经管之家App
让优质教育人人可得
立即打开



在大语言模型(LLM)持续演进的过程中,推理能力的构建长期依赖于训练后的辅助手段。从思维链(CoT)到工具增强策略,尽管这些方法在任务表现上有所提升,但其本质缺陷始终存在:推理过程与预训练阶段相互割裂,导致参数利用率低、推理路径缺乏因果一致性。
2025年11月,字节跳动Seed团队联合加州大学、北京大学等国际顶尖研究机构,推出循环语言模型(Looped Language Models, LoopLM)系列——Ouro。该名称源自象征自我迭代与无限循环的衔尾蛇(Ouroboros),标志着首次将推理能力直接内化于预训练流程之中。通过引入潜在空间中的多步迭代计算机制、熵正则化目标函数,并依托高达7.7T tokens的超大规模数据训练,Ouro实现了2至3倍的参数效率跃升,为LLM的发展开辟了全新的技术路径。
本文将深入剖析Ouro的技术原理、架构创新、训练策略及实际性能表现,同时提供可运行的代码示例,帮助开发者快速掌握这一颠覆性模型的核心实现。
主流的Transformer模型在发展过程中暴露出两个根本性问题:
虽然传统RNN具备天然的循环特性,但由于梯度消失问题难以处理长序列依赖;LSTM与GRU虽通过门控机制缓解此问题,却仍未解决推理行为与预训练目标之间的融合难题。Ouro的LoopLM架构创造性地结合了Transformer的并行优势与循环系统的动态推理能力,成功实现计算深度与参数数量的解耦。
LoopLM之所以具有革命性意义,在于其实现了以下三项关键创新:
如图1所示,Ouro的架构从根本上重构了计算范式——由传统的“静态层堆叠”转变为“动态循环迭代”,实现了模型行为的本质升级。
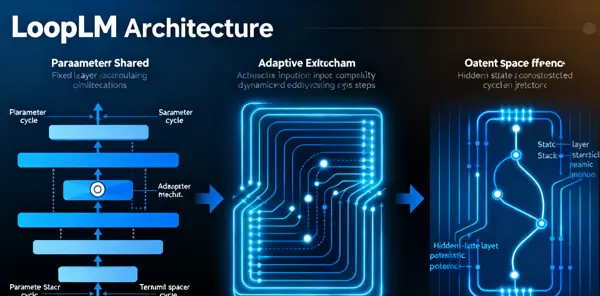
Ouro的核心架构由“共享Transformer层堆 + 可控循环机制”构成,其运作逻辑如下:
给定输入序列 $ X = [x_1, x_2, ..., x_T] $,首先经嵌入层转换为向量表示 $ E = [e_1, e_2, ..., e_T] $。随后,一个包含N层共享权重的Transformer模块被反复调用。在每个循环步 $ r \in [1, R] $ 中,隐藏状态更新公式为:
\( H_r = \text{SharedTransformer}(H_{r-1}, E) \)
其中初始状态 $ H_0 = E $,$ R $ 表示最大允许循环次数。这种设计使得同一组参数可在不同时间步中多次参与信息整合,从而模拟深层推理过程。
为了实现对计算资源的智能分配,Ouro引入了一个学习型退出门。在每一步 $ r $,系统会预测是否终止循环的概率 $ p_r $:
\( p_r = \sigma(W_o \cdot \text{avg}(H_r) + b_o) \)
这里 $ \sigma $ 是sigmoid激活函数,$ \text{avg}(H_r) $ 表示当前隐藏状态的全局平均池化结果。通过引入熵正则化目标 $ H(p_1, ..., p_R) $,模型被鼓励形成合理的退出策略:简单任务尽早结束,复杂任务则允许多轮迭代。
Ouro采用融合式损失函数,同时优化语言建模能力和推理控制策略:
\( \mathcal{L} = \mathbb{E}_{r \sim p}[\mathcal{L}_{\text{LM}}(H_r)] + \lambda \cdot H(p_1, ..., p_R) \)
其中 $ \mathcal{L}_{\text{LM}} $ 为标准交叉熵语言建模损失,$ \lambda $ 控制正则项强度。该设计使模型在学习语言规律的同时,也学会判断何时以及如何进行深层次推理。
Ouro的训练共经历七个阶段,累计使用7.7T tokens的多样化数据集,涵盖网页文本、数学表达式、编程代码及超长文档等类型。各阶段安排如下:
| 训练阶段 | 数据量 | 核心目标 |
|---|---|---|
| 预热阶段 | 200B tokens | 初始化模型参数,确保训练稳定性 |
| 初始稳定训练 | 3T tokens | 建立基础语言理解与上下文捕捉能力 |
| 第二次稳定训练 | 3T tokens | 进一步巩固语义表征与通用知识吸收 |
后续阶段逐步引入更具挑战性的推理密集型数据,并配合课程学习策略,引导模型从浅层建模过渡到深层循环推理,最终实现端到端的自主推理能力内化。
在模型架构设计中,团队通过引入 CT 退火机制,结合 LongCT 训练方法,显著提升了长上下文处理能力。整体训练流程包含多个关键阶段:
此外,退出门策略也经过精细化调整,进一步优化了计算资源的动态分配。值得注意的是,在早期实验中发现,当设置为 8 个循环步时会出现明显的损失尖峰现象。为平衡计算深度与训练稳定性,最终确定采用 4 个循环步作为标准配置。
