经管之家App
让优质教育人人可得
立即打开


本文将继续深入探讨 SQLite 的开发实践,基于前期学习内容,进一步建立一套初步但实用的开发规范体系。对于尚未熟悉 SQLite 的读者,建议先回顾此前发布的相关文章,以便更好地理解本篇内容。
在 SQLite 中,数据库支持 schema 概念,主要包含两个默认的 schema:
因此,所有表必须归属于这两个 schema 之一。
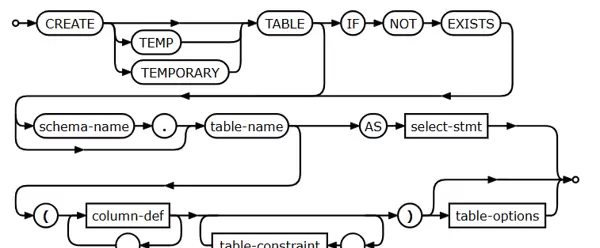
CREATE TABLE main.user ...鉴于 SQLite 自身的轻量级与嵌入式特性,在初始化阶段应明确设定数据库的行为标识,例如:
这些配置有助于在多环境部署中保持一致性与可识别性。
PRAGMA journal_mode = WAL;
PRAGMA synchronous = NORMAL; ? ? -- 或 FULL(强一致)
PRAGMA page_size = 4096;?
PRAGMA foreign_keys = OFF;
PRAGMA application_id = 0x0011AABB; -- 自定义
PRAGMA user_version = 1;数据库文件的命名应在外部数据文件中清晰体现其所属模块或功能,并统一采用 .db 作为后缀,提升可维护性与定位效率。
CREATE INDEX idx_order_user_status
ON order(user_id, status);CREATE TABLE main.order (
? ? id INTEGER PRIMARY KEY, ? ? ? ? ?-- 自增ID
? ? user_id INTEGER NOT NULL, ? ? ? ?-- 用户ID
? ? amount INTEGER NOT NULL, ? ? ? ? -- 金额(单位:分)
? ? status INTEGER NOT NULL DEFAULT 0,
? ? created_at INTEGER NOT NULL, ? ? -- UNIX时间戳
? ? updated_at INTEGER NOT NULL
) STRICT;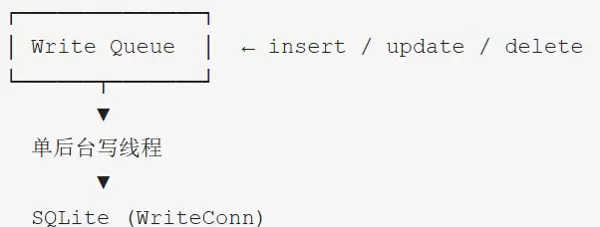
以上所列规范将根据实际项目应用情况持续迭代优化。后续如有更新,将在技术社区同步发布。
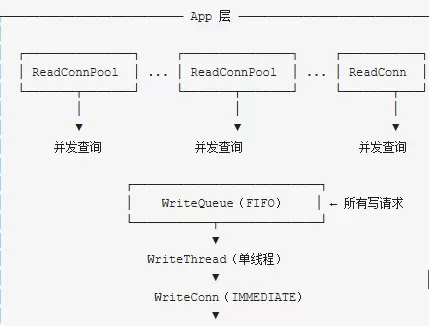
关于 SQLite 在异常断电或强制关机情况下的数据安全性问题:SQLite3 具备良好的崩溃恢复机制,通过 WAL(Write-Ahead Logging)或回滚日志保障事务的原子性与持久性,在大多数情况下可有效防止数据丢失。
值得一提的是,尽管 PostgreSQL 在功能上更为强大,但在移动端和嵌入式领域,SQLite 凭借其零配置、低资源消耗、高可靠性的特点,已成为全球安装量最大的数据库引擎。这一趋势也反映出轻量化与场景适配的重要性。
近期对 SQLite 的研究引发了广泛关注,前一篇文章获得了远超预期的反响,这也说明开发者社区对其底层机制的关注正在升温。
最后补充一些行业动态背景:
面对阿里云产品选型时的纠结,很多人在 RDS 和 PolarDB 之间难以抉择。本文旨在清晰梳理两者差异,帮助用户根据实际业务场景做出合理选择。
SQLite3 凭借轻量、嵌入式优势,在移动端广泛应用,甚至超越了功能更强大的 PostgreSQL。尽管如此,PostgreSQL 在移动开发中依然具备一定潜力,特别是在需要复杂查询和数据一致性的场景下表现不俗。
关于 SQLite 的研究文章一经发布便引发广泛关注,阅读量迅速攀升,成为近期热点内容之一。事实证明,SQLite 能够取得全球最高装机量并非偶然——其极简架构与零配置特性,使其在资源受限环境中具有无可替代的优势。
