经管之家App
让优质教育人人可得
立即打开


论文基本信息:
原题:POLARIS: Is Multi-Agentic Reasoning the Next Wave in Engineering Self-Adaptive Systems?
作者及单位:Divyansh Pandey、Vyakhya Gupta、Prakhar Singhal、Karthik Vaidhyanathan(印度国际信息技术学院海德拉巴分校,IIIT-Hyderabad)
引用格式(GB/T 7714):Pandey D, Gupta V, Singhal P, et al. POLARIS: Is Multi-Agentic Reasoning the Next Wave in Engineering Self-Adaptive Systems[EB/OL]. arXiv:2512.04702v1 [cs.SE], 2025-12-04.
代码开源地址:https://github.com/prakhar479/POLARIS
你是否经历过这样的场景?手机应用在高峰时段突然卡顿,因服务器未能及时扩容;AI图像生成工具响应时快时慢,源于模型切换频繁且缺乏协调。这些正是自适应系统试图解决的核心问题——如何让系统在动态环境中自主调整,维持高效稳定运行。
然而,当前的自适应系统正处于持续升级阶段:
传统方法存在显著瓶颈:① 缺乏前瞻能力,只能事后处理;② 面对AI系统的非确定性表现无能为力;③ 调整策略固定,不具备演化能力;④ 泛化性差,更换应用场景需重新设计逻辑。例如,某电商平台的传统扩容机制依据固定阈值操作,在促销期间常出现资源浪费或服务延迟,且无法从过往活动中积累经验。
正是上述局限推动了POLARIS的提出——旨在将自适应系统由“被动响应”转向“主动推理”与“自我进化”。
POLARIS 是一个面向 Self-Adaptation 3.0 的多智能体推理驱动型自适应框架,采用三层架构设计:低延迟 Adapter 层、透明 Reasoning 层 和 元学习 Meta 层。通过多智能体协作、工具增强推理与元学习机制,突破传统 reactive 模式的限制,实现基于数据的预测性主动适配。
在两个差异显著的测试系统 SWIM 与 SWITCH 中均取得优异表现:SWIM 上总效用达到 5445.48,优于现有基线;SWITCH 系统中,响应时间中位数下降 27.3%,CPU 使用率降低 14.9%,破坏性切换减少 87.1%。实验结果验证了其良好的跨场景泛化能力和运行效率,标志着自适应系统正从“环境适应”迈向“推理驱动+自我演进”的新阶段。
不同于传统的单一控制循环结构,POLARIS 将整个自适应流程划分为三个层级,分别由专用智能体执行特定功能:
这种“作战小组式”的分工机制,既保障了即时反应能力,又支持深度推理和策略迭代,实现了速度与智能的平衡。
推理层(Reasoner)摒弃复杂的数学建模方式,转而采用自然语言进行逻辑推导,并融合以下关键组件:
该机制有效缓解了大模型在推理过程中常见的“幻觉”现象和上下文遗忘问题,使决策过程清晰可追溯,增强了系统的可解释性与可靠性。
Meta-Learner 层会系统性地收集每次适配过程中的完整上下文信息,包括环境状态、所做决策及其实际效果。定期对这些数据进行回溯分析,自动优化策略参数,例如:
由此,系统不再只是对外部环境做出反应,而是开始反思自身的适应行为,真正达成“自我进化”的闭环。
POLARIS 在设计上强调通用性,无论是传统的 Web 应用(如 SWIM)还是现代 AI 模型服务平台(如 SWITCH),只需配置相应的适配器模块和提示模板即可快速部署。无需针对每个场景重建整套逻辑,彻底解决了以往“一系统一方案”的重复开发难题,显著提升了工程复用价值。
POLARIS 的整体设计理念围绕三大核心矛盾展开:
具体实施路径分为四步:
