1. 下载模型
所部署的模型为 Qwen3-8B,可通过以下链接获取:
https://modelscope.cn/models/Qwen/Qwen3-8B
推荐使用 SDK 方式进行下载。
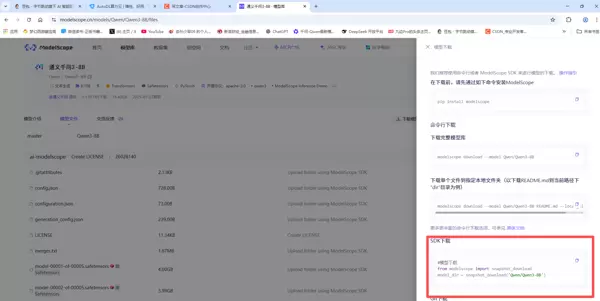
2. 租用显卡
由于本地设备硬件配置有限,决定采用云端算力服务完成部署。选用平台为:
https://www.autodl.com/home
推荐选择 RTX 4090 型号显卡进行环境搭建。具体配置参考下图。若在后续使用 vLLM 部署时出现版本兼容性问题,可尝试将 4090D 更换为标准版 4090 显卡以解决冲突。

3. 启动与模型下载
启动实例后,创建一个 Python 脚本用于拉取模型文件,脚本内容如下图所示。执行该脚本即可开始自动下载和安装过程。
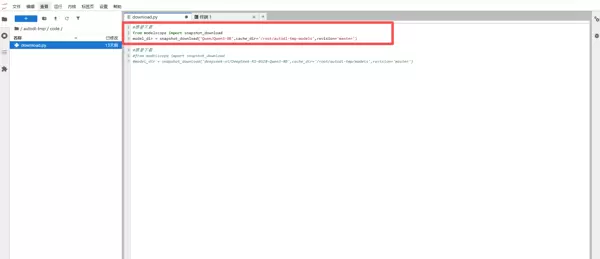
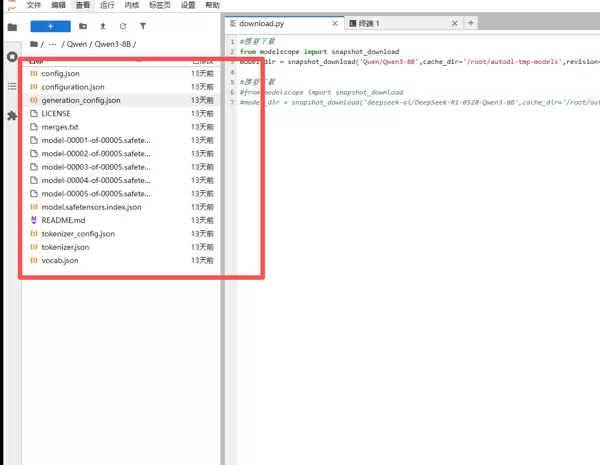
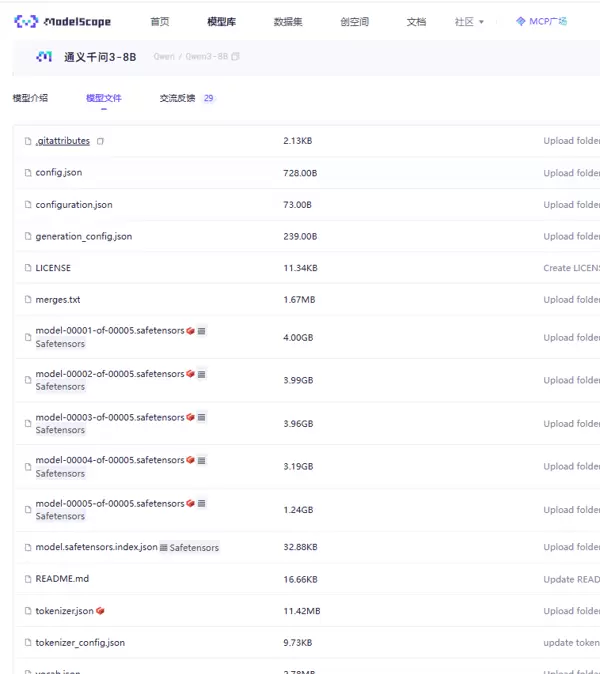
4. 模型文件验证
为确认模型是否成功下载,需核对本地存储路径中的文件结构与 ModelScope 官网提供的模型文件列表是否一致。若两者匹配,则表示下载完整无误。
5. 使用 vLLM 进行模型部署
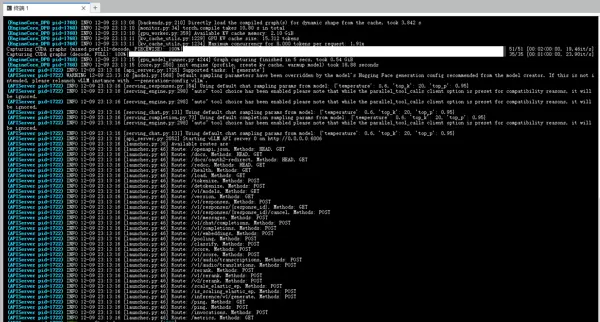
完成模型下载后,进入部署阶段。首先在终端运行命令:pip install vllm 安装推理框架。安装完成后,输入相应的部署指令,系统将在启动后输出类似下图的提示信息。
vLLM 的核心作用在于解决“如何高效、稳定且低成本地将大模型转化为对外提供推理服务的系统”这一关键问题。可以说,vLLM 并非普通附加工具,而是一个面向大模型推理场景的高性能运行时框架,专门应对原生部署方式中存在的多种瓶颈与挑战。
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/Qwen/Qwen3-8B \
--served-model-name qwen3-8b \
--max-model-len 8k \
--host 0.0.0.0 \
--port 6006 \
--dtype bfloat16 \
--gpu-memory-utilization 0.8 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
6. 对部署后的 Qwen3 模型进行测试
在算力云平台中找到对应的 base_url 地址,并注意在 URL 末尾添加 "/v1" 路径。运行测试代码后,实际返回结果可参考下图所示内容。
from openai import OpenAI
client=OpenAI(base_url='XXXX/v1',api_key='xxxx')
resp=client.chat.completions.create(
model='qwen3-8b',
messages=[{'role':'user','content':'请介绍下什么是深度学习'}],
temperature=0.8,
presence_penalty=1.5,
##千问3特有的参数,是否开启深度思考
