用ChatGPT生成的图片 我将一级方程式结果数据集存储在图数据库和SQL数据库中,然后使用各种大型语言模型(LLM)通过检索增强生成(RAG )方法回答数据相关问题。通过在两个系统中使用相同的数据集和问题,我评估了哪种数据库范式能提供更准确、更有洞察力的结果。
检索增强生成(RAG) 是一种人工智能框架,通过让大型语言模型(LLM)在生成答案前检索相关外部信息来增强它们。RAG不再仅依赖模型训练的内容,而是动态查询知识源(本文指SQL或图数据库),并将这些结果整合到响应中。关于RAG的介绍可以在这里找到。
SQL 数据库将数据组织成由行和列组成的表 。每一行代表一条记录,每列代表一个属性。表之间的关系通过键 和连接 定义,所有数据遵循固定模式 。SQL数据库非常适合结构化、事务性数据,这些数据需要一致性和精确性——例如财务、库存或患者记录。
图数据库将数据存储为节点 (实体)和边 (关系),并附加可选属性 。它们不再连接表,而是直接表示关系,从而实现快速跨越连接数据的访问。图数据库非常适合建模网络和关系——如社交图谱、知识图谱 或分子交互图谱——在这些关系中,连接与实体本身同样重要。
数据 我用来比较RAG性能的数据集包含了1950年至2024年的一级方程式成绩。它包含了车手和车队(车队)比赛的详细成绩,涵盖排位赛、冲刺赛、主赛,甚至圈速和进站时间。每场比赛结束后,车手和车队积分榜的排名也都包含在内。
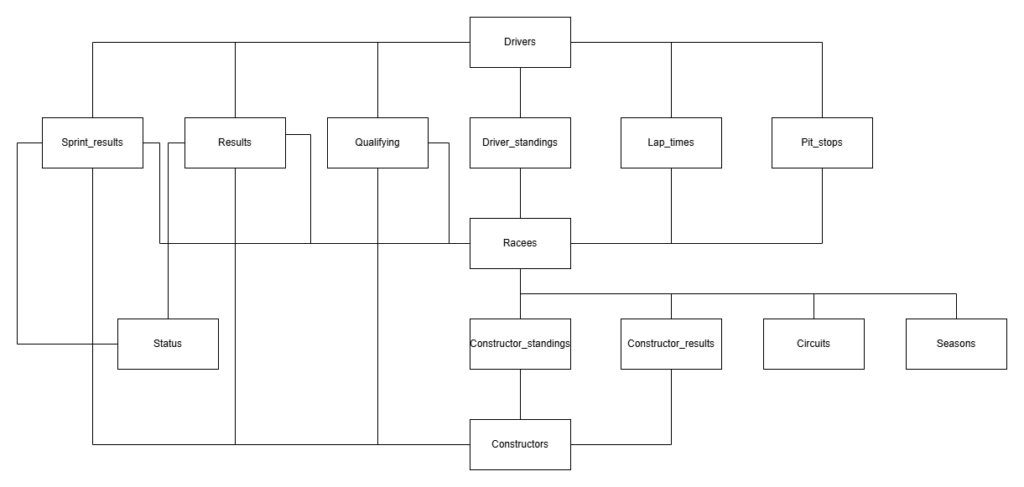
SQL 模式 该数据集已经以带有键的表格结构化,便于轻松搭建SQL数据库。数据库的结构图如下所示:
SQL 数据库设计 比赛是中央表格,链接了各种结果以及赛季和赛道等额外信息。成绩表还与车手和车队表相连,记录每场比赛的成绩。每场比赛结束后的积分榜会被存储在Driver_standings和Constructor_standings积分榜中。
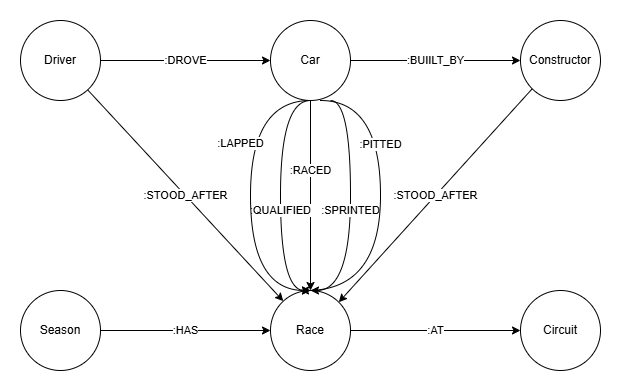
图结构 图数据库的模式如下所示:
图数据库设计 由于图数据库可以在节点和关系中存储信息,因此只需六个节点,而SQL数据库中有14个表。Car 节点是一个中间节点,用于建模车手在特定比赛中驾驶制造商的赛车。由于车手与制造商的搭档会随着时间变化,因此需要为每场比赛定义这种关系。比赛结果存储在 Car 和 Race 之间的关系中,例如 :RACED 之间。 而:STOOD_AFTER关系则包含每场比赛结束后的车手和车队积分榜。
查询数据库 我用 LangChain 为两种数据库类型构建了一个 RAG 链,基于用户问题生成查询,运行查询,并将查询结果转换为用户的答案。代码可以在这个仓库中找到。我定义了一个通用的系统提示符,可以用来生成任何SQL或图数据库的查询。唯一的数据特定信息是通过在提示中插入自动生成的数据库模式来实现的。系统提示可以在这里找到。
这里有一个示例,如何初始化模型链并提出问题:“哪位车手赢得了92年比利时大奖赛?”