针对群友提出的常见问题,我们再次整理了 PostgreSQL 中高频使用的扩展模块(Extensions),包括但不限于 pg_stat_statements、hstore、jsonb、postgis 等,这些工具显著增强了数据库的功能边界。
2025 年 PostgreSQL 杭州大会即将到来,回望过去,已有七年时光沉浸于这一生态之中,感慨良多。社区的成长、技术的演进,都见证了国产数据库环境的逐步成熟。
谈及国产数据库生态建设,业内服务商直言:“有些宣传言过其实。” 实际落地过程中仍存在诸多挑战,从兼容性到工具链完善度,距离真正意义上的“自主可控”还有差距。
有企业提问:为何外部客户数据库选型最终落到了 OceanBase?这背后反映出民营企业对高可用、强一致性以及成本控制的综合考量。OceanBase 在金融级应用场景中的稳定性得到了充分验证。
OceanBase 推出的共享存储方案被视为关键一步,标志着其在架构灵活性上的重大突破。此外,OB Cloud 快速交付能力也大大提升了部署效率,尤其适合希望快速上线 MySQL 兼容服务的企业。
对于“一顿海鲜引发”的系列故事,已更新至第三部分。从 DBA 与运维工具的矛盾冲突,到如何通过工具实现一分钟精准定位数据库问题,过程充满戏剧性,最终参与者还获得了京东卡等实物奖励。
DBA 角色正在经历深刻转变——从传统“修电脑的”技术人员,逐步转型为数据治理的核心推动者。通过建立标准化流程与智能监控体系,维护自身职业价值的同时,也为组织创造更大效益。
Oracle 并非所有数据库项目都能成功。回顾历史,也曾推出过失败的产品线。今天我们不妨坦诚讨论那些未能持续发展的案例,从中汲取经验教训。
某次国庆节期间,PostgreSQL 实例突发停机故障,紧急协助处理后恢复正常。为鼓励技术分享,特设红包激励机制,感谢参与排查的技术同仁。
北美地区关于 AI 是否将取代程序员的讨论持续发酵,境外开发者社区反应激烈。有人担忧岗位被替代,也有人认为 AI 将成为开发者的强力辅助。
MySQL 8.0 至今仍存在一些源自 5.7 版本的老大难问题,例如优化器行为不稳定、复制延迟等。这些问题长期未解,引发广泛吐槽,改进之路依然漫长。
体育专业出身却误打误撞进入 DBA 行业的人不在少数,面对高强度的技术要求,不少人开始反思职业方向,考虑是否应转行发展。
一篇深入分析 MySQL 用户版本升级路径的文章指出,从 8.0.28 到 8.4 版本间,核心功能如并行查询、索引优化、安全机制等方面均有显著提升,值得重点关注。
云上 DBA 更像“诸葛亮”,侧重策略规划与自动化管理;而传统云下 DBA 则如同“关云长”,强调现场响应与手动操作。这种角色演变源于四大变化:平台化、智能化、服务化与标准化。
有外国专家质疑 PostgreSQL 18 的 AI 集成能力不足,但实际情况是,PG 正通过插件生态与向量计算支持逐步增强 AI 相关功能,未来可期。
MongoDB 已开始承接客户系统的 AI 改造项目,这一动向令人惊讶。曾经以文档存储见长的数据库如今积极拥抱 AI 应用,显示出整个行业格局正在重塑。
一篇翻译自外文的技术文章详细解析了 PostgreSQL 日志管理中的常见痛点,并提供了系统化的诊断思路与解决方案,涵盖日志级别设置、性能影响评估及审计合规建议。
DBA 与 AI 的博弈每天都在上演。在这场较量中,究竟是谁占据了主导地位?就像麦当劳与星巴克的区别——一个追求效率,一个注重体验,二者各有生存之道。
科技改变生活,阿里云 DAS(Database Autonomy Service)正是典型代表。借助 AI 技术,DAS 实现了自动巡检、异常检测、SQL 优化等功能,极大减轻了人工负担。
Supabase 作为一个新兴开源平台,可能尚未被企业级 DBA 广泛认知。但它并不简单,融合了 Postgres 核心、实时 API、身份认证等多种能力,适用于现代应用快速开发。