确立 Adapter、Reasoner、Meta 三层次结构,每层配备独立智能体,形成“感知-思考-进化”的完整链条。各层之间通过标准化接口通信,保证模块解耦与灵活扩展。
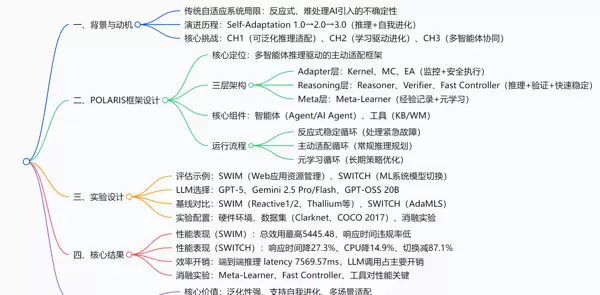
一、研究背景与核心动机
传统自适应系统的局限性:现有系统多依赖预设规则或独立的机器学习模块,仅能应对可预见的变化。面对AI原生环境中的数据漂移、模型随机切换等“未知未知”问题时,往往束手无策。此外,大多数系统采取反应式策略,无法从过往的适配行为中汲取经验进行自我优化。
演进方向展望:推动自适应系统从 Self-Adaptation 1.0(基于反馈回路的传统控制)和 2.0(引入AI辅助决策),迈向 Self-Adaptation 3.0——以推理能力、反思学习与协同机制为核心,实现具备自我进化能力的主动适配体系。
面临的关键挑战:
二、POLARIS 框架结构解析
1. 基本概念界定
| 概念 | 定义 |
|---|---|
| Agent | 在特定环境中自主运行、致力于达成某一目标的计算实体 |
| AI Agent | 具备感知、推理、学习与行动能力的智能体,能够基于环境变化动态调整行为 |
2. 系统三层架构设计
元学习层(Meta)——系统的“灵魂”:该层由 Meta-Learner(总结者)构成,负责分析历次适配过程的数据轨迹,挖掘潜在规律并优化长期策略。例如,若发现服务器利用率超过80%易引发过载,则会自动下调预警阈值,提前触发扩容动作,实现风险前置规避。
推理层(Reasoning)——系统的“大脑”:作为决策中枢,包含三个关键角色:
- Reasoner(推理师):利用大语言模型(LLM)生成高层适配策略;
- Verifier(检察官):对提案进行安全性校验,防止违反系统约束(如超出最大服务器数量);
- Fast Controller(急救员):专门处理突发状况,如响应时间骤增时立即降低处理精度以保障可用性。
适配层(Adapter)——系统的“手脚”:负责将抽象指令转化为具体操作。其中,Metric Collector(MC)实时采集性能指标(如CPU使用率、请求延迟),Kernel(内核)充当“指挥官”协调任务分发,Execution Adapter(EA)则执行实际变更,如“增加服务器实例”或“切换至轻量AI模型”。
[此处为图片3]三、三大运行循环机制(针对不同场景)
反应式稳定循环(应对紧急情况):
当 Metric Collector 检测到关键指标越界(如响应时间 > 750ms),Kernel 即刻激活 Fast Controller,启动预设应急规则快速恢复系统稳定性,随后经 Verifier 安全校验后由 Execution Adapter 执行。
主动适配循环(常规调节):
Kernel 定期调用 Reasoner 发起适配流程。Reasoner 结合知识库(KB)中的历史记录与工作记忆(WM)中的模拟预测,提出优化方案,再经 Verifier 验证后交由 EA 实施。
元学习循环(长期进化):
系统持续记录每次适配的“上下文-决策-结果”三元组,Meta-Learner 定期分析这些日志,提炼经验并更新推理逻辑或阈值设定,使整体策略随时间不断进化。
四、实验验证设计
测试对象选择:选取两个差异显著的应用场景进行评估:
① SWIM:传统Web服务系统,采用服务器扩缩容与处理保真度调节作为适配手段;
② SWITCH:AI驱动系统,通过动态切换目标检测模型实现性能平衡。
技术选型策略:
- 推理层集成 GPT-5、Gemini 及多种开源 LLM,覆盖不同性能与成本需求;
- 元学习层采用轻量级 LLM,确保分析效率不受影响。
对比实验设置:
与 Reactive1/2、Cobra、AdaMLS 等主流基线方法进行全面比较,并开展消融实验(如移除元学习层、禁用快速控制器或工具调用),验证各组件的必要性。
五、效率优化措施
