 图片来源:Alain Pham(Unsplash)
图片来源:Alain Pham(Unsplash)
在最近一个构建倾向模型以预测客户潜在购买行为的项目中,我遇到了许多次之前见过的特征工程问题。
这些挑战大致可分为两类:
团队生成的特征定义、血缘关系和版本未得到系统跟踪,从而限制了特征复用和模型运行的可复现性。
特征逻辑在独立的训练和推理脚本中手动维护,导致训练和推理过程中出现特征不一致的风险(即训练-服务偏差)。
特征以扁平文件(如CSV)形式存储,缺乏模式校验,且不支持低延迟或可扩展访问。
处理时间序列数据时,通常会产生繁重的特征工程工作量,需要计算多个基于窗口的转换操作。
当这些计算按顺序执行而非针对并行执行进行优化时,特征工程的延迟会显著增加。
在本文中,我将清晰解释生产级机器学习(ML)管道中用于特征工程的特征存储(Feast)和分布式计算框架(Ray)的概念及实现方法。
目录
(1) 示例用例
(2) 理解Feast和Ray
(3) Feast和Ray在特征工程中的作用
(4) 代码演练
相关GitHub仓库可在此处获取。
(1) 示例用例
(i) 目标
为了展示Feast和Ray的功能,我们的示例场景涉及构建一个机器学习管道,用于训练和部署一个30天客户购买倾向模型。
(ii) 数据集
我们将使用UCI在线零售数据集(CC BY 4.0许可),该数据集包含2010年12月至2011年12月期间一家英国在线零售商的购买交易记录。
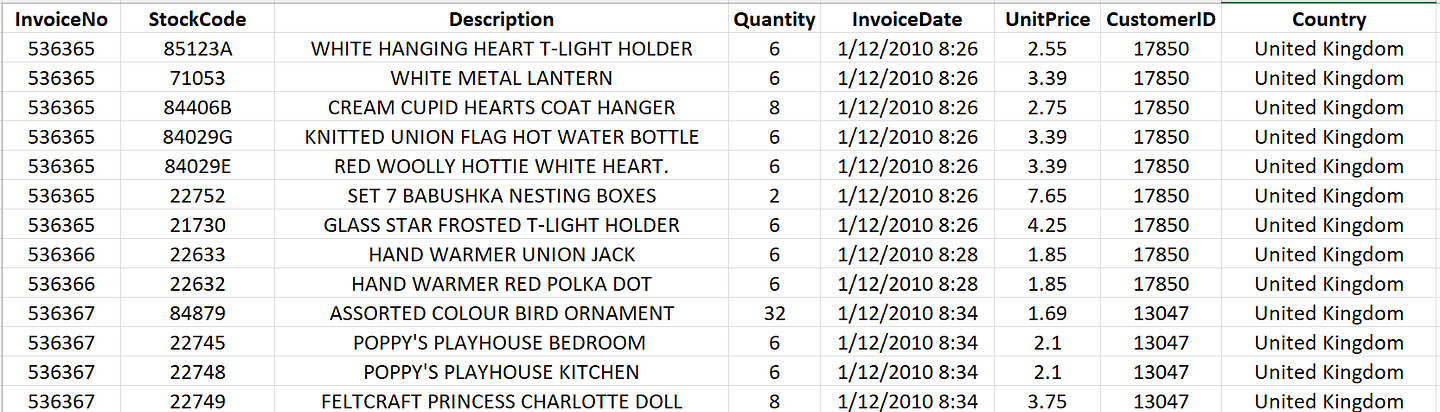 图1 — UCI在线零售数据集的样本行 | 图片由作者提供
图1 — UCI在线零售数据集的样本行 | 图片由作者提供
(iii) 特征工程方法
为简化特征工程范围,我们将特征限制为以下几类(除非另有说明,否则基于90天回溯窗口计算):
近度、频率、货币价值(RFM)特征
tenure_days:首次购买至今的天数(全时段)
客户行为特征
n_unique_products:产品多样性(购买的不同产品数量)
avg_days_between_purchases:平均两次购买间隔天数
(iv) 滚动窗口设计
特征从每个截止日期前的90天窗口计算得出,购买标签(1=至少有一次购买,0=无购买)从每个截止日期后的30天窗口计算得出。
由于截止日期每隔30天设置一个,因此从数据集中会生成9个快照:
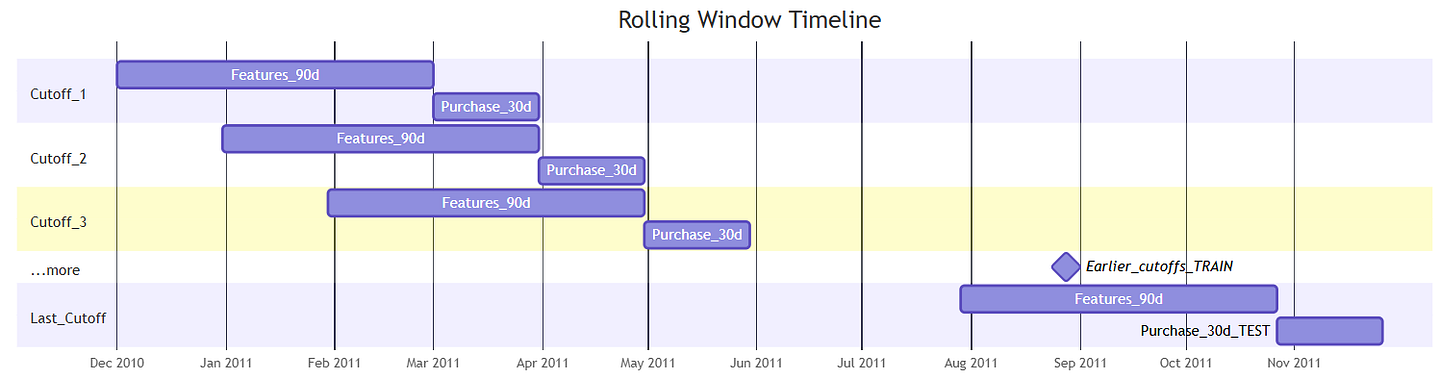 图2 — 特征生成和预测标签的滚动窗口时间线 | 图片由作者提供
图2 — 特征生成和预测标签的滚动窗口时间线 | 图片由作者提供