Ouro 当前公开发布两个基础模型及其对应的推理增强版本,具体信息如下表所示:
| 模型名称 | 参数量 | 循环步数 | 核心特性 |
|---|---|---|---|
| Ouro-1.4B | 14 亿 | 4 | 通用基础模型,具备最优的参数效率 |
| Ouro-2.6B | 26 亿 | 4 | 性能与效率均衡,支持长上下文输入 |
| Ouro-1.4B-Thinking | 14 亿 | 4 | 专为数学与科学任务优化的推理增强版 |
| Ouro-2.6B-Thinking | 26 亿 | 4 | 旗舰级推理模型,适用于复杂多步逻辑推导 |
所有模型均已开源并托管于 Hugging Face Hub,支持 PyTorch 和 TensorFlow 框架调用,便于开发者集成与部署。
评估覆盖六大核心领域,全面衡量模型综合能力:
对比基线包括 Qwen3 系列、DeepSeek-Distill 以及 Llama 3 模型。所有测试统一在 A100 GPU 环境下执行,确保结果公平可比。
如图 2 所示,Ouro 系列模型在仅使用基线模型 1/3 至 1/2 参数量的情况下,仍能达到甚至超越其性能水平:
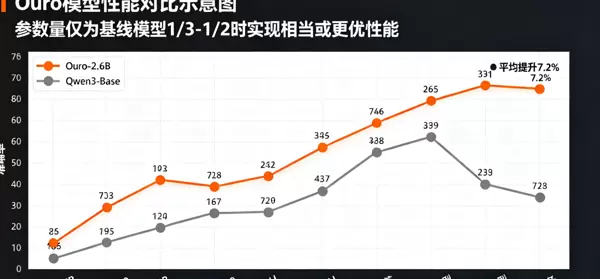
图 2:Ouro 模型与基线模型在六大任务上的性能对比,红色代表 Ouro 系列,灰色为基线模型
得益于自适应退出机制,Ouro 实现了高效的计算资源利用:
Ouro 在 HEx-PHI 安全基准测试中展现出卓越表现:
推荐通过 pip 安装稳定版本以获得最佳兼容性:
# pip安装
pip install ouro==0.2.0
# 从源码安装
git clone https://github.com/ByteDance/ouro.git
cd ouro
pip install .运行依赖如下:
可通过 Hugging Face Transformers 接口轻松调用 Ouro 模型完成文本生成任务:
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和Tokenizer
model_name = "ByteDance/ouro-1.4B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="auto"
)
# 输入文本
prompt = "解释什么是循环语言模型,并说明其与传统Transformer的核心区别。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 生成文本(启用自适应循环)
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
do_sample=True,
adaptive_loop=True # 启用自适应退出机制
)
# 解码输出
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成结果:")
print(response)针对数学推理等高阶任务,可显式指定循环步数并启用推理增强模式以提升准确性:
# 数学推理任务
math_prompt = """
解方程:2x? - 5x + 2 = 0
要求:分步展示求解过程,包括判别式计算和求根公式应用。
"""
inputs = tokenizer(math_prompt, return_tensors="pt").to(model.device)
# 强制使用4个循环步,优化推理质量
outputs = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.1, # 降低随机性
top_p=0.95,
do_sample=False,
adaptive_loop=False, # 禁用自适应退出
num_loop_steps=4 # 固定4个循环步
)
math_response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("数学推理结果:")
print(math_response)若需进行二次开发或结构改造,可基于 Ouro 提供的核心模块构建个性化循环神经网络:
import torch
import torch.nn as nn
from transformers import PreTrainedModel, PretrainedConfig
class OuroConfig(PretrainedConfig):
model_type = "ouro"
def __init__(
self,