主要开销来源于 LLM 的调用延迟(约3秒),但由于主动适配循环按固定周期运行,其对系统整体响应的影响极为有限。
其余操作如 KB 查询、WM 模拟等均在毫秒级完成,资源消耗几乎可以忽略不计。
六、研究成果与贡献总结
核心成果汇总表
| 研究问题(RQ) | 实验方式 | 关键结论 |
|---|---|---|
| RQ1:POLARIS 是否具备良好的泛化性与有效性? | 在 SWIM/SWITCH 上对比主流基线 + 消融实验 | 1. SWIM 场景下总效用达 5445.48,优于 Cobra 等基线; 2. SWITCH 中响应时间下降 27.3%,CPU 占用减少 14.9%,模型切换频次降低 87.1%; 3. 移除元学习层或快速控制器后性能严重下滑 |
| RQ2:系统运行效率与资源开销如何? | 端到端延迟测量 + 组件级开销分析 | 1. 主动适配循环平均延迟约 7.6 秒,处于可控范围; 2. LLM 调用是主要耗时环节,其他组件开销可忽略; 3. 开源 LLM 同样可达到接近商用模型的表现 |
通俗解读 POLARIS 的实际价值
性能全面超越传统方案:
在 Web 应用(SWIM)中,POLARIS 实现了高达 5445.48 的“总效用”评分(综合衡量稳定性与资源利用率),显著优于 Cobra、PLA 等现有方法。在 AI 模型调度场景(SWITCH)中,不仅提升了响应速度,还将“破坏性切换”次数减少了 87.1%,有效避免因频繁更换模型导致的推理误差累积。
一次开发,多场景通用:
无论是传统的服务器弹性伸缩,还是复杂的 AI 模型动态切换,POLARIS 无需重构核心逻辑,仅需配置相应的适配器即可快速部署,解决了传统系统“一个场景一套代码”的重复开发难题。
系统越用越聪明:
得益于元学习机制,系统能从每一次适配中积累经验。例如,一旦识别出“服务器负载达 80% 就可能过载”,便会自动调整策略,提前扩容,实现真正的预防性维护。
兼顾可靠性与灵活性:
通过 Fast Controller 保障极端情况下的快速响应,借助 LLM 处理复杂多变的常规决策,并由 Verifier 对所有提议进行安全审查,从而在“快”与“准”之间取得理想平衡,既敏捷又稳健。
具备推理与学习能力的AI Agent以大模型作为“认知核心”,具有可解释性与自适应性。其运行依赖于非自主性的软件工件(如知识库KB、世界模型WM),这些工具协助Agent完成感知与推理任务,但本身不具独立目标。
| 层级 | 核心组件 | 主要职责 |
|---|---|---|
| Adapter层 | Kernel(内核) | 作为中央协调器,负责将系统状态分发至对应的适配循环 |
| Metric Collector(MC) | 采集系统的原始及衍生性能指标 | |
| Execution Adapter(EA) | 将抽象的适配指令转化为特定领域可执行的操作 | |
| Reasoning层 | Reasoner(推理器) | 基于AI的智能体,利用KB与WM进行证据驱动的策略规划 |
| Verifier(验证器) | 提供安全兜底机制,确保生成计划符合系统运行不变量 | |
| Fast Controller(FC) | 在危机场景下启用低延迟预定义策略,快速恢复系统稳定 | |
| 工具(KB/WM) | KB用于存储历史经验与模式;WM支持“假设分析”类预测建模 | |
| Meta-Learner层 | Meta-Learner(元学习器) | 分析长期适配记录,识别次优行为模式,并推动系统策略进化(如更新阈值、提示模板等) |
触发条件:当Metric Collector检测到关键指标超过临界值(例如响应时间>750ms)时启动。
执行流程:Kernel调度→Fast Controller生成应急规则→经Verifier校验安全性→由Execution Adapter实施操作,实现系统快速回归安全状态。
触发条件:系统处于正常运行状态,无紧急故障发生(默认激活)。