(2) 理解Feast和Ray
(i) 关于Feast
首先,我们来理解什么是特征存储。
特征存储是一个集中式数据仓库,用于管理、存储和提供机器学习特征,作为训练和服务的单一事实来源。
特征存储在管理特征管道方面具有以下关键优势:
通过确保特征仅使用预测时可用的数据(即时间点正确的数据)防止数据泄露
Feast(全称为Feature Store,特征存储)是一个开源特征存储,能够在训练和推理过程中大规模提供特征数据。
它可与多个数据库后端和机器学习框架集成,适用于各种云平台或非云环境。
 图3 — Feast架构。注意:用于特征工程的数据转换通常位于Feast框架之外 | 图片使用遵循Apache License 2.0许可
图3 — Feast架构。注意:用于特征工程的数据转换通常位于Feast框架之外 | 图片使用遵循Apache License 2.0许可
Feast同时支持在线(用于实时推理)和离线(用于批量预测)两种模式,但我们的重点是离线特征,因为批量预测与我们的购买倾向用例更相关。
(ii) 关于Ray
Ray是一个开源的通用分布式计算框架,旨在将机器学习应用从单台机器扩展到大型集群。它可在任何机器、集群、云提供商或Kubernetes上运行。
Ray提供多种功能,我们将使用的是其核心分布式运行时——Ray Core。
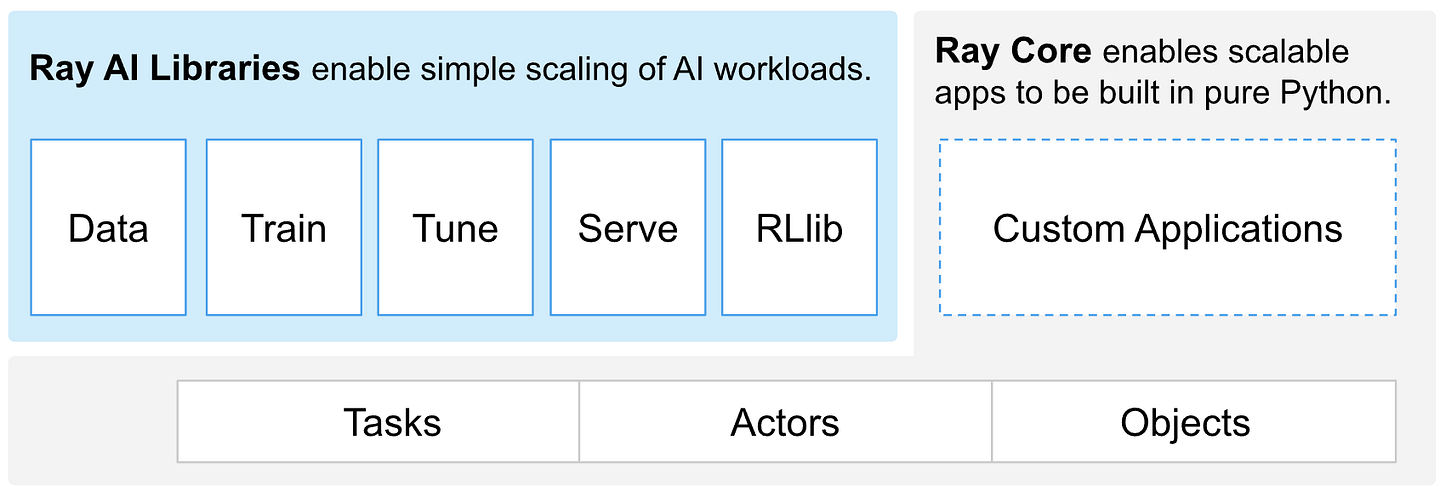 图4 — Ray框架概述 | 图片使用遵循Apache License 2.0许可
图4 — Ray框架概述 | 图片使用遵循Apache License 2.0许可
Ray Core提供低级原语,用于将Python函数作为分布式任务并行执行,并在可用计算资源之间管理任务。
(3) Feast和Ray在特征工程中的作用
让我们看看Feast和Ray在解决特征工程挑战方面的应用场景。
(i) 使用Feast设置特征存储
对于我们的用例,我们将使用Feast设置一个离线特征存储。我们的RFM特征和客户行为特征将注册到特征存储中,以便集中访问。
在Feast术语中,离线特征也被称为“历史”特征。
(ii) 使用Feast和Ray检索特征
当我们的Feast特征存储准备就绪后,我们将在模型训练和推理的两个阶段中,从特征存储中检索相关特征。
我们首先需要明确以下三个概念:实体(Entity)、特征(Feature)和特征视图(Feature View)。
实体(Entity):用于检索特征的主键。它基本上是指每一行特征的标识“对象”(例如user_id、account_id等)。
特征(Feature):与每个实体相关联的单个类型化属性(例如avg_basket_size)。
