一、研究背景
尽管文本到图像(T2I)生成技术已取得显著进展,但在实际应用中仍存在明显局限:
- 难以精确控制图像的结构与空间布局
- 物体位置无法准确定位
- 属性易发生混淆,如颜色或纹理在不同对象间“串台”
- 无法对任意复杂形状进行精细操控
为应对上述问题,研究者提出了S2I范式——即通过“掩码+文本”联合驱动图像生成。然而,现有方法普遍存在两大挑战:
- 语义错位:文本描述与指定区域不匹配
- 形状变形:输入的mask在latent空间中被压缩失真

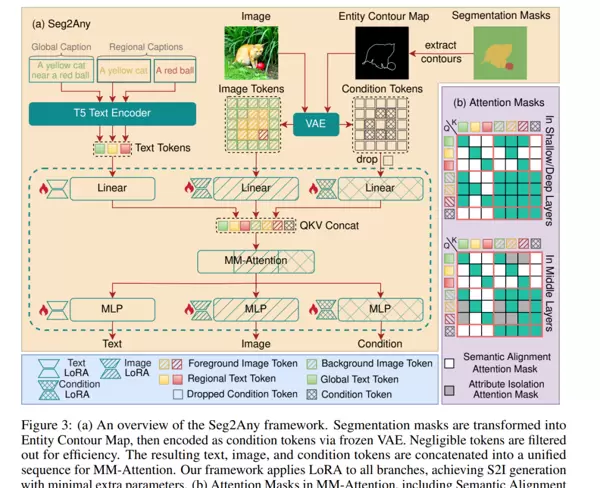
二、核心方法:Seg2Any
Seg2Any引入语义-形状解耦机制与属性隔离策略,实现以下目标:
准确理解语义内容,忠实还原mask形状,并杜绝属性干扰。
1. 语义与形状分离注入
Semantic Alignment Mask:确保每个文本描述仅作用于对应的图像区域,避免跨区域误响应。
Entity Contour Map:仅使用边缘轮廓作为形状引导信号,剔除潜在语义信息,纯粹保留几何结构特征。
2. 属性隔离注意力机制(Attribute Isolation Attention Mask)
针对常见的属性泄漏问题(如一个物体的颜色扩散至另一个),该模块限制每个实体只能关注属于自己的token。
未启用隔离时,颜色和纹理容易跨区域传播;而加入该机制后,生成结果显著更清晰、独立。
3. 轻量化可训练策略
基于先进的FLUX MM-DiT架构,采用LoRA微调方式,大幅降低计算开销。
同时,condition token具备自动过滤能力,有效减少显存占用,提升推理效率。
三、实验表现
评估涵盖多种设定:
- 开放式S2I任务(SACap-Eval)
- 封闭式S2I任务(COCO-Stuff / ADE20K)
- 与8种主流方法进行全面对比
SACap-Eval(开放集)性能对比
| 方法 |
MIoU↑ |
Spatial↑ |
Color↑ |
| FreestyleNet |
74.59 |
42.34 |
40.08 |
| PLACE |
84.30 |
79.05 |
49.40 |
| Seg2Any |
94.90 |
93.89 |
91.52 |
→ Seg2Any几乎逼近真实图像上限(96.03),表现卓越。
COCO-Stuff 与 ADE20K 结果
在标准数据集上,Seg2Any同时实现了:
- 最高的MIoU得分
- FID指标接近基模型训练水平,说明生成质量高且多样性良好
四、优势与局限性分析
主要优势
- 实现对形状与语义的双重精准控制
- 无需预定义类别标签,支持任意物体生成
- 属性隔离机制保障输出干净无串扰
- 兼容FLUX等前沿DiT架构,具备良好扩展性
- 支持涂鸦式(Scribble-style)灵活输入,交互友好
当前局限
- 当输入mask数量较多时,资源消耗随之上升
- 依赖视觉语言模型(VLM)自动生成caption,偶尔引入噪声
- 暂不支持视频或多视角3D场景生成
五、总结
Seg2Any将“分割掩码”真正转化为图像生成的语言工具——从宏观形状到微观属性,皆可实现精细化控制。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