extra_body={'chat_temp_kwargs':{'enable_thinking':True}}
)
print(resp.choices[0].message.content)
<think>
好的,我现在需要向用户介绍什么是深度学习。首先,我应该先回忆一下深度学习的基本概念和关键点。深度学习是机器学习的一个子领域,对吧?那它跟传统的机器学习有什么不同呢?可能在于它使用多层的神经网络结构,也就是所谓的深度神经网络。
接下来,我需要解释清楚什么是神经网络。神经网络模仿人脑的结构和功能,由输入层、隐藏层和输出层组成。每一层都有许多节点,这些节点之间通过权重连接。深度学习的关键在于“深度”,也就是隐藏层的数量很多,这样模型可以学习到更复杂的特征。
然后,得提到深度学习的主要应用领域,比如计算机视觉、自然语言处理、语音识别等等。举一些例子可能会更好,比如图像分类中的卷积神经网络(CNN),或者自然语言处理中的循环神经网络(RNN)和Transformer模型。
还要讲讲深度学习的工作原理,比如前向传播、损失函数、反向传播和优化算法。这部分可能需要用简单的语言解释,避免太专业的术语,但也不能太笼统,否则用户可能不太理解。
另外,深度学习需要大量的数据和计算资源,比如GPU加速。这点也很重要,因为很多人可能不知道训练深度学习模型需要这么多资源。
可能还需要比较深度学习和其他机器学习方法的区别,比如传统机器学习通常需要手动提取特征,而深度学习可以自动学习特征,这可能是它的优势之一。
不过,也要提到深度学习的一些挑战,比如数据需求大、模型复杂度高、训练时间长,还有过拟合的问题。这些内容能帮助用户更全面地了解深度学习的优缺点。
最后,总结一下深度学习的重要性和发展趋势,比如在当前AI技术中的地位,以及未来的潜力。这样用户就能有一个整体的认识。
现在需要组织这些信息,确保逻辑清晰,层次分明。可能从定义开始,然后结构、工作原理、应用场景、优缺点,最后总结。同时要注意用例子来辅助说明,让内容更生动易懂。
检查有没有遗漏的重要点,比如深度学习的典型模型如CNN、RNN、GAN等,是否需要提及?可能需要简要提一下,但不要展开太多,以免信息过载。
另外,是否需要解释监督学习、无监督学习和强化学习与深度学习的关系?比如深度学习可以用于这三种学习类型,但可能不需要深入,除非用户特别问起。
总之,保持回答简洁明了,覆盖主要方面,同时提供足够的背景信息和例子,帮助用户建立基本的理解。
</think>
深度学习(Deep Learning)是**机器学习**的一个子领域,其核心思想是通过模拟人脑神经网络的结构和功能,构建多层的非线性模型(称为深度神经网络),从而从数据中自动学习复杂的模式和特征。以下是关于深度学习的详细介绍:
---
### **1. 基本概念**
- **神经网络**:深度学习的基础是人工神经网络(Artificial Neural Network, ANN)。一个典型的神经网络由多层节点(神经元)组成:
- **输入层**:接收原始数据。
- **隐藏层**:通过非线性变换提取特征(深度学习的关键在于隐藏层的数量较多,通常超过3层)。
- **输出层**:生成最终结果(如分类标签、预测值等)。
- **深度**:指网络中隐藏层的数量。深度越大,模型能够捕捉的数据特征越复杂。
---