Oracle 最近推出了原生支持其数据库的 MCP 服务器,旨在帮助企业构建智能代理应用。此举进一步强化了 Oracle 在企业智能化转型中的技术支撑地位。
PolarDB MySQL 的 SQL 优化指南作为系列第五篇,聚焦于执行计划解读、索引使用建议及常见反模式识别,助力开发者写出高效 SQL。
Redis 大 key 问题是开发常忽略却严重影响性能的隐患。作为 DBA,可通过扫描工具识别大 key、拆分结构、引入缓存层级等方式进行有效治理。
小厂和私有云在云基座技术普及背景下面临挑战。虽然大厂拥有资源优势,但小规模团队可通过轻量化架构、开源方案组合找到适合自己的出路。
OceanBase 在处理“一坨”式复杂系统时展现出独特优势,架构师推荐其用于整合老旧系统,原因在于其分布式架构、高兼容性和弹性扩展能力。
经过测试,OceanBase 的 Hybrid Search 功能表现优异,成为替代 MySQL 的可行选项之一,尤其适合读写混合且需全文检索的场景。
单机版 OceanBase 支持大批量快速部署,已在多个测试环境中验证可行性,适用于 DevOps 流程或测试集群搭建。
“OceanBase 6大学习法”系列视频学习总结已覆盖前六章内容,涵盖从安装部署、引擎原理、表设计、索引优化到社区版应用案例等多个维度。其中第四章讲解数据库安装流程,第三章剖析存储引擎机制,第二章介绍 OB 架构入门,第一章则引导初学者快速上手。
阅读《OceanBase 社区版在泛互场景的应用案例研究》白皮书后,作者感慨万千。即便写作总量已达三千七百五十万字,仍能从这份两千字的文档中学到新知。
第四届 OceanBase 数据库大赛成功举办,“没有谁是垮掉的一代”成为主题口号,展现了年轻技术人才的拼搏精神与创新活力。
IF-Club 活动持续进行中,用户提交反馈意见即可参与抽奖赢取礼品,AustinDatabases 社区成员数已突破 10000 人。
关于 MySQL 物化视图功能的讨论升温,目前已有厂商在云上 MySQL 实现类似特性。展望 2025 年,该功能或将逐步普及。
HTAP 概念正被重新定义,不再局限于“同时支持事务与分析”,而是强调资源隔离、负载感知与动态调度能力,这与传统理解有所不同。
Oracle 26i 新增功能引发关注,若云厂商加以利用,可能催生出极为复杂的“千年老妖”式数据库架构,需警惕过度设计带来的维护难题。
参加某国产数据库闭门会议后,笔者记录下所见所感。这类“小黑屋”式的深度交流,往往能揭示产品真实状态与发展方向。
最后,OceanBase 祝福活动如期举行,通过互动形式为用户送上节日祝福与幸运好礼。
跟随教程学习 OceanBase 4.0 版本,重点研读白皮书内容,了解其在分布式优化方面的改进点,包括全局时间戳、多副本一致性协议升级等,这些优化显著提升了系统整体性能。
在当前全球化背景下,SaaS类企业在选择数据库时需综合评估多个维度。技术架构的先进性决定了系统的可扩展性和稳定性;成本控制不仅涉及授权费用,还包括运维和人力投入;合规要求如GDPR或本地数据主权法规日益严格;而地缘政治因素则可能影响跨国数据流动和技术供应链安全。因此,数据库选型已不再仅仅是技术决策,更是战略层面的权衡。
OceanBase从0.5版本演进至4.0,经历了显著的架构革新。早期版本以单机部署为主,而4.0则全面拥抱分布式架构,强化了多租户隔离能力,并提升了资源调度效率。其核心优化点集中在高可用机制、弹性伸缩能力以及对MySQL协议的深度兼容上,使得用户能够像使用传统数据库一样无缝迁移业务系统。
与此同时,旧有数据库理念正在成为认知障碍。例如“强一致性必须牺牲性能”这类观点,在OceanBase通过Paxos协议实现高性能强一致后已被打破。更新知识体系,摒弃过时概念,是掌握新一代分布式数据库的关键前提。
为了降低迁移门槛,OceanBase支持创建MySQL兼容模式的租户。在此模式下,开发人员无需修改应用代码即可连接并执行标准SQL语句。该设计极大简化了从MySQL向OceanBase的过渡流程,同时保留了分布式架构带来的高可用与水平扩展优势。