执行流程:Kernel分发任务至Reasoner→接收目标、约束及工具接口信息→结合KB中的历史数据与WM的模拟预测结果→制定适配方案→通过Verifier审核→由EA执行落地。
执行流程:持续记录每次适配过程中的“上下文-决策-结果”三元组→Meta-Learner周期性分析积累的经验数据→发现优化空间并调整策略参数(如将服务器高负载警戒阈值从0.90下调至0.80)→同步更新Reasoner、Kernel和WM的相关配置。
[此处为图片3]| 方法 | 可选内容占比(%) | 延迟违规率(%) | 平均服务器数 | 总效用 |
|---|---|---|---|---|
| 基线(Reactive1) | 91.07 | 28.78 | 2.45 | 2647.48 |
| 基线(Cobra) | 89.00 | 3.30 | 3.00 | 5378.00 |
| POLARIS(GPT-5,全配置) | 95.08 | 6.24 | 2.82 | 5445.48 |
| POLARIS(Gemini Flash) | 94.40 | 6.00 | 2.70 | 5294.00 |
| 方法 | 平均置信度 | 响应时间中位数(s) | CPU使用率(%) | 推理速率/切换次数(inf/min) |
|---|---|---|---|---|
| AdaMLS | 0.729 | 0.132 | 56.85 | 212.78/865 |
| POLARIS | 0.688 | 0.096 | 48.36 | 244.19/112 |
| 开销类型 | 平均延迟(ms) |
|---|---|
| 端到端推理(主动适配) | 7569.57 |
| Gemini LLM调用 | 3048.31 |
| World Model操作 | 11.84 |
| LLM工具调用开销 | 5.23 |
| Knowledge Base查询 | 2.85 |
核心贡献:本工作解决了三项挑战——CH1:通过语言推理实现泛化性适配;CH2:借助元学习推动系统自我进化;CH3:构建多智能体协同机制以平衡短期响应与长期目标。
应用价值:仅需定义适配器接口与提示模板即可完成集成,支持灵活的人机协作与外部工具扩展。
未来方向:进一步探索认知反馈闭环的设计、提升语言推理的可靠性保障机制、优化人机协同交互模式。
当前研究主要基于模拟环境开展,内部有效性受限于未完全覆盖真实世界复杂情境,可能影响部分结论在实际部署中的普适性。
在评估POLARIS框架的性能与设计时,需关注其构造有效性与外部有效性的实现机制。构造有效性方面,提示的设计高度依赖开发者经验,而工具集成则需要明确的调用规则以确保功能正确执行;外部有效性层面,当前知识库(KB)采用内存存储方式,工作记忆(WM)模型的行为则受限于具体实现细节。
POLARIS框架的核心创新体现在其提出的多智能体推理驱动的三层架构以及Self-Adaptation 3.0范式,实现了“适配行为自身可进化”的能力。相较于传统自适应系统,主要区别体现在以下三个方面:
在两类典型应用场景中,POLARIS在效用、效率及系统稳定性方面均显著优于现有基线方案:
关于POLARIS的实际运行表现,可从以下角度进行分析:
POLARIS提出了一种全新的自适应系统设计范式,依托三层多智能体架构、工具感知推理机制与元学习技术,成功推动自适应系统进入“主动推理+自我进化”的3.0阶段。它不仅克服了传统方案泛化能力弱、难以应对AI原生不确定性的局限,在多种类型系统中展现出卓越的性能优势,同时还保持了较低的运行开销与高度灵活性。对于电商、AI服务平台、分布式系统等需要应对复杂动态环境的业务场景,POLARIS提供了一个即插即用的解决方案,并为未来研究指明了“多智能体协同推理+自进化机制”这一重要发展方向。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




