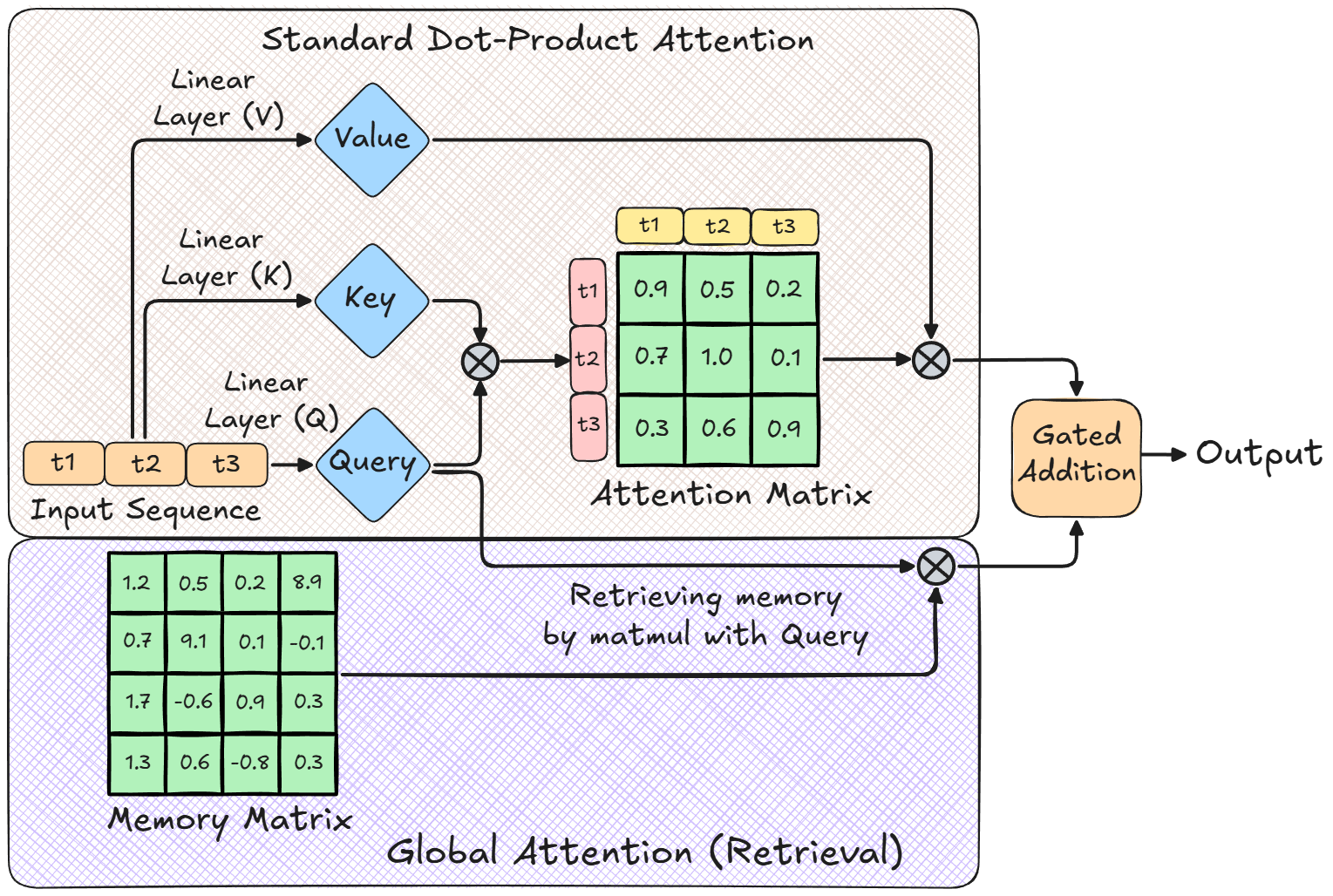
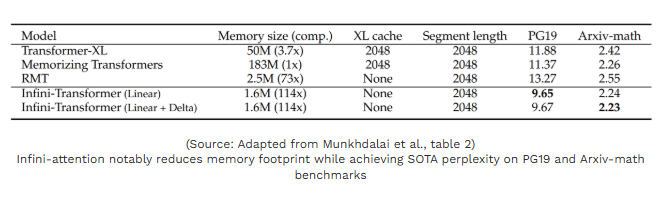
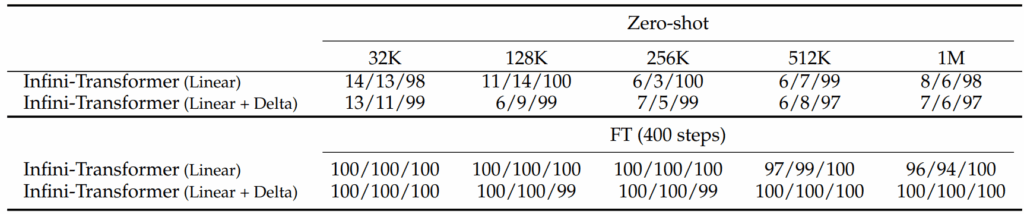
无限注意力(核心论文):Munkhdalai, T., Faruqui, M., & Gopal, S. (2024). Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention. arXiv preprint arXiv:2404.07143.(《不遗漏任何上下文:基于无限注意力的高效无限上下文Transformer》,arXiv预印本)
Transformer-XL:Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. arXiv preprint arXiv:1901.02860.(《Transformer-XL:突破固定长度上下文的注意力语言模型》,arXiv预印本)
记忆Transformer:Wu, Y., Rabe, M. N., Hutchins, D., & Szegedy, C. (2022). Memorizing Transformers. arXiv preprint arXiv:2203.08913.(《记忆Transformer》,arXiv预印本)
线性注意力(数学基础):Katharopoulos, A., Vyas, A., Pappas, N., & Fleuret, F. (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. International Conference on Machine Learning.(《Transformer本质是RNN:基于线性注意力的快速自回归Transformer》,国际机器学习大会)
BookSum基准测试集:Kryściński, W., Rajani, N., Agarwal, D., Xiong, C., & Radev, D. (2021). BookSum: A Collection of Datasets for Long-form Narrative Summarization. arXiv preprint arXiv:2105.08209.(《BookSum:长篇叙事摘要数据集合集》,arXiv预印本)
标准注意力机制:Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).(《注意力就是一切》,神经信息处理系统进展,2017年)
增量规则:Schlag, Imanol, Kazuki Irie, and Jürgen Schmidhuber. “Linear transformers are secretly fast weight programmers.” International conference on machine learning. PMLR, 2021.(《线性Transformer本质是快速权重编程器》,国际机器学习大会,PMLR出版社,2021年)


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