标题戏仿流行文化,实则反映OceanBase在国产化软硬件环境中的深度优化成果。“重如尘埃”寓意微小改动带来巨大性能提升。通过对底层指令集和内存访问模式的调优,OceanBase在国产CPU平台上实现了接近国际主流芯片的处理效率,助力信创生态落地。
本系列文章以“大型连续剧”形式记录了MongoDB升级过程中的真实挑战。第一阶段探讨是否必须升级的问题,分析升级收益与风险;第二阶段聚焦责任归属,澄清常见误解;第三阶段介绍自动化校验脚本的设计思路与关键注意事项;第四阶段总结与开发团队及架构组的协同经验,完成收尾工作。
所谓“多模”,指MongoDB支持文档、图、时序等多种数据模型共存于同一平台。这一特性打破了传统单一数据模型的局限。文章用通俗语言解释嵌套结构与引用方式的区别,剖析奇葩但高效的更新方法,并结合统计类数据更新场景,展示如何进行合理的建模设计。
关于分片策略,“4分什么分”一文指出盲目分片的危害,强调应根据查询模式和数据增长趋势科学规划。此外,TTL(生存时间)功能常被误用,导致数据提前丢失或资源浪费,呼吁使用者提升专业素养,合理配置。
在当年MongoDB大会上,数据建模成为焦点话题。官方提倡“模式先行”的设计理念,反对无约束的自由写入。通过实际案例说明良好模式能显著提升查询性能、降低存储开销。同时回顾过往争议内容,如双机热备方案存在数据丢失隐患,需谨慎采用。
另有一篇关于清理表碎片的文章警示:网上流传的“妙招”可能导致实例宕机,提醒技术人员勿轻信非官方操作指南。相关赠书活动已结束。
PolarDB已推出一系列公开课程,涵盖云原生架构、弹性扩容、备份恢复、归档机制、代理服务、列式索引加速等核心技术。第一节从用户视角切入,解析PolarDB的核心价值;第二节深入云原生特性;第三节揭示MySQL与IMCI引擎融合带来的性能飞跃;第四节讲解PG版实时物化视图与行列混合处理能力;第五至七节分别探讨代理重要性、极速备份原理及归档创新玩法;第八节作为结课章,展望数据库弹性未来。
另有非厂商主导的共创课程,由7位学员获评“学习之星”,体现社区共建力量。课程强调:复杂SQL在PolarDB for PG中借助列式索引得以高效运行,压缩率达60%的同时反而提升执行速度,挑战传统认知。
相比自建MySQL,PolarDB具备更高稳定性与性能表现。例如加索引操作卡顿问题,可通过调整参数与架构优化解决;添加字段失败的情况也被分析,明确责任边界——某些问题并非PolarDB本身所致。
在PostgreSQL领域,PolarDB实现了高性能主从架构下的强一致读写分离,这是多数开源方案难以达成的能力。其IMCI列存引擎使分区表不再是“脑子有水”的选择,而是应对大数据量场景的有效手段。
不同版本间存在隐秘差异,有的表现温和如绵羊,有的则是性能怪兽。这些细节通常不对外公开,但直接影响选型判断。
新版本未必等于更好,需结合实际负载测试验证。针对Freeze相关问题,专门撰写回应帖进行详解。内存动态扩展是PG的一大痛点,现已有可行方案实现运行时调整,提升灵活性。
大版本升级提供三种路径:接锅(承接遗留问题)、背锅(主动修复)、不甩锅(清晰界定责任),倡导以客户为中心的产品思维。
在厂商主导的技术环境中,DBA面临生存压力。唯有保持独立判断、积累实战经验,才能成为“老油条”式的资深专家。MySQL与PostgreSQL并非对立,二者可以协同发展,共同支撑多元化业务需求。
最后,关于“云上自建MySQL是小垃圾”的论断,意在批判低效运维模式,而非否定MySQL本身。真正的竞争力来自于架构设计与工程能力,而非单纯依赖某款数据库产品。
在 PostgreSQL 中,shared_buffers 参数用于控制数据库共享内存池的大小,传统上修改该参数需要重启实例。然而,在某些特定配置和版本支持下,可以通过动态调整机制实现不中断服务的情况下变更此值。其背后依赖的是操作系统对内存映射的支持以及 PostgreSQL 对运行时参数的灵活管理能力。
