经管之家App
让优质教育人人可得
立即打开


pip install matplotlib pandas scipy scikit-learn| 特征名称 | 说明 | 量纲 |
|---|---|---|
| avg_goals | 场均进球数 | 个 / 场 |
| avg_concede | 场均失球数 | 个 / 场 |
| avg_yellow | 场均黄牌数 | 张 / 场 |
| win_rate | 胜率(胜场 / 总场数) | % |
| half_win_rate | 半场领先后获胜的比例 | % |
team avg_goals avg_concede avg_yellow win_rate half_win_rate is_champion 巴西(1970) 2.8 0.8 1.2 85 90 1 德国(1990) 2.0 0.7 1.5 80 88 1 日本(2002) 1.1 1.2 1.8 33 60 0 韩国(2002) 1.0 1.1 2.0 40 65 0
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
# ---------------------- 1. 数据准备与预处理 ----------------------
# 模拟世界杯球队多维数据
data = {
"team": ["巴西(1970)", "德国(1990)", "阿根廷(1986)", "法国(1998)", "意大利(2006)",
"西班牙(2010)", "乌拉圭(1930)", "英格兰(1966)", "日本(2002)", "韩国(2002)",
"墨西哥(1986)", "比利时(2014)", "瑞士(2014)", "瑞典(2006)", "智利(2010)",
"哥伦比亚(2014)", "尼日利亚(1994)", "喀麦隆(1990)", "美国(1994)", "澳大利亚(2006)"],
"avg_goals": [2.8, 2.1, 2.5, 2.3, 1.9, 2.0, 2.2, 2.4, 1.0, 1.1, 1.2, 1.5, 1.3, 1.4, 1.2, 1.6, 1.0, 0.9, 1.1, 0.8],
"avg_concede": [0.8, 0.7, 0.9, 0.8, 0.6, 0.5, 1.0, 0.8, 1.2, 1.1, 1.1, 0.9, 1.0, 1.1, 1.3, 1.0, 1.2, 1.4, 1.3, 1.5],
"avg_yellow": [1.2, 1.5, 1.1, 1.3, 1.4, 1.2, 1.6, 1.3, 1.8, 2.0, 1.7, 1.5, 1.6, 1.7, 1.9, 1.4, 1.8, 2.1, 1.7, 1.9],
"win_rate": [85, 80, 82, 78, 81, 83, 75, 79, 33, 40, 38, 55, 45, 42, 39, 50, 35, 28, 36, 30],
"half_win_rate": [90, 88, 89, 85, 87, 86, 80, 84, 60, 65, 62, 70, 68, 66, 61, 69, 58, 55, 60, 56],
"is_champion": [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
df = pd.DataFrame(data)
# 提取特征列(排除非数值列)
features = ["avg_goals", "avg_concede", "avg_yellow", "win_rate", "half_win_rate"]
X = df[features].values
# 标准化(关键:消除量纲影响,比如胜率是百分比,进球数是个位数)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
df_scaled = pd.DataFrame(X_scaled, columns=features)
df_scaled["is_champion"] = df["is_champion"]
df_scaled["team"] = df["team"]
# ---------------------- 2. 生成安德鲁斯曲线的t值与曲线值 ----------------------
# 生成t序列(范围[-π, π],取1000个点保证曲线平滑)
t = np.linspace(-np.pi, np.pi, 1000)
# 定义安德鲁斯曲线计算函数
def andrews_curve(row, t):
"""
计算单条安德鲁斯曲线的y值
row: 标准化后的特征行(一维数组)
t: t值序列
"""
n = len(row)
y = row[0] / np.sqrt(2) # 第一项:x1/√2
for i in range(1, n):
if i % 2 == 1: # 奇数项:sin(k*t),k = (i+1)/2
k = (i + 1) // 2
y += row[i] * np.sin(k * t)
else: # 偶数项:cos(k*t),k = i/2
k = i // 2
y += row[i] * np.cos(k * t)
return y
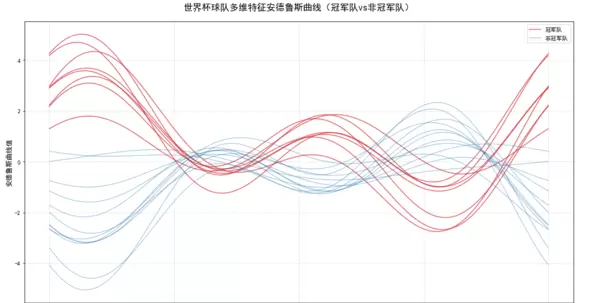
# ---------------------- 3. 绘制安德鲁斯曲线 ----------------------
# 设置中文显示
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 创建画布
fig, ax = plt.subplots(figsize=(14, 8))
# 按类别绘制曲线:冠军队(红色)、非冠军队(蓝色)
# 冠军队曲线
champion_data = df_scaled[df_scaled["is_champion"] == 1]
for idx, row in champion_data.iterrows():
y = andrews_curve(row[features].values, t)
