的数据文件。
ele():用于获取第一个匹配的元素,适用于唯一存在的目标(如标题、主图等);
eles():返回所有匹配元素组成的列表,适合处理重复结构(如热搜列表、评论区等)。
根据实际需求选择合适的方法,是提高脚本效率与稳定性的关键。
DrissionPage 支持完整浏览器生命周期管理,包括启动、关闭、标签页切换、页面刷新、前进后退等操作,满足常见 RPA 场景需求。
支持多种选择器语法(XPath、CSS、标签名、属性等),能够灵活应对动态页面与复杂 DOM 结构,实现精准抓取。
结合 Python 原生文件操作或第三方库(如 csv、json、pandas),可将采集数据导出为文本、表格或数据库记录,便于后续分析处理。
当浏览器窗口成功启动后,可以观察到地址栏自动填充目标 URL 并加载对应页面内容。

至此,我们已经完成了网页 RPA 的一个核心基础步骤:通过代码自动控制浏览器打开页面并访问指定站点,而非依赖人工操作。
仅仅实现页面访问并不足以体现网页自动化的真正能力。其关键价值在于能够精准识别页面中的特定元素,并对其进行文本提取或点击等交互操作。以下以“获取百度首页第一条热搜标题”为例进行演示。
from DrissionPage import Chromium
page = Chromium()
tab = page.get_tab()
tab.get("https://www.baidu.com")
# 使用 XPath 获取第一条热搜的标题元素
title = tab.ele('xpath://*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]')
# 输出该元素的文本内容
print(title.text)

核心语句如下:
title = tab.ele('xpath://*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]')
说明:
tab.ele(selector):用于在当前标签页中根据选择器查找单个元素;xpath: 开头,表示后续内容采用 XPath 语法;title.text 即可输出其内部纯文本内容,即第一条热搜的标题。由此可总结出一套清晰的操作流程:
tab.ele('xpath:...') 实现元素定位;.text 或其他属性/方法提取所需数据。
掌握基本的元素定位技术后,便可进一步将网页内容提取并存储到本地,便于后续处理与分析。下面以澎湃新闻网的一篇新闻文章为例,演示如何抓取标题和正文,并写入名为“新闻.txt”的文本文件中。
from DrissionPage import Chromium
page = Chromium()
tab = page.get_tab()
tab.get("https://www.thepaper.cn/newsDetail_forward_26649723")
# 以 UTF-8 编码方式打开文件,支持中文内容写入
f = open("新闻.txt", "w", encoding="utf-8")
# 提取新闻标题并通过 XPath 写入文件
title = tab.ele('xpath://*[@id="__next"]/main/div[4]/div[1]/div[1]/div/h1')
print(title.text)
f.write(title.text)
# 提取正文容器内容并追加换行后写入
context = tab.ele('xpath://*[@id="__next"]/main/div[4]/div[1]/div[1]/div/div[3]')
print(context.text)
f.write("\n" + context.text)
# 关闭文件流,确保数据完整写入磁盘
f.close()
执行以下命令可在浏览器中跳转至指定新闻页面:
tab.get("https://www.thepaper.cn/newsDetail_forward_26649723")
该步骤会自动加载目标 URL 所对应的新闻详情页。
代码片段:
f = open("新闻.txt", "w", encoding="utf-8")
含义说明:
后续操作包括:
f.write(title.text)
f.write("\n" + context.text)
f.close()
实现功能如下:
\n;f.close() 关闭文件句柄,确保所有内容持久化保存。
上述示例中,正文是作为一个整体容器提取的。如果需要对正文逐段处理,则应使用 eles() 方法,它返回多个匹配的元素列表。例如:
主要差异在于:
在处理新闻条目、评论列表等包含多个重复结构的场景时,使用 eles() 更适合进行批量数据提取与操作。
通过前述三个实例可以看出,DrissionPage 在网页自动化任务中具备清晰的操作逻辑和强大的功能性。总体来看,其核心能力可归纳为以下三个方面:
利用 ChromiumPage 或 Chromium 类创建浏览器实例,实现对真实浏览器的控制。通过调用 get_tab() 获取当前标签页对象,并使用 tab.get(url) 在指定页面中跳转至目标网址。
该能力模拟了“手动打开浏览器并输入网址”的基本流程,是实现自动化的第一步。
借助 XPath 表达式(可编写或复制),结合 tab.ele('xpath:...') 或 tab.eles('xpath:...') 实现对特定元素的精准定位。获取元素对象后,可通过其 .text 属性提取标签内的纯文本内容。
这一功能是完成自动填写表单、模拟点击按钮、抓取网页内容等高级操作的基础支撑。
通过 Python 内置的 open(..., "w", encoding="utf-8") 方法创建或覆盖文本文件,配合 write() 和换行符 \n 组织输出格式。最终使用 close() 显式关闭文件流,或更推荐地采用 with 上下文管理器确保数据完整写入磁盘。
一旦将网页数据保存至本地文件系统,即可开展后续的数据清洗、统计分析或可视化展示等工作。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