### **2. 工作原理**
- **前向传播**:输入数据通过各层网络逐层传递,每层通过加权求和和激活函数(如ReLU、Sigmoid)计算输出。
- **损失函数**:衡量模型预测结果与真实标签之间的误差(如交叉熵、均方误差)。
- **反向传播**:通过梯度下降算法调整网络参数(权重和偏置),最小化损失函数。
- **优化算法**:如随机梯度下降(SGD)、Adam等,用于高效更新参数。
---
### **3. 核心特点**
- **自动特征提取**:无需人工设计特征,模型通过多层网络自动学习数据的层次化特征(例如:从像素到边缘、到物体部件,再到整个物体)。
- **强大的非线性建模能力**:通过多层非线性变换,能够拟合复杂的数据分布。
- **大数据依赖**:需要大量标注数据进行训练,数据量越大,模型性能通常越好。
- **计算资源需求高**:依赖GPU/TPU等硬件加速,训练过程耗时且成本较高。
---
### **4. 典型应用领域**
- **计算机视觉**:
- 图像分类(如ResNet、VGG)
- 目标检测(YOLO、Faster R-CNN)
- 图像生成(GANs)
- **自然语言处理**:
- 机器翻译(Transformer、BERT)
- 文本生成(GPT系列)
- 情感分析
- **语音识别**:
- 语音转文字(如Google Speech-to-Text)
- 语音合成
- **强化学习**:
- 游戏AI(AlphaGo、DQN)
- 自动驾驶
---
### **5. 常见模型架构**
- **卷积神经网络(CNN)**:擅长处理网格状数据(如图像),通过卷积层提取空间特征。
- **循环神经网络(RNN)**:适用于序列数据(如文本、时间序列),可记忆先前信息。
- **Transformer**:基于自注意力机制,广泛应用于NLP任务(如BERT、GPT)。
- **生成对抗网络(GAN)**:由生成器和判别器竞争,用于图像生成、风格迁移等。
---
### **6. 优势与挑战**
- **优势**:
- 高精度:在图像识别、语音处理等领域达到或超越人类水平。
- 可扩展性:通过增加层数或数据量可进一步提升性能。
- **挑战**:
- 数据依赖性强:需大量高质量标注数据。
- 计算成本高:训练和推理需要高性能硬件。
- 黑箱问题:模型决策过程难以解释,存在“不可解释性”风险。
- 过拟合:模型可能过度适应训练数据,导致泛化能力差。
---
### **7. 发展趋势**
- **模型轻量化**:研究更高效的模型(如MobileNet、EfficientNet)以适应移动端部署。
- **自监督学习**:减少对标注数据的依赖(如对比学习、掩码预测)。
- **多模态融合**:结合文本、图像、语音等多种数据源(如CLIP、Multimodal Transformers)。
- **可解释性研究**:开发工具(如Grad-CAM、LIME)以增强模型透明度。
---
### **总结**
深度学习通过模拟神经网络的分层结构,实现了从数据中自动学习复杂模式的能力,成为推动人工智能突破的关键技术。尽管面临数据、计算和可解释性等挑战,其在多个领域的广泛应用表明,它是未来智能系统的核心支柱之一。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