ax.plot(t, y, color="#d62728", alpha=0.7, linewidth=1.5, label="冠军队" if idx == champion_data.index[0] else "")
# 非冠军队曲线
non_champion_data = df_scaled[df_scaled["is_champion"] == 0]
for idx, row in non_champion_data.iterrows():
y = andrews_curve(row[features].values, t)
ax.plot(t, y, color="#1f77b4", alpha=0.5, linewidth=1, label="非冠军队" if idx == non_champion_data.index[0] else "")
# ---------------------- 4. 图表基础美化 ----------------------
ax.set_title("世界杯球队多维特征安德鲁斯曲线(冠军队vs非冠军队)", fontsize=16, pad=20)
ax.set_xlabel("t(弧度)", fontsize=12)
ax.set_ylabel("安德鲁斯曲线值", fontsize=12)
ax.grid(True, linestyle="--", alpha=0.5)
# 添加图例(避免重复)
ax.legend(loc="upper right", fontsize=10)
# 调整x轴刻度为π的倍数,更易解读
ax.set_xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi])
ax.set_xticklabels(["-π", "-π/2", "0", "π/2", "π"], fontsize=10)
plt.tight_layout()
plt.show()import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
# ---------------------- 1. 数据预处理(同基础版) ----------------------
data = {
"team": ["巴西(1970)", "德国(1990)", "阿根廷(1986)", "法国(1998)", "意大利(2006)",
"西班牙(2010)", "乌拉圭(1930)", "英格兰(1966)", "日本(2002)", "韩国(2002)",
"墨西哥(1986)", "比利时(2014)", "瑞士(2014)", "瑞典(2006)", "智利(2010)",
"哥伦比亚(2014)", "尼日利亚(1994)", "喀麦隆(1990)", "美国(1994)", "澳大利亚(2006)"],
"avg_goals": [2.8, 2.1, 2.5, 2.3, 1.9, 2.0, 2.2, 2.4, 1.0, 1.1, 1.2, 1.5, 1.3, 1.4, 1.2, 1.6, 1.0, 0.9, 1.1, 0.8],
"avg_concede": [0.8, 0.7, 0.9, 0.8, 0.6, 0.5, 1.0, 0.8, 1.2, 1.1, 1.1, 0.9, 1.0, 1.1, 1.3, 1.0, 1.2, 1.4, 1.3, 1.5],
"avg_yellow": [1.2, 1.5, 1.1, 1.3, 1.4, 1.2, 1.6, 1.3, 1.8, 2.0, 1.7, 1.5, 1.6, 1.7, 1.9, 1.4, 1.8, 2.1, 1.7, 1.9],
"win_rate": [85, 80, 82, 78, 81, 83, 75, 79, 33, 40, 38, 55, 45, 42, 39, 50, 35, 28, 36, 30],
"half_win_rate": [90, 88, 89, 85, 87, 86, 80, 84, 60, 65, 62, 70, 68, 66, 61, 69, 58, 55, 60, 56],
"is_champion": [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
df = pd.DataFrame(data)
features = ["avg_goals", "avg_concede", "avg_yellow", "win_rate", "half_win_rate"]
X = df[features].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
df_scaled = pd.DataFrame(X_scaled, columns=features)
df_scaled["is_champion"] = df["is_champion"]
df_scaled["team"] = df["team"]
# ---------------------- 2. 安德鲁斯曲线计算 + 平均曲线 ----------------------
t = np.linspace(-np.pi, np.pi, 1000)
def andrews_curve(row, t):
n = len(row)
y = row[0] / np.sqrt(2)
for i in range(1, n):
if i % 2 == 1:
k = (i + 1) // 2
y += row[i] * np.sin(k * t)
else:
k = i // 2
y += row[i] * np.cos(k * t)
return y
# 计算冠军队/非冠军队的平均曲线
champion_X = df_scaled[df_scaled["is_champion"] == 1][features].values
champion_avg = np.mean(champion_X, axis=0)
champion_avg_curve = andrews_curve(champion_avg, t)
