BERT(Bidirectional Encoder Representations from Transformers)是2018年由Google提出的一种基于Transformer架构的深度双向编码器模型,它的问世彻底改变了自然语言处理(NLP)的研究范式。该模型通过创新性的预训练机制,在多项核心语言任务中实现了前所未有的性能突破,成为NLP发展史上的关键里程碑。
其核心技术优势在于引入了掩码语言模型(MLM),实现了真正意义上的双向语境理解,能够同时利用上下文中的左右信息进行语言表示学习。这种设计使BERT在处理一词多义、指代消解和复杂语义推理等任务时展现出远超传统模型的能力。
实验结果表明,BERT在包括GLUE、MultiNLI和SQuAD在内的11项主流NLP任务上均取得显著提升:GLUE基准得分达到80.5%(绝对提升7.7%),MultiNLI准确率升至86.7%(提升4.6%),SQuAD v1.1问答任务F1分数高达93.2(提升1.5分),甚至在部分指标上超越人类水平。这些成果充分验证了其强大的泛化能力和学术研究价值。
此外,BERT推动了整个领域向“预训练+微调”这一新范式的转型。自发布以来,已有超过10,000篇相关学术论文围绕其展开扩展与优化研究,确立了其在现代自然语言处理中的基础性地位。
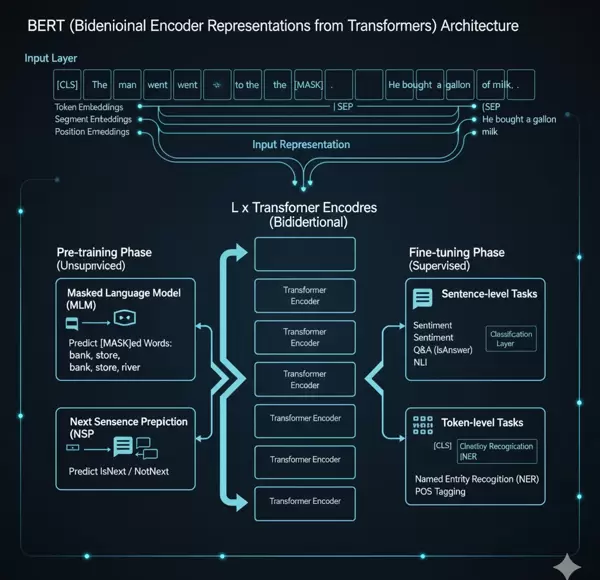
从单向建模到深度双向理解的范式跃迁
自然语言处理的核心挑战在于让机器具备对语义的深层理解能力。早期的RNN、LSTM等序列模型受限于单向处理机制,难以全面捕捉词语之间的长距离依赖关系。2018年,Google提出的BERT模型借助Transformer结构的双向编码能力,从根本上解决了这一瓶颈问题。
其成功的关键在于两个核心要素:双向性设计与掩码语言模型(MLM)预训练目标。通过允许模型在训练过程中同时访问前后文信息,BERT能够构建更加丰富和准确的语言表征。这使其在面对如歧义消除、逻辑推理和篇章连贯性判断等复杂任务时表现尤为突出。
更重要的是,BERT标志着NLP研究哲学的重大转变——从过去依赖大量人工特征工程的任务特定模型,转向以大规模无监督数据为基础的通用语言模型预训练路径。只需在下游任务上进行轻量级微调,即可获得领先性能,极大提升了开发效率与模型适应性。
本文将从学术角度系统剖析BERT双向编码架构的技术原理,并探讨其在自然语言理解、问答系统及文本分类等关键应用场景中的卓越表现与深远影响。
一、BERT双向编码架构的核心技术优势
1.1 深度双向语义理解:突破单向限制
传统的自回归语言模型(如GPT系列)只能按顺序从左至右进行文本建模,无法获取未来上下文信息。而BERT采用的双向编码器结构则打破了这一局限,能够在训练阶段同时融合前后语境,实现真正的双向语义建模。
优势体现: 在需要精准语义辨析的任务中效果显著。例如,“bank”一词可能指金融机构或河岸,仅靠前序词汇难以判断;而BERT凭借完整的上下文感知能力,可有效区分不同语义场景,提升消歧准确性。
自注意力机制的作用: Transformer中的自注意力模块使得序列中任意位置的词都可以直接关注其他所有位置的词元,从而高效捕获远距离语义关联。通过堆叠多层编码器,BERT逐步构建出层次化、深层次的双向语言表示体系。
1.2 创新预训练策略:MLM与NSP双任务驱动
BERT的成功很大程度上归功于其独特的预训练方式,尤其是掩码语言模型(MLM)的设计。
MLM机制详解: 在输入序列中随机选择约15%的词元进行掩盖,要求模型根据完整上下文预测原始词汇。这种方式避免了单向建模的局限,实现了真正的双向训练。
