Wintc乱码问题的成因分析
在Windows系统下使用某些传统的C语言开发工具(如经典的Turbo C)时,常会遇到Wintc显示乱码的情况。这种现象主要源于字符编码不一致所引发的显示异常。早期的开发环境普遍采用ASCII或特定OEM字符集(例如代码页437),而现代中文Windows系统则默认使用GBK或UTF-8等更广泛的编码标准。
当源代码文件以UTF-8格式保存,但在仅支持GBK或ASCII的环境中被读取时,其中的中文字符便无法正确解析,从而出现乱码。此外,编译器本身的兼容性缺陷或操作系统区域设置不当,也可能加剧这一问题。这不仅影响代码的可读性和调试效率,还可能隐藏潜在的文件存储与编译错误。
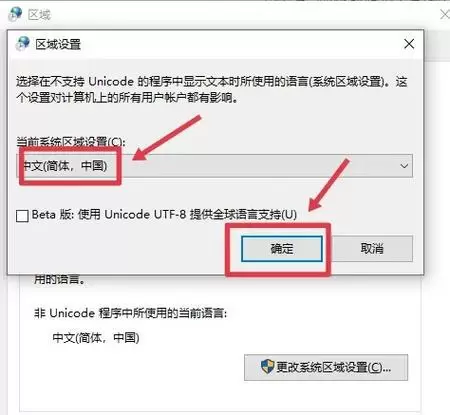
解决Wintc乱码的有效方法
应对该问题的关键在于实现编码统一。最简便的方式是通过记事本或其他文本编辑器将源码文件另存为“ANSI”编码格式,该格式在中文系统中通常对应GBK编码,能够被旧版开发环境正常识别和显示。
另一种可行方案是调整开发工具的配置参数,例如在模拟运行环境中更换为支持中文显示的字体,并核对代码页设置是否匹配当前系统环境。若条件允许,推荐迁移到支持Unicode的现代化集成开发环境(如Code::Blocks、Dev-C++等),从根本上避免编码冲突带来的困扰,提升开发体验与协作效率。
预防Wintc乱码的操作建议
为了避免反复出现乱码问题,应从源头建立良好的编码规范。建议在项目初始化阶段即明确源代码文件的统一编码格式(如GB2312或GBK),并在团队协作中严格执行,确保所有成员使用相同的编码标准进行编辑与保存。
同时,应尽量避免在不同操作系统平台或编码处理机制差异较大的编辑器之间频繁切换修改同一份代码文件,以防引入不可见的编码转换问题。对于必须依赖老旧开发环境的教学或历史项目维护场景,推荐在虚拟机中部署一个干净的旧版操作系统环境,以此隔离现代系统带来的编码干扰,保障开发过程的稳定性。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