non_champion_X = df_scaled[df_scaled["is_champion"] == 0][features].values
non_champion_avg = np.mean(non_champion_X, axis=0)
non_champion_avg_curve = andrews_curve(non_champion_avg, t)
# ---------------------- 3. 精细化绘制 ----------------------
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
fig, ax = plt.subplots(figsize=(16, 9))
# 1. 绘制所有样本曲线(低透明度)
# 冠军队
champion_data = df_scaled[df_scaled["is_champion"] == 1]
for idx, row in champion_data.iterrows():
y = andrews_curve(row[features].values, t)
ax.plot(t, y, color="#d62728", alpha=0.4, linewidth=1)
# 非冠军队
non_champion_data = df_scaled[df_scaled["is_champion"] == 0]
for idx, row in non_champion_data.iterrows():
y = andrews_curve(row[features].values, t)
ax.plot(t, y, color="#1f77b4", alpha=0.3, linewidth=1)
# 2. 绘制平均曲线(加粗+醒目颜色)
ax.plot(t, champion_avg_curve, color="#e74c3c", linewidth=3, label="冠军队平均曲线")
ax.plot(t, non_champion_avg_curve, color="#3498db", linewidth=3, label="非冠军队平均曲线")
# 3. 标注经典冠军队曲线(巴西、德国)
brazil_row = df_scaled[df_scaled["team"] == "巴西(1970)"][features].values[0]
brazil_curve = andrews_curve(brazil_row, t)
ax.plot(t, brazil_curve, color="#c0392b", linewidth=2.5, linestyle="--", label="巴西(1970)")
germany_row = df_scaled[df_scaled["team"] == "德国(1990)"][features].values[0]
germany_curve = andrews_curve(germany_row, t)
ax.plot(t, germany_curve, color="#e67e22", linewidth=2.5, linestyle="--", label="德国(1990)")
# ---------------------- 4. 高级美化与解读 ----------------------
# 标题与标签
ax.set_title("世界杯球队多维特征安德鲁斯曲线(1930-2014)", fontsize=18, pad=25)
ax.set_xlabel("t(弧度)", fontsize=14)
ax.set_ylabel("安德鲁斯曲线值", fontsize=14)
# x轴刻度优化
ax.set_xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi])
ax.set_xticklabels(["-π", "-π/2", "0", "π/2", "π"], fontsize=12)
# 网格与图例
ax.grid(True, linestyle="--", alpha=0.6)
ax.legend(loc="upper right", fontsize=12, framealpha=0.9)
# 添加关键节点解读标注
ax.annotate(
"胜率/半场胜率主导区间",
xy=(0, 1.5), xytext=(0.5, 2.5),
arrowprops=dict(arrowstyle="->", color="black", lw=1.5),
fontsize=12, fontweight="bold"
)
ax.annotate(
"场均进球/失球主导区间",
xy=(np.pi/2, -1), xytext=(np.pi/2 + 0.5, -2),
arrowprops=dict(arrowstyle="->", color="black", lw=1.5),
fontsize=12, fontweight="bold"
)
plt.tight_layout()
# 导出高清图片(可选)
plt.savefig("worldcup_andrews_curve.png", dpi=300, bbox_inches="tight")
plt.show()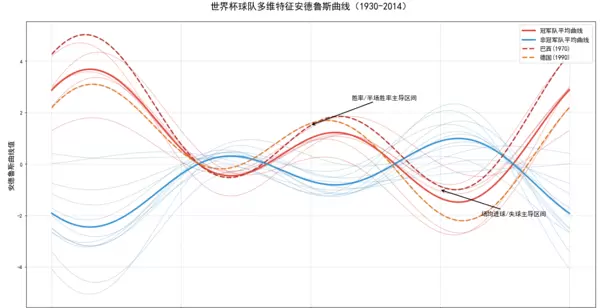
alpha=0.3-0.5StandardScalerMinMaxScalermpl_interactions六、总结与拓展
安德鲁斯曲线作为 Matplotlib 可视化体系中的重要组成部分,是进行高维数据探索的有效手段。本文以世界杯球队的多维数据为案例,系统展示了从基础绘图到细节优化的完整实现流程,深入剖析了该方法在实际场景中的应用价值。
多子图对比分析:将年代划分为两个阶段(1930–1970 年和 1971–2014 年),分别绘制子图,通过观察曲线形态的演变趋势,揭示不同历史时期的数据特征变化规律。
拓展应用场景:

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




