经管之家App
让优质教育人人可得
立即打开


面对将 Word 文档内容完整导入到富文本编辑器中的需求,我本以为这只是个小问题。然而,这一路走来,堪称“血泪史”。以下是我在 Vue2 项目中集成 TinyMCE 并实现 .docx 文件内容(含图片和格式)正确导入的真实探索过程。
“不就是导入个 Word 吗?搜一下教程,分分钟搞定!”抱着这样的想法,我在搜索引擎中输入关键词“Vue2 TinyMCE 导入 Word”。
十分钟后……
结果令人崩溃:大部分文章停留在 2016 年,内容早已过时;少数几篇提到的方案要么是收费插件推广,要么直接断言“无法实现”,语气还特别笃定。而真正能跑通的开源示例几乎为零。
我盯着界面上那个灰色的“粘贴”按钮,仿佛它正冷冷地看着我:“连文档解析都不会,还做啥前端?”
听说 mammoth.js 是处理 docx 的热门选择,于是我立刻上手:
mammoth.extractRawText({ arrayBuffer: fileBuffer })
.then(function(result) {
console.log(result.value); // 哇!文字提取出来了!
console.log(result.messages); // 但是…这是什么 [image:123]?
});
虽然文本顺利输出,但所有图片都被替换成了类似 [image:123] 的占位符,毫无实际作用。
[image:123]看着控制台里一串又一串的图像标记,我不禁发问:“我的图片去哪儿了?难道被外星人劫持了?”
接着我转向 docx-preview,这个库号称支持完整的文档渲染:
import { renderAsync } from 'docx-preview';
renderAsync(fileBuffer, document.getElementById('preview-container'))
.then(() => {
console.log('渲染成功!');
});
确实,页面上出现了完整的 Word 内容预览,图文并茂,效果惊艳。可问题是——这只是一个静态展示区域,TinyMCE 编辑器本身依然是空的。
那一刻我终于明白:有些功能,看看就好,别指望拿来当生产工具用。
既然纯前端搞不定,那就把解析工作交给后端。我找到 Java 组的同事求助,对方花了一整天写了个 SpringBoot 接口专门处理 docx 解析。
@PostMapping("/import-docx")
public ResponseEntity<String> importDocx(@RequestParam("file") MultipartFile file) {
try {
XWPFDocument document = new XWPFDocument(file.getInputStream());
// 复杂的解析逻辑...
return ResponseEntity.ok(htmlContent);
} catch (Exception e) {
return ResponseEntity.badRequest().body("导入失败:" + e.getMessage());
}
}
接口返回 HTML 字符串后,我迫不及待地将其注入 TinyMCE:
tinymce.activeEditor.setContent(response.data);
结果却再次被打脸——所有图片均显示为 404 错误。
/images/123.jpg原因很快查明:后端生成的 HTML 中图片路径是相对路径(如 media/image1.png),而这些资源并未部署在前端服务器上,自然无法访问。
看来,想要彻底解决问题,必须由前端亲自完成以下几个步骤:
于是,我开始着手编写图片提取逻辑:
function extractImagesFromDocx(file) {
return new Promise((resolve) => {
const zip = new JSZip();
zip.loadAsync(file)
.then(zip => {
const images = [];
zip.forEach((relativePath, fileEntry) => {
if (/\.(jpeg|jpg|png|gif)$/i.test(relativePath)) {
fileEntry.async('blob').then(blob => {
images.push(blob);
// 问题来了:怎么判断 images 已收集完毕?
});
}
});
});
});
}
很快发现致命缺陷:由于无法预先知道 docx 中有多少张图片,images.length === 总数 这个条件永远无法触发,Promise 永远不会 resolve。
为了提升性能且避免主线程阻塞,我决定将整个解析过程移入 Web Worker,并通过 Promise.all 管理异步任务队列:
// 在 Web Worker 中
self.onmessage = function(e) {
const file = e.data.file;
const zip = new JSZip();
zip.loadAsync(file).then(zip => {
const imagePromises = [];
zip.forEach((relativePath, fileEntry) => {
if (/\.(jpeg|jpg|png|gif)$/i.test(relativePath)) {
imagePromises.push(
fileEntry.async('blob').then(blob => ({
name: relativePath,
blob: blob
}))
);
}
});
// 使用 Promise.all 等待全部图片加载完成
Promise.all(imagePromises).then(images => {
self.postMessage({ images });
});
});
};
这样一来,不仅能准确获取所有图片资源,还能保证异步流程可控、可追踪,为后续上传打下坚实基础。
这场历时四天的“Word 导入攻坚战”,让我深刻体会到:看似简单的功能背后,往往隐藏着复杂的兼容性与工程难题。尤其是涉及跨平台文档解析时,前端不能完全依赖第三方库,更需要深入理解文件结构(.docx 实质是一个 ZIP 包)、资源管理机制以及前后端协作方式。
最终方案的核心思路是:
虽然过程曲折,但每一步踩过的坑,都是通往成熟的必经之路。
终于完成了!我激动地看到每一张图片都成功上传,但紧接着发现问题:
图片的上传顺序与文档中实际出现的顺序不一致,导致所有图片位置错乱。
mammoth.js“干脆直接修改 TinyMCE 的源码!”我下定决心,打开了 TinyMCE 的 paste 插件代码。
通过以下配置监听并处理粘贴行为:
tinymce.init({
// ...其他配置
setup: function(editor) {
editor.on('paste', function(e) {
const clipboardData = e.clipboardData || window.clipboardData;
const items = clipboardData.items;
for (let i = 0; i < items.length; i++) {
if (items[i].type.indexOf('image') !== -1) {
const blob = items[i].getAsFile();
// 上传图片并替换为URL
uploadImage(blob).then(url => {
editor.insertContent(`<img src="${url}">`);
});
e.preventDefault();
}
}
});
}
});
然而,这个方法仅适用于直接粘贴图片的场景,对于从 Word 中复制的内容仍无法有效处理。
JSZip最终我采用了一套组合策略:
async function importWordToTinyMCE(file) {
// 1. 提取文本内容及占位符
const result = await mammoth.extractRawText({ arrayBuffer: await file.arrayBuffer() });
// 2. 解析Word中的图片文件
const zip = await JSZip.loadAsync(file);
const imageBlobs = [];
const imagePaths = [];
zip.forEach((relativePath, fileEntry) => {
if (/\.(jpeg|jpg|png|gif)$/i.test(relativePath)) {
fileEntry.async('blob').then(blob => {
imageBlobs.push(blob);
imagePaths.push(relativePath);
});
}
});
// 3. 批量上传图片(简化逻辑)
const uploadedUrls = await Promise.all(
imageBlobs.map(blob => uploadImageToServer(blob))
);
// 4. 替换占位符为真实图片地址
let html = result.value;
uploadedUrls.forEach((url, index) => {
html = html.replace(`[image:${index}]`, `<img src="${url}">`);
});
// 5. 将处理后的HTML内容设置进编辑器
tinymce.activeEditor.setContent(html);
}
经过连续五天的努力攻坚,最终实现了以下目标:
复制插件文件
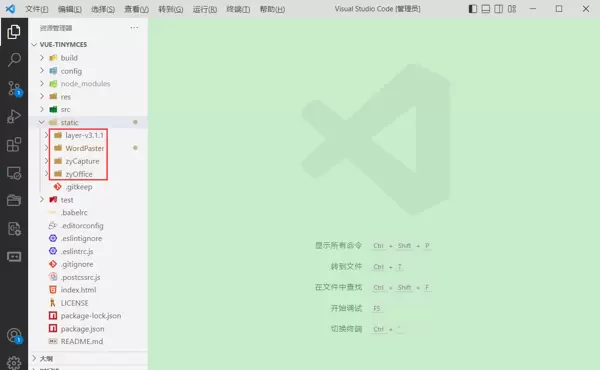
安装 jQuery 依赖:
npm install jquery
在项目组件中引入相关脚本文件
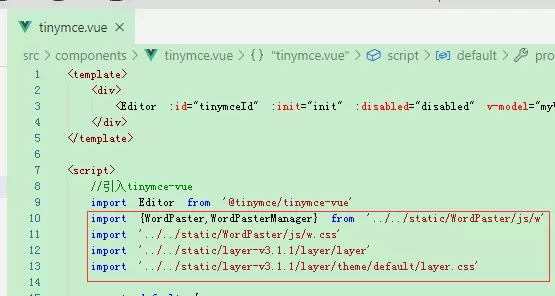
配置并添加编辑器工具栏功能