from langchain_community.utilities import SQLDatabase"sqlite:///{DATABASE_PATH}" "gpt-5" )'SQL' , verbose=True)"What driver won the 92 Grand Prix in Belgium?" )回归如下:
{'write_query' : {'query' : "SELECT d.forename, d.surname }} 'execute_query' : {'result' : "[('Michael', 'Schumacher')]" }}'generate_answer' : {'answer' : 'Michael Schumacher' }}SQL 查询会加入结果、比赛和车手表格,选择1992年比利时大奖赛的比赛和第一名车手。LLM将1992年改为1992年,并将比赛名称从“比利时大奖赛”改为“比利时大奖赛”。它从数据库模式中推导出这些转换,数据库模式包含每个表的三行样本行。查询结果是“Michael Schumacher”,LLM返回了这个答案。
评估 现在我想回答的问题是,LLM在查询SQL还是图数据库方面更胜一筹。我定义了三个难度等级(简单、中等和困难),简单是可以通过查询单个表格或节点数据来回答的问题,中等是需要一两个表格或节点之间链接的问题,困难问题则需要更多链接或子查询。我为每个难度等级定义了五个问题。此外,我定义了五个无法用数据库数据回答的问题。
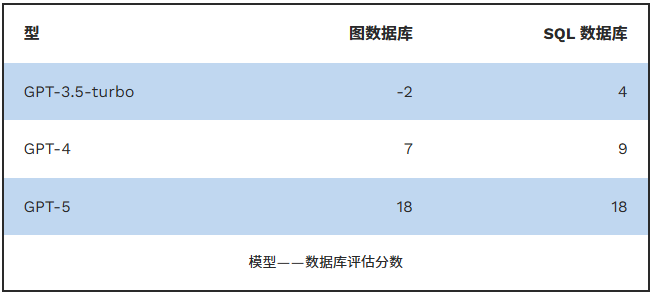
我用三个大型语言模型模型(GPT-5、GPT-4和GPT-3.5-turbo)回答每个问题,分析是否需要最先进的模型,还是更老且更便宜的模型也能产生令人满意的结果。如果模型给出正确答案,得1分;如果回答说无法回答问题,得0分;如果答错,得-1分。所有问题和答案都列在这里。以下是所有模型和数据库类型的评分:
令人惊讶的是,更高级的模型表现优于简单模型:GPT-3-turbo答错了大约一半的问题,GPT-4答错了2到3道但答不上6到7道,GPT-5除了一道外全部答对。简单的模型在使用SQL时表现似乎优于图数据库,而GPT-5在任一数据库下得分相同。
GPT-5 唯一用 SQL 数据库出错的问题是“哪位车手赢得的世界冠军最多?”。“刘易斯·汉密尔顿,7个世界冠军”的答案不正确,因为刘易斯·汉密尔顿和迈克尔·舒马赫赢得了7个世界冠军。生成的SQL查询汇总了按车手获得的冠军数量,按降序排序,只选择第一行,而第二排的车手拥有相同数量的冠军。
使用图数据库时,GPT-5唯一答错的问题是“2017年谁赢得了二级方程式锦标赛?”,回答为“刘易斯·汉密尔顿”(刘易斯·汉密尔顿当年赢得了一级方程式冠军,但未赢得二级方程式冠军)。这是个棘手的问题,因为数据库只包含一级方程式成绩,不包含二级方程式成绩。预期的回答是基于现有数据无法回答这个问题。然而,考虑到系统提示中没有包含关于数据集的具体信息,因此这个问题没有被正确回答是可以理解的。
有趣的是,使用SQL数据库,GPT-5给出了正确答案“Charles Leclerc”。生成的SQL查询仅搜索驱动程序表中“Charles Leclerc”这个名字。这里,LLM必须认识到数据库中不包含Formula 2结果,并根据其常识回答了这个问题。虽然这导致了正确答案,但当LLM未利用提供的数据来回答问题时,可能会有危险。减少这种风险的一种方法是在系统提示中明确说明数据库必须是唯一回答问题的来源。
结论 此次使用Formula 1结果数据集进行RAG性能比较显示,最新的大型语言模型表现异常出色,无需额外提示工程即可生成高度准确且具上下文感知的答案。虽然简单模型表现较差,但像GPT-5这样的新模型能以近乎完美的精度处理复杂查询。重要的是,图和SQL数据库方法在性能上没有显著差别——用户可以简单地选择最适合其数据结构的数据库范式。
这里使用的数据集仅作为示例;使用其他数据集时,尤其是那些需要专业领域知识或访问非公开数据源的数据集,结果可能会有所不同。总体而言,这些发现凸显了检索增强大型语言模型在结构化数据与自然语言推理整合方面的进步。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