尽管并非所有环境下都支持完全热更新,但结合外部工具或使用如 Huge Pages 动态绑定等技术,可以在一定程度上减少停机需求,提升系统可用性。

有同学提到“PG Freeze Boom”,这其实是指由于事务 ID 回卷(wraparound)引发的数据冻结问题。当数据库长时间未执行 vacuum 操作时,旧元组无法被及时清理,导致系统强制进入保护模式甚至阻塞写入。
本文通过专帖形式详细剖析了该问题的发生机制、预警信号及应对策略,帮助用户理解如何合理规划自动 vacuum 策略以避免生产事故。
在一个服务器上部署多个 PostgreSQL 实例,并通过同一个公网 IP 不同端口对外提供服务,是常见的资源复用方式。这种架构下,客户端可通过指定不同端口号连接对应实例,实现逻辑隔离。
关键在于正确配置 postgresql.conf 中的 listen_addresses 与 port 参数,同时确保防火墙规则允许相应端口通信。
相较于一些仅支持简单 OLTP 或有限分析功能的“小趴菜”数据库,PostgreSQL 凭借其原生支持 JSON、GIS、全文检索、物化视图、分区表等功能,展现出强大的混合负载处理能力(Hybrid Transactional/Analytical Processing, HTAP)。
无论是高并发交易系统还是实时报表场景,PG 均能胜任,体现了其作为企业级数据库的核心竞争力。
在参与某次 PG 培训过程中,发现部分用户盲目追求新版,认为新版必然带来性能提升。为此设计了一组对比测试:在相同硬件和数据集下分别运行 PostgreSQL 13 与 15 版本。
结果表明,某些查询在老版本中表现更优,原因涉及执行计划变化、统计信息采样差异等因素。结论是:升级需谨慎评估,不能迷信版本号。
本篇为综合性技术随笔,涵盖索引选择不当导致全表扫描、函数索引误用、隐式类型转换影响执行计划等多个常见痛点。
文章强调 DBA 与开发者应协同工作,遵循 SQL 编写规范,利用 EXPLAIN 分析执行路径,从根本上提升系统整体效率。
随着云原生发展,PostgreSQL 正迈向 Serverless 架构。Neon 和 Amazon Aurora 提供了计算与存储分离的设计,支持即时扩展、按使用量计费的新经济模式。
这类平台不仅降低了运维复杂度,还显著提升了资源利用率,尤其适合流量波动大的应用场景。
除了常见的 work_mem、shared_buffers 外,PostgreSQL 还有许多冷门但关键时刻起决定作用的参数,例如 max_standby_streaming_delay、commit_siblings、bgwriter_delay 等。
这些参数往往隐藏在官方文档深处,但在特定业务负载下可能成为性能瓶颈的关键突破口,值得深入研究。
逻辑复制槽用于保障流复制过程中 WAL 日志不会过早被清理,确保下游消费者能够稳定接收变更数据。
它不仅支持跨版本复制,还可用于构建 CDC(Change Data Capture)系统,广泛应用于数据同步、审计、数仓接入等场景。
针对新手 DBA 和运维人员,整理了一系列实用的监控脚本,包括:当前活跃会话查看、锁等待检测、慢查询识别、索引命中率统计等。
这些脚本基于 pg_stat_activity、pg_locks、pg_stat_user_indexes 等系统视图编写,可快速集成至日常巡检流程。
借助 synchronous_commit、quorum commit 等机制,PostgreSQL 可实现真正意义上的强一致性读写分离架构。
相比之下,许多其他数据库因缺乏可靠的复制确认机制,难以保证数据零丢失,因此在关键业务系统中仍难替代 PG 的地位。
一次线上操作中,因创建大型索引占用过多 work_mem 并触发 OOM,最终导致数据库进程被系统杀死。