为缓解预训练与微调阶段的数据分布差异,BERT采用了更精细的替换策略:
- 80% 的情况下用 [MASK] 替换被选中的词
- 10% 的情况下替换为随机词汇
- 10% 的情况下保持原词不变
这种混合策略增强了模型鲁棒性,使其在真实应用中更具适应力。
[MASK]
[MASK]
此外,BERT还引入了下一句预测(NSP)任务,即判断两个句子是否在原文中连续出现。该任务对于涉及句子间关系的任务(如问答、自然语言推理)具有重要意义,帮助模型学习篇章级别的语义连贯性。
1.3 统一架构带来的广泛适应性
BERT基于标准的Transformer编码器结构,具备高度统一的框架设计,几乎无需修改网络结构即可适配多种NLP任务。
标准化输入格式: 所有输入序列均使用特殊标记进行结构化处理:
- [CLS] 标记用于句子级别任务(如分类),作为聚合表示输出
- [SEP] 标记用于分隔句子对(如问答对或句子相似度判断)
- 同时引入段嵌入(Segment Embeddings)以区分不同句子来源
[CLS]
[SEP]
跨任务兼容性: 此种统一输入与编码方式,使BERT既能胜任句子级任务(如情感分析、文本蕴含),也能应用于标记级任务(如命名实体识别、词性标注)。开发者仅需添加简单的输出层并通过微调即可快速部署,大幅降低了模型定制成本。
二、BERT在核心NLP任务中的学术表现与研究潜力
2.1 自然语言理解:GLUE基准的重大突破
BERT在GLUE(General Language Understanding Evaluation)基准测试中取得了历史性进展,综合得分提升至80.5%,相较此前最优结果实现7.7个百分点的绝对增长,展现了其在多任务环境下的强大泛化能力。
尤其在MultiNLI(多体裁自然语言推理)任务中,BERT达到了86.7%的准确率(提升4.6%),充分体现了其对复杂语义关系的理解能力。该任务要求模型判断前提句与假设句之间的逻辑关系(蕴含、矛盾或中立),必须综合考虑双句的完整语境,而BERT的双向建模机制恰好为此提供了强有力的支持。
深层机制解析: 多层自注意力结构使BERT能够逐层抽象语义信息,从前层的词汇匹配到高层的逻辑推理,形成递进式的理解路径。这种机制不仅提升了任务性能,也为后续模型解释性和可解释性研究提供了重要基础。
BERT 采用深度双向编码结构,通过在所有网络层中联合调节来自左右两侧的上下文信息,能够为文本中的每个词汇生成动态且高度依赖语境的表示形式,从而有效捕捉深层次的语义特征。
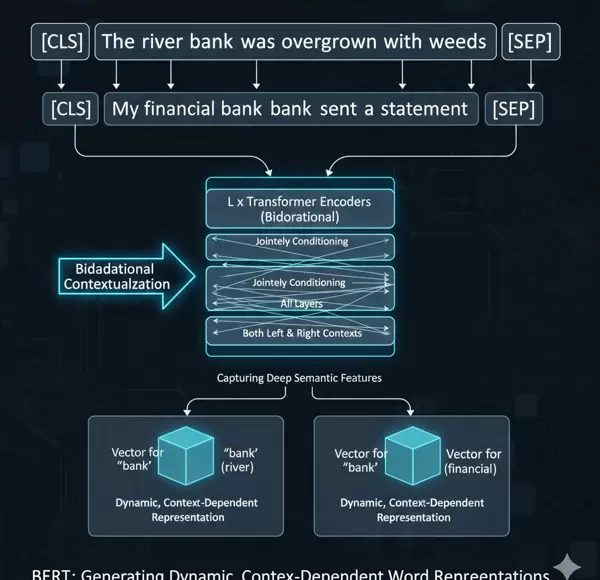
2.2 问答系统(QA):实现超越人类水平的性能
在机器阅读理解任务中,BERT 展现出了革命性的能力,尤其在 SQuAD(Stanford Question Answering Dataset)基准测试中表现突出。
基础性能表现:
BERT 在 SQuAD v1.1 上取得了 93.2 的 F1 分数,在更具挑战性的 SQuAD v2.0 上达到 83.1 的 F1 分数,相比此前模型实现了 5.1 分的绝对提升。值得注意的是,其在 SQuAD v1.1 上的表现已达到甚至超过人类平均水平。
模型改进方向:
针对原始 BERT 将问题与段落合并为单一输入序列可能导致“注意力分散”的问题,研究者提出了如 ForceReader 等优化模型。该类模型引入了注意力分离表示机制和多模式阅读策略,有效提升了对关键信息的关注度。
性能进一步提升:
ForceReader 在 SQuAD 1.1 上将 EM 和 F1 指标分别提高了 4.8% 和 2.9%,在 SQuAD 2.0 上更是实现了 6% 和 6.1% 的增长,使模型在问答任务上的表现更趋近于人类理解水平。