特征视图(Feature View):为某个实体定义一组相关特征,源自一个数据集。可以将其视为一个表,其中主键(例如user_id)与相关特征列相关联。
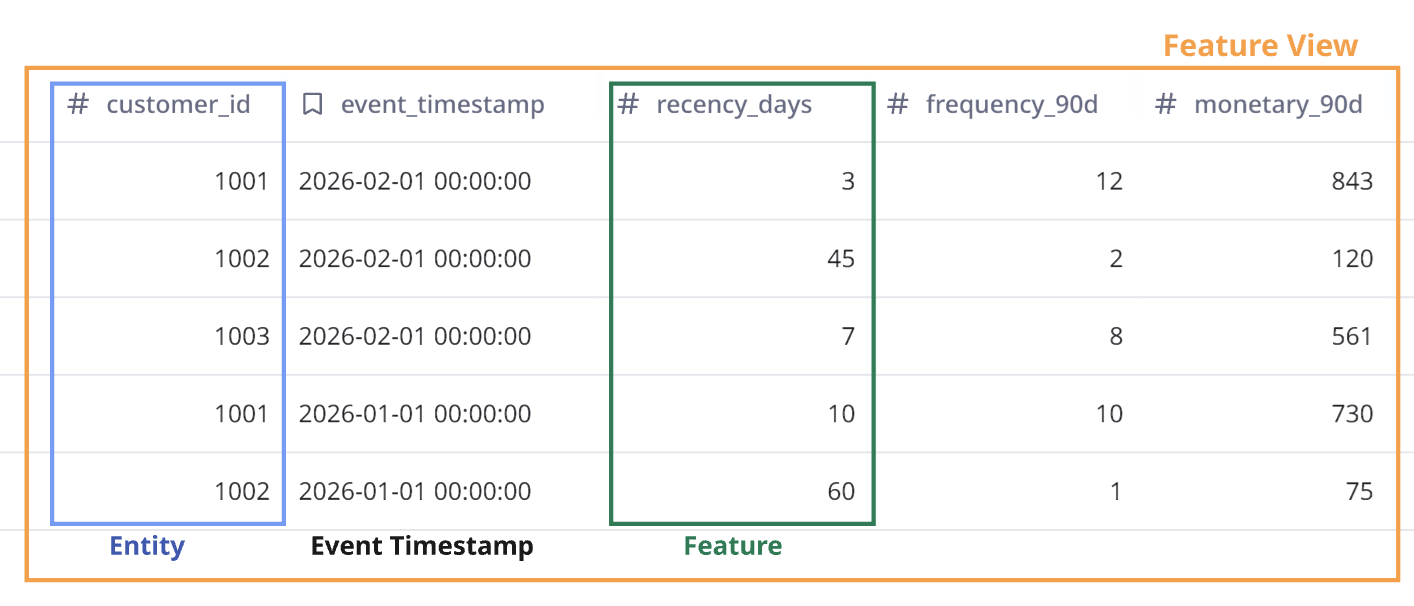 图5 — 实体、特征和特征视图的示例说明 | 图片由作者提供
图5 — 实体、特征和特征视图的示例说明 | 图片由作者提供
事件时间戳是特征视图的重要组成部分,因为它使我们能够为训练和推理生成时间点正确的特征数据。
假设我们现在想要获取这些离线特征用于训练或推理,具体操作如下:
首先创建一个实体数据框(Entity Datafr ame),包含每行的实体键和事件时间戳。它对应于上图5中最左侧的两列。
实体数据框与不同特征视图定义的特征表之间进行时间点正确的连接。
输出结果是一个合并的数据集,包含指定实体和时间戳的所有请求特征。
那么Ray在这里发挥什么作用呢?
Ray离线存储(Ray Offline Store)是一个分布式计算引擎,能够实现更快、更具可扩展性的特征检索,尤其是对于大型数据集。它通过并行化数据访问和连接操作来实现这一点:
数据(I/O)访问:通过将Parquet文件分割到多个工作节点,实现分布式数据读取,每个工作节点并行读取不同的分区。
连接操作:分割实体数据框,使每个分区独立执行时间连接,以检索给定时间戳之前每个实体的特征值。对于多个特征视图,Ray并行化计算密集型连接,实现高效扩展。
(iii) 使用Ray进行特征工程
用于生成RFM和客户行为特征的特征工程函数必须应用于每个90天窗口(即9个独立的截止日期,每个日期都需要执行相同的计算)。
Ray Core将每个函数调用转换为远程任务,使特征工程能够在可用核心(或集群中的机器)上并行运行。
(4) 代码演练
(4.1) 初始设置
我们安装以下Python依赖包:
feast[ray]==0.60.0
openpyxl==3.1.5
psycopg2-binary==2.9.11
ray==2.54.0
scikit-learn==1.8.0
xgboost==3.2.0
由于我们将使用PostgreSQL作为特征注册中心,请确保在运行docker compose up -d启动PostgreSQL容器之前,已安装并运行Docker。
(4.2) 数据准备
除了数据摄入和清洗外,还需要执行两个准备步骤:
滚动截止日期生成:创建9个间隔30天的快照。每个截止日期定义一个训练/预测点,特征从该点之前的90天计算得出,目标标签从该点之后的30天计算得出。