这说明即使官方文档提供了建议值,实际生产环境仍需根据负载特征进行调优,不能照搬默认配置。
近年来,一批基于 PostgreSQL 改造的商业化数据库产品陆续出现,如 Citus、TimescaleDB、Greenplum 等。
它们在分布式、时序处理等方面进行了深度优化,正在逐步侵蚀传统数据库市场份额,标志着 PG 生态已进入爆发期。
某复杂联表查询原本耗时超过 30 秒,经过执行计划分析后发现存在嵌套循环与缺失索引问题。
通过重写 SQL、建立复合索引并调整 join_order,最终将响应时间压缩至 200ms 以内,性能提升达 140 倍。
在本次大会上,多位专家分享了真实运维中的挑战,包括长事务处理、备份恢复策略、监控体系建设等。
特别指出,很多问题并非技术本身缺陷,而是团队协作、流程规范不到位所致,呼吁加强 DevOps 文化建设。
虽然 PG 支持 JSON、XML、数组、HStore 等多种数据类型,但这并不意味着应该滥用。
将大量非结构化数据直接塞入数据库会导致维护困难、性能下降。合理的做法是明确边界,结构化数据走关系模型,非结构化内容交由专门系统管理。
看似简单的用户权限迁移,实则涉及角色继承、schema ownership、default privileges 等多个层面。
若处理不当,可能导致对象访问失败或安全漏洞。建议使用 pg_dump -r 导出角色信息,并结合脚本批量校验权限一致性。
面对开发人员随意执行危险 SQL、绕过审批上线等问题,DBA 不应沉默。
应建立完善的审计机制(如启用 log_statement='ddl'),配合定期审查日志,发现问题及时通报并推动整改。
某企业在迁移到 Oracle 后遭遇 licensing 成本飙升和技术锁定困境,最终决定回归开源路线,选择 PostgreSQL 作为核心数据库。
这一趋势在全球范围内愈发明显,越来越多组织意识到自主可控的重要性,推动 PG 快速普及。
创建索引过程会消耗大量内存资源,特别是在大表上执行时。
若未合理设置 maintenance_work_mem 或未分批处理,极易引发内存溢出。因此,任何 DDL 操作前都应进行风险评估和资源预估。
看似基础的 CREATE DATABASE 操作,其实包含 encoding、locale、tablespace、connection limit 等多项配置选项。
忽略这些细节可能导致后续字符集冲突、性能瓶颈等问题,提醒初学者重视基础知识掌握。
近期发现多起针对 PostgreSQL 的暴力破解行为,主要集中在默认端口 5432 上。
应对措施包括:更改默认端口、限制 IP 访问、启用 SSL 加密、设置登录失败锁定策略。文中附带脚本可用于分析 pg_log 中的异常连接尝试。
为提升远程运维效率,整理了六款轻量级脚本,涵盖:自动健康检查、空间预警、主从状态监测、WAL 生成速率统计、vacuum 进度跟踪、连接数趋势分析。
这些脚本均可定时运行并通过邮件或消息接口告警,极大减轻人工负担。
本次大会聚集了全国各地 PostgreSQL 技术爱好者,议题覆盖内核开发、性能优化、云原生部署等多个方向。
现场交流热烈,展现了中文社区日益活跃的技术氛围和发展潜力。
当怀疑 PostgreSQL 存在内存泄露时,可借助 Valgrind、GDB、perf 等工具进行诊断。
重点观察 backend 进程的内存增长趋势,结合源码定位异常分配点。此外,定期升级到最新小版本也是预防已知问题的有效手段。
传统 GROUP BY 查询常被视为必须遍历全表的操作,但在引入索引覆盖(covering index)和物化视图后,情况已发生变化。
通过合理设计索引结构,使聚合字段和筛选条件均被包含,可实现仅扫描索引完成分组,大幅缩短响应时间。
汇总作者所有历史发布的技术文章,涵盖架构设计、性能调优、故障排查、复制机制等多个维度。
适合希望系统学习 PostgreSQL 的读者按主题查阅。
