本文发表于2023年,主要研究方向为3D视觉-语言接地(3D-Visual Language Grounding),提出了一种基于Transformer架构的预训练模型——3D-VisTA(1),并构建了首个大规模用于3D视觉与语言联合建模的预训练数据集ScanScribe(2)。该数据集融合了ScanNet与3RScan中的真实三维场景信息,并利用GPT自动生成高质量的场景文本描述,为后续多模态任务提供了坚实基础。
3D-VisTA在ScanScribe数据集上通过掩码语言建模、掩码对象建模以及场景-文本匹配等自监督学习策略进行预训练,实现了对3D场景与自然语言之间细粒度语义对齐的有效建模。该方法展现出良好的迁移能力,在多个下游3D视觉语言任务中均取得显著性能提升。
当前大多数针对3D视觉语言接地的研究往往局限于单一或少数特定任务,例如仅关注特征提取、视觉定位、密集描述生成、问答系统或情境推理等方面,缺乏一个统一且通用的框架来整合多种模态交互能力。这种割裂性限制了模型在复杂真实场景中的泛化表现。
其中,密集描述生成(Dense Captioning)指在单张图像或三维场景中,同步检测多个区域(Region Proposals)并对每个区域生成独立、准确的文字描述的任务,是衡量模型综合理解能力的重要指标之一。
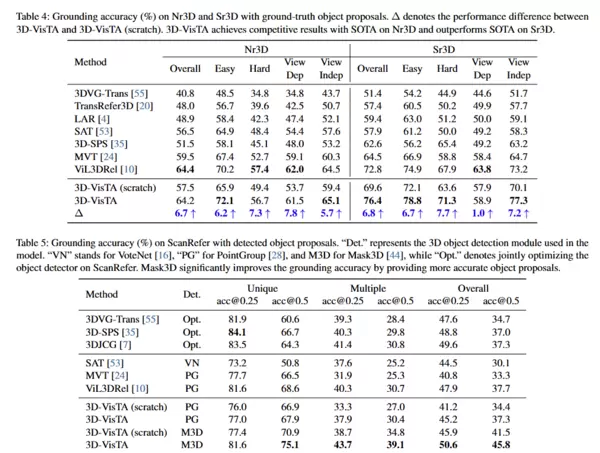
实验结果表明,3D-VisTA在多个关键3D-VL任务及相关数据集上实现了性能突破:
- 视觉接地任务:在ScanRefer上提升8.1%,在Nr3D/Sr3D上提升3.6%
- 视觉问答任务:ScanQA指标提升10.1%
- 情境推理任务:SQA3D准确率提高1.9%
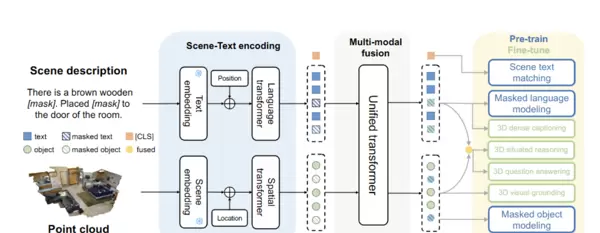
3D-VisTA 模型架构
模型输入包括三维场景点云和对应的自然语言句子。首先,通过场景编码模块处理原始点云数据,将其分解为多个独立对象,并提取其几何与语义特征;随后生成文本标记与对象标记,送入多模态融合模块中进行深度交互,以捕捉文本词语与3D空间对象之间的精确对应关系。
1. 场景编码模块
给定一个三维场景的原始点云数据,系统使用分割掩码将整个场景划分为若干个独立的对象单元。分割掩码可通过以下两种方式获得:
- 使用人工标注的真实标签
- 借助实例分割模型自动生成
对于每一个分割出的对象,采样1024个点并将其坐标归一化至单位球内,以保证输入的一致性。这些点被送入PointNet++网络中,提取出每一点的局部特征(点特征)以及整体对象的语义类别信息。
进一步地,将点特征、语义类别、嵌入向量及三维位置信息进行组合,形成最终的对象标记表示。该表示被输入到一个4层的Transformer结构中,用以建模不同物体之间的空间交互关系。特别地,模型将物体间的成对空间关系显式编码进空间Transformer中,增强对场景布局的理解能力。

2. 实验设置
训练过程中采用如下超参数配置:
- 训练轮数(epoch):30
- 批量大小(batch size):128
- 初始学习率:1e-4
- 学习率预热步数:3000
- 学习率调度策略:余弦退火衰减
- 优化器:AdamW(β=0.9, β=0.98)


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