扩展应用场景:
此外,BERT 的多语言版本在跨语言问答任务中展现出强大潜力,并能有效识别和处理 SQuAD 2.0 中的不可回答问题,显著增强了实际应用中的鲁棒性与实用性。
2.3 文本分类:广泛的领域与语言适应能力
BERT 在情感分析及多领域文本分类任务中表现出卓越的泛化能力,尤其在复杂语境和多语言环境下优势显著。
实证性能数据:
在软件工程相关平台(如 GitHub、Jira、Stack Overflow)的文本分类任务中,基于 BERT 构建的集成模型与压缩模型在 F1 指标上比传统方法高出 6–12%。以 GitHub 数据集为例,其 F1 分数可达 0.92,显示出极高的准确率。
情感分析中的优势:
得益于其双向上下文建模能力,BERT 能够精准识别文本中微妙的情感变化,尤其在处理讽刺、反语等具有隐含意义的语言表达时表现优异。
部署优化策略:
为了平衡性能与计算成本,实践中常采用集成学习方法,融合 BERT、RoBERTa、ALBERT 等多种变体;同时,利用模型压缩技术(例如 DistilBERT),可在保留约 97% 语言理解能力的同时,将模型体积减少 40%,更适合工业级部署。
三、理论贡献、研究意义与未来展望
BERT 不仅是一个高性能的语言模型,更标志着自然语言处理(NLP)研究在哲学层面和方法论范式上的根本性变革。
3.1 推动预训练与迁移学习的新范式
核心理论贡献:
BERT 成功引领 NLP 领域从传统的任务特定模型设计转向“通用预训练 + 下游任务微调”的新架构范式。
研究意义:
这一转变使得研究人员可以充分利用海量无标注文本进行知识学习,大幅降低了对昂贵标注数据的依赖,显著提升了模型在不同任务间的迁移能力和泛化性能。
3.2 对 NLP 学术生态的深远影响
学术推动作用:
自发布以来,BERT 及其开源实现极大加速了学术进展。根据 Google Scholar 数据显示,已有超过 10,000 篇论文在其基础上展开研究与拓展。
衍生模型繁荣:
BERT 催生了一系列重要变体,涵盖多个研究方向:如 BioBERT 和 SciBERT 实现了领域适配,ERNIE 支持持续预训练,而 DistilBERT 则专注于模型轻量化,共同构建了一个丰富多样的模型生态系统。
3.3 跨领域应用与未来发展方向
BERT 的成功不仅局限于文本理解本身,还为跨学科应用和下一代模型研发提供了清晰路径。
跨领域迁移能力:
其学习到的语言表示已被成功迁移至信息检索(IR)、数学推理以及软件代码理解等非传统 NLP 任务中,验证了通用语义表征的强大迁移价值。
规模扩展趋势:
未来的研究将继续沿袭 BERT 的架构思想,向数十亿参数规模演进,并发展更高效的多语言表示体系。同时,通过 Switch Transformer 等新型稀疏架构降低计算开销,提升训练效率。
理论指引作用:
BERT 所采用的深度双向调节机制与掩码语言建模(MLM)目标函数,已成为后续大型语言模型(LLM)设计的核心技术基础,持续影响着现代 AI 语言系统的演进方向。
结论
BERT 凭借其创新的双向编码器结构,结合MLM 预训练策略与强大的深层上下文理解能力,确立了在自然语言处理领域的里程碑地位。它不仅在 GLUE、SQuAD 等权威基准上实现了超越人类的表现,更重要的是推动了整个 NLP 领域从“任务驱动工程”向“预训练+微调”这一通用化范式的根本转型。展望未来,BERT 的理论洞见与架构设计理念将持续作为新一代大语言模型发展的基石,引领自然语言智能迈向更高层次的理解与应用。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





