快速搭建Hadoop集群:详细操作指南
Hadoop集群的部署可以分为三个主要阶段:前置环境准备、核心配置文件设置,以及最后的启动与验证。通过三台虚拟机协同操作,可高效完成整个集群的构建。以下为具体实施步骤。
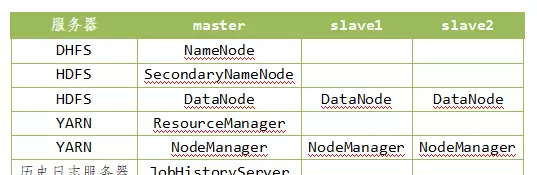
一、系统环境初始化
1. 主机名与网络映射配置
为确保各节点之间能准确通信,需先对每台虚拟机进行主机名称设定及IP地址映射。
临时修改主机名:
可通过命令行直接更改当前会话中的主机名,但重启后失效。
hostname [主机名称]
永久修改主机名:
编辑对应系统配置文件,将原有名称替换为目标名称,保存后重启系统即可生效。
vi /etc/hostname
reboot
2. 防火墙关闭
为避免网络策略干扰集群内部通信,建议关闭防火墙服务。
执行如下命令完成关闭操作:
systemctl stop firewalld
systemctl disable firewalld
3. 配置hosts映射
主机名修改完成后,需配置/etc/hosts文件以实现节点间的域名解析。
每个“节点”即代表一台虚拟机,其对应IP可通过ip a命令查看。
输出信息中显示的IPv4地址即为本机IP地址,用于后续映射配置。
vi /etc/hosts
##############
第一个节点ip 名称
第二个节点ip 名称
第三个节点ip 名称
4. SSH免密登录设置
SSH免密登录是Hadoop主节点远程管理从节点的基础。若未正确配置,可能导致启动时出现节点连接异常或身份识别错误。
首先生成本地密钥对,使用ssh-keygen命令并连续按四次回车完成默认路径创建。
ssh-keygen
随后将公钥分发至所有其他集群节点,包括自身,确保全集群互通。
ssh-copy-id 节点1
ssh-copy-id 节点2
ssh-copy-id 节点3
在首次连接过程中需输入yes确认信任,并提供一次密码验证。完成之后即可实现无密码访问。
二、软件环境与核心文件配置
1. Java环境安装与变量设置
Hadoop依赖Java运行环境,因此需预先安装JDK并配置全局可用的环境变量。
使用tar命令解压下载好的JDK安装包:
tar -zxvf /opt/software/jdk-8u191-linux-x64.tar.gz -C /opt/module/
语法格式为:tar [参数] [压缩包] -C [目标路径]
解压完毕后,编辑/etc/profile文件,添加JAVA_HOME路径及其bin目录至PATH变量中。
export JAVA_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA_HOME/bin
保存退出后,执行命令使配置立即生效。
source /etc/profile
最后通过java -version命令检验版本信息,确认配置成功。

2. Hadoop解压与基础环境配置
完成Java环境后,开始部署Hadoop主程序。
同样使用tar工具解压Hadoop安装包到指定目录。
tar -zxvf /opt/software/hadoop-3.3.6.tar.gz -C /opt/module/
接着配置Hadoop的环境变量,将其bin和sbin目录加入系统PATH,以便全局调用命令。
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
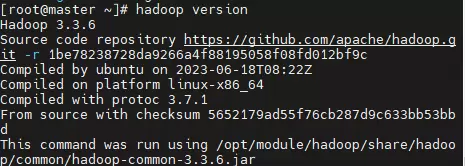
刷新环境配置后,执行hadoop version检查是否正确识别版本。
3. 集群核心配置文件编写
进入$HADOOP_HOME/etc/hadoop/目录,依次编辑关键配置文件。
(1)Hadoop运行环境脚本配置 —— hadoop-env.sh
在此文件中明确指定Java安装路径,并设置运行用户权限,确保Hadoop进程具备必要执行能力。
vi hadoop-env.sh
#################
export JAVA_HOME=/opt/module/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
(2)四大核心XML配置文件
- core-site.xml:定义Hadoop核心属性,如HDFS的默认访问地址。
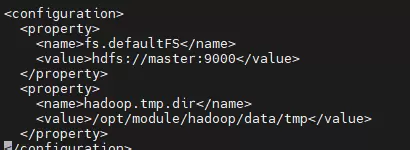
vi core-site.xml
################
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data/tmp</value>
</property>
</configuration>
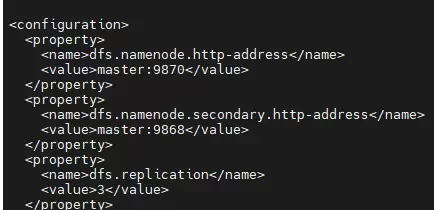
 hdfs-site.xml:配置HDFS相关参数,包括副本数量、数据存储路径等。
hdfs-site.xml:配置HDFS相关参数,包括副本数量、数据存储路径等。
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
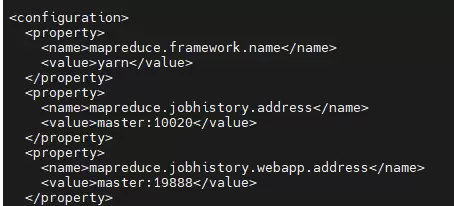
 mapred-site.xml:指定MapReduce框架的运行方式,通常设为YARN模式。
mapred-site.xml:指定MapReduce框架的运行方式,通常设为YARN模式。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
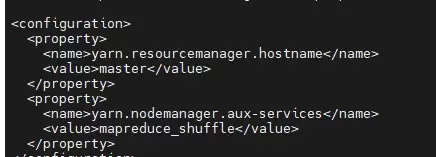
 yarn-site.xml:配置资源调度器YARN的相关参数,如ResourceManager地址等。
yarn-site.xml:配置资源调度器YARN的相关参数,如ResourceManager地址等。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>vi
三、集群启动与状态验证
1. workers文件配置
在Hadoop配置目录下编辑workers文件,删除默认内容,逐行添加所有从节点主机名,用于主节点统一管理。
2. NameNode格式化
首次启动前,必须在主节点执行格式化命令,初始化HDFS元数据存储区域。
hdfs namenode -format
3. 启动HDFS服务
仅需在主节点执行启动脚本,HDFS集群将自动拉起所有相关进程。
start-dfs.sh
4. 启动YARN资源管理器
同样在主节点操作,启动YARN服务以支持分布式计算任务调度。
start-yarn.sh
5. 启动历史服务器
在master节点上单独启动JobHistoryServer,用于记录和查询已完成的任务日志。
mapred --daemon start historyserver
6. 进程状态检查
使用jps命令分别在主节点和从节点查看Java进程列表,确认关键守护进程均已正常运行。
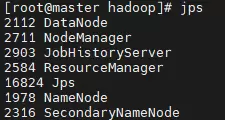
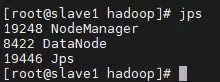
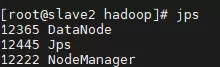
至此,Hadoop集群已成功搭建并投入运行,可进行下一步的数据处理与应用开发。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