添加自定义插件支持
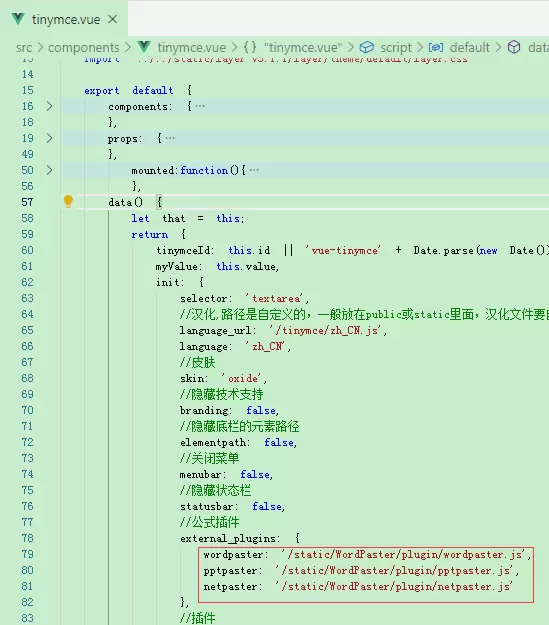
初始化富文本组件实例

在页面中注册并使用该组件
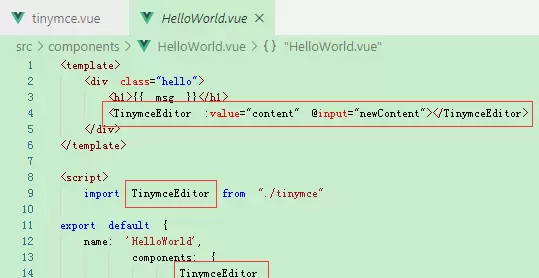
当前已实现 Word 文档的上传与内容正确渲染,基础样式得以保留(尽管仍有优化空间)。
如今,当我看到编辑器中完整呈现的 Word 内容时,不禁回想起最初那个满怀信心却一知半解的自己,嘴角微微上扬:“菜鸟,你确实成长了!”

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