许多性能问题根源不在数据库本身,而在开发人员编写的低效 SQL。
如 SELECT *、缺少 WHERE 条件、滥用子查询等常见错误频繁出现。应加强 SQL 编码培训,建立代码评审机制,从源头杜绝劣质语句上线。
某次迁移中因未统一客户端与服务器端编码设置,导致中文排序结果混乱。
此类问题在 MySQL 中因默认兼容性处理较好而较少暴露,但在 PG 中要求更高一致性,反而凸显出配置严谨性的优势。
在大会上,开发者介绍了 Patroni 即将推出的 3.0 版本,重点改进包括:增强 Kubernetes 集成、支持多数据中心自动切换、优化 DCS(Distributed Configuration Store)容错机制。
这些更新将进一步提升高可用集群的稳定性与灵活性。
为解决 vacuum 长期运行影响性能的问题,团队自主研发了一套 vacuum 监控与调度平台。
该平台可根据表膨胀程度智能安排清理时机,避免高峰期操作,有效保障业务连续性。
面对开发人员滥用长连接、不关闭游标、频繁重建索引等行为,DBA 必须采取行动。
除加强沟通外,还需实施技术约束,如设置 idle_in_transaction_session_timeout,并定期运行脚本终止闲置会话。
因未设置 proper log rotation 策略,某生产环境日志文件在数周内增长至数百 GB,最终耗尽磁盘空间。
事后复盘发现,log_filename、log_rotation_age、log_truncate_on_rotation 等参数均未正确配置,属于典型管理疏忽。
通过重构核心模块的索引结构与查询逻辑,成功将某关键报表生成时间从小时级降至分钟级。
不仅赢得业务部门认可,也成为年度绩效亮点,足见数据库优化的巨大价值。
对比两个主流小版本之间的主要变更,包括优化器改进、JSON 函数增强、权限系统调整等内容,帮助用户判断是否值得升级。
通过精细化控制事务粒度、优化 binlog 写入机制、采用并行复制等手段,显著改善了大规模数据写入场景下的复制延迟问题。
展示如何利用条件下推减少中间结果集体积,结合索引有序性避免额外排序,从而提升复杂查询性能。
回顾 MySQL 自诞生以来的发展历程,从一个小众项目成长为全球最受欢迎的开源数据库之一,承载了几代程序员的情感与记忆。
聚焦两类高频问题:一是 NULL 值处理不当导致索引失效;二是 JOIN 顺序不合理引起性能退化。提供具体改写建议与验证方法。
通过真实业务场景还原优化全过程,辅以可视化思维导图梳理分析思路,帮助读者建立系统化的调优框架。
一场社区争论促使人们重新审视主键设计原则,最终总结出自增主键、UUID、雪花算法等多种方案的适用场景与权衡要点。
讨论 MEMORY 引擎的局限性,引导开发者转向 InnoDB + 缓存组合方案,提倡以架构思维而非临时技巧解决问题。
当 wait_timeout 或 interactive_timeout 触发断开时,未提交事务可能仅部分回滚,造成数据不一致。
建议应用层捕获连接中断并显式处理事务状态,避免遗留脏数据。
某公司因拒绝升级至 8.0,在遭遇安全漏洞修补失败后系统崩溃。
提醒用户关注官方生命周期政策,及时规划版本迭代路线。
针对“MySQL 查询慢”的普遍误解,设计对照实验比较 PG 与 MySQL 在相同场景下的表现。
结果显示,在合理建模和索引支持下,MySQL 同样可以高效运行复杂查询。
调侃业界对 MySQL 名称使用的混乱现象,同时也反映出其深入人心的品牌影响力。
介绍某第三方机构发布的 MySQL 增强插件包,集成了连接池优化、审计增强、自动索引推荐等功能,助力企业延长现有系统寿命。
整合作者关于 MySQL 的全部技术输出,涵盖架构设计、性能调优、故障排查等领域,便于集中查阅。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