vocab_size=50257,
embedding_dim=2048,
hidden_dim=2048,
num_layers=8, # 共享层数量
max_loop_steps=4, # 最大循环步数
dropout=0.1,
**kwargs
):
super().__init__(**kwargs)
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.max_loop_steps = max_loop_steps
self.dropout = dropout
class SharedTransformerLayer(nn.Module):
"""共享权重的Transformer层"""
def __init__(self, hidden_dim, dropout=0.1):
super().__init__()
self.self_attn = nn.MultiheadAttention(hidden_dim, 8, dropout=dropout)
self.linear1 = nn.Linear(hidden_dim, 4 * hidden_dim)
self.linear2 = nn.Linear(4 * hidden_dim, hidden_dim)
self.norm1 = nn.LayerNorm(hidden_dim)
self.norm2 = nn.LayerNorm(hidden_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 自注意力层
attn_output, _ = self.self_attn(x, x, x)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# 前馈网络
ff_output = self.linear2(torch.relu(self.linear1(x)))
x = x + self.dropout(ff_output)
x = self.norm2(x)
return x
class OuroModel(PreTrainedModel):
config_class = OuroConfig
def __init__(self, config):
super().__init__(config)
self.embedding = nn.Embedding(config.vocab_size, config.embedding_dim)
self.shared_layers = nn.ModuleList([
SharedTransformerLayer(config.hidden_dim, config.dropout)
for _ in range(config.num_layers)
])
self.exit_gate = nn.Sequential(
nn.Linear(config.hidden_dim, 1),
nn.Sigmoid()
)
self.lm_head = nn.Linear(config.hidden_dim, config.vocab_size)
self.config = config
def forward(self, input_ids, labels=None):
batch_size, seq_len = input_ids.shape
# 嵌入层
x = self.embedding(input_ids) # (batch_size, seq_len, embedding_dim)
x = x.transpose(0, 1) # (seq_len, batch_size, embedding_dim)
loop_losses = []
exit_probs = []
hidden_states = []
for r in range(self.config.max_loop_steps):
# 循环应用共享层
for layer in self.shared_layers:
x = layer(x)
hidden_states.append(x)
# 计算退出门概率
avg_hidden = x.mean(dim=0) # (batch_size, hidden_dim)
exit_prob = self.exit_gate(avg_hidden) # (batch_size, 1)
exit_probs.append(exit_prob)
# 计算语言建模损失
lm_logits = self.lm_head(x.transpose(0, 1)) # (batch_size, seq_len, vocab_size)
if labels is not None:
lm_loss = nn.CrossEntropyLoss()(
lm_logits.reshape(-1, self.config.vocab_size),
labels.reshape(-1)
)
loop_losses.append(lm_loss)
# 计算总损失(融合循环损失与熵正则化)
if labels is not None:
exit_probs_tensor = torch.stack(exit_probs, dim=1) # (batch_size, max_loop_steps)
entropy = -torch.sum(exit_probs_tensor * torch.log(exit_probs_tensor + 1e-8), dim=1).mean()
weighted_loss = torch.stack(loop_losses, dim=1) * exit_probs_tensor
total_loss = weighted_loss.sum(dim=1).mean() + 0.01 * entropy
return {"loss": total_loss, "logits": lm_logits}
return {"logits": lm_logits, "hidden_states": hidden_states}
# 初始化自定义模型
config = OuroConfig()
model = OuroModel(config)
print(f"自定义Ouro模型参数量:{sum(p.numel() for p in model.parameters()) / 1e8:.2f}亿")凭借独特的多步循环机制,Ouro 能够生成具有因果一致性的推理轨迹,适用于多种需要深度逻辑推演的场景,例如:
得益于出色的参数效率,Ouro 可在边缘设备(如移动终端、嵌入式系统)上实现低延迟运行,典型应用包括:
经由 LongCT 阶段专项训练,Ouro-2.6B 支持最大 8192 tokens 的输入长度,适合以下任务:
由于其较低的有害内容生成倾向,Ouro 特别适用于对安全性要求较高的领域:
团队将持续推进 Ouro 生态体系建设,推动模型在更多垂直领域的落地应用,并计划在未来版本中引入更灵活的动态计算机制与更强的跨模态能力。
字节跳动团队已成功构建了完整的 Ouro 生态体系,涵盖多个关键模块:
开源仓库:在 GitHub 上提供了完整的训练代码、模型权重以及示例脚本,便于开发者快速上手与二次开发;
Hugging Face 集成:全面支持 Transformers 标准接口,能够无缝对接现有 NLP 工作流,提升集成效率;
开发者社区:通过 Discord 和 GitHub Discussions 提供活跃的技术交流平台,帮助用户解决使用中的各类问题;
行业合作:联合教育、科研及工业领域的合作伙伴,共同探索和落地实际应用场景。
未来的发展规划包括以下几个方向:
尽管 Ouro 在多项任务中展现出卓越性能,仍面临若干技术挑战,团队已提出相应解决方案:
训练稳定性:由于采用多循环步训练机制,可能出现梯度震荡现象。为此引入梯度裁剪策略,并结合动态学习率调度方法进行缓解;
循环步优化:当前的动态退出机制在判断精度方面仍有改进空间,后续计划引入强化学习方法以提升决策准确性;
领域适配:针对专业领域数据在循环推理中的适应性不足问题,将开发专门的领域自适应预训练工具,增强模型在特定场景下的泛化能力。
Ouro 循环语言模型的推出,标志着大型语言模型正从“堆叠参数”向“追求效率”的范式转变。其核心创新在于将推理过程前移至预训练阶段,借助参数共享的循环结构、自适应退出机制以及熵正则化目标函数,实现了参数利用效率与推理表现的双重提升。实验证明,仅 1.4B 参数的 Ouro 模型即可达到与 4B 规模 Transformer 模型相当的性能,验证了循环架构作为新型扩展路径的可行性。
从技术角度看,Ouro 不仅有效缓解了传统 LLM 在长序列推理中的效率瓶颈,更提出了一种全新的设计思路——将计算深度与参数量解耦,为大模型的轻量化与高效化发展提供了重要参考。从应用视角出发,得益于较低的资源消耗和更高的运行安全性,Ouro 可广泛部署于边缘设备、企业本地系统等多种环境,推动人工智能技术向更普惠的方向演进。
随着 Ouro 生态系统的持续完善与模型能力的不断迭代,循环语言模型有望继 Transformer 之后,成为下一代主流架构之一,在 AI 推理效率革命中扮演关键角色。其全面开源的特性也为广大研究者和开发者提供了广阔的创新空间,无论是在基础理论探索还是实际工程落地层面,均具备重要的借鉴价值。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