标签创建:为每个截止日期创建一个二元目标标签,指示客户在截止日期后的30天窗口内是否至少有一次购买行为。
(4.3) 运行基于Ray的特征工程
定义生成RFM和客户行为特征的代码后,我们使用Ray对每个滚动窗口的执行过程进行并行化处理。
首先,我们创建一个函数(compute_features_for_cutoff)来封装每个截止日期的所有相关特征工程步骤。
@ray.remote装饰器将该函数注册为远程任务,以便在独立的工作节点上异步运行。
数据准备和特征工程管道的运行过程如下:
以下是Ray在管道中的作用:
ray.init():初始化Ray集群,默认情况下启用跨所有本地核心的分布式执行。
ray.put(df):将清洗后的数据框存储在Ray的共享内存(也称为分布式对象存储)中,并返回一个引用(ob jectRef),以便所有并行任务都能访问该数据框而无需复制。这有助于提高内存效率和任务启动性能。
compute_features_for_cutoff.remote(...):将我们的特征计算任务发送到Ray的调度器,Ray将每个任务分配给一个工作节点进行并行执行,并返回每个任务输出的引用。
futures = [...]:存储每个remote()调用返回的所有引用。它们代表所有已启动的正在运行的并行任务。
ray.get(futures):一次性检索所有并行任务执行的实际返回值。
然后,脚本将每个截止日期的RFM特征和行为特征提取并连接到两个数据框中,将其保存为本地Parquet文件。
ray.shutdown():停止Ray运行时,释放分配的资源。
需要注意的是,在本案例中我们将特征存储在本地,但在生产环境中,离线特征数据通常存储在数据仓库或数据湖(如S3、BigQuery等)中。
(4.4) 设置Feast特征注册中心
到目前为止,我们已经涵盖了特征工程的转换和存储方面。接下来我们转向Feast特征注册中心。
特征注册中心是特征定义和元数据的集中目录,作为特征信息的单一事实来源。
注册中心设置包含两个关键组件:定义(Definitions)和配置(Configuration)。
定义(Definitions)
我们首先定义用于表示迄今为止设计的特征的Python对象。例如,首先需要确定的对象之一是实体(Entity)(即链接特征行的主键):
接下来,我们定义存储特征数据的数据源:
注意,timestamp_field(时间戳字段)至关重要,因为它能确保在检索特征用于训练或推理时,获得正确的时间点数据视图和连接结果。
定义实体和数据源后,我们可以定义特征视图。由于我们有两组特征(RFM和客户行为),因此预计会有两个特征视图:
模式(字段名称、数据类型)对于确保特征数据得到正确校验和注册至关重要。
配置(Configuration)
特征注册中心的配置在一个名为feature_store.yaml的YAML文件中定义:
该配置告知Feast使用哪些基础设施,以及其元数据和特征数据的存储位置,通常包括以下内容:
项目名称(Project name):项目的命名空间
提供商(Provider):执行环境(如本地、Kubernetes、云)
注册中心位置(Registry location):特征元数据存储的位置(文件或PostgreSQL等数据库)
离线存储(Offline store):读取历史特征数据的位置
在线存储(Online store):提供低延迟特征的位置(与我们的用例无关)
在我们的案例中,我们使用PostgreSQL(在Docker容器中运行)作为特征注册中心,并使用Ray离线存储来优化特征检索。
我们使用PostgreSQL而非本地SQLite,是为了模拟生产级别的注册中心设置,以便多个服务可以同时访问注册中心。
Feast Apply(Feast应用)
完成定义和配置后,我们运行feast apply将定义注册并同步到注册中心,并配置所需的基础设施。
该命令可在Makefile中找到:
apply:
cd feature_store && feast apply
(4.5) 检索特征用于模型训练
当我们的特征存储准备就绪后,我们继续训练机器学习模型。
首先,我们创建用于检索的实体主干(即customer_id和event_timestamp两列),Feast使用它来检索正确的特征快照。
然后,我们在运行时执行特征检索以用于模型训练:
FeatureStore:Feast对象,用于在运行时定义、创建和检索特征。
get_historical_features():专为离线特征检索设计(与get_online_features()相对),它需要实体数据框和要检索的特征列表。特征数据的分布式读取和时间点连接在此处进行。
(4.7) 检索特征用于推理
最后,我们使用训练好的模型生成预测结果。
用于推理的特征检索代码与训练时的代码大致相同,因为我们正受益于一致的特征存储。
主要区别在于使用的截止日期不同。
总结
特征工程是构建机器学习模型的重要组成部分,但如果处理不当,会引入数据管理挑战。
在本文中,我们清晰展示了如何使用Feast和Ray来改进特征工程的管理、可复用性和效率。
理解并应用这些概念,将使团队能够构建具有可扩展特征工程能力的高效机器学习管道。
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





