你的科研焦虑,不止于"没数据"
扎心数据:
- 中国知网调研显示,人文社科研究者平均花费43%时间收集数据,却用不足10%的时间做深度分析
- 更残酷的现实:某C9高校统计,会爬虫的研究者中,68%仍停留在"词频统计+词云图"的浅层分析
- 某985高校调研发现,76%的研究生因"不会编程"被迫放弃大数据研究选题
- 传统人工采集5000条评论数据需要2周,而会爬虫的同行只需2小时
- 被质问:"爬了10万条评论,就给我看这个?"——数据在手,洞察难求
这些场景是否正在折磨你:
- 千辛万苦爬来数据,只会用Excel数词频,分析深度被审稿人质疑?
- 看到顶刊都在用BERT、LDA主题模型,自己连Word2Vec都不会调参?
- 面对非结构化文本(政策文件、社交媒体、财报),不知如何提取结构化洞察?
- 同事用AI做情感分析+知识图谱已经发了CSSCI,你还在手动标注关键词?
破局:2025科研人必备技能升级
国内顶尖高校博导陈老师(北大博士,主持多项国自然项目,发表SCI/EI论文100+篇)2026重磅升级:
【Python师资培训-AI助力Python爬虫与文本分析】实战班
不是简单的Python课,而是AI时代的科研效率革命!
爬虫是手段,分析才是目的!
16大模块双核驱动,让你既会"采金矿",更会"炼黄金"!

为什么这门课能解决你的焦虑?
你的痛点
| 课程解决方案 |
| 零基础怕编程 | 从HTTP原理到DeepSeek代码生成,手把手教学 |
| 反爬机制搞不定 | 掌握Selenium/Playwright/验证码识别全套路 |
| 爬下来的数据不会分析 | 覆盖分词、情感分析、LDA主题模型到BERT深度学习 |
| 传统方法太慢 | AI大模型辅助:自动生成爬虫代码、一键文本分类、零样本学习 |
课程信息:
时间: 2026年5月1—4日(四天)
形式: 北京现场班,同步线上直播;提供录播回放+ 配套资料 + 老师答疑
适合人群: 高校师生、科研人员、数据分析师、产业研究从业者
早鸟福利:增送价值1300元Python师资培训-编程基础与数据清洗15+小时线上课程,报名后即可开通学习
课程双核心架构:爬虫+文本分析 并重实战
| 模块 | 核心技能 | 解决什么焦虑 |
| 爬虫 | AI辅助代码生成、反爬对抗、分布式抓取 | 告别手动复制,2小时搞定别人2周的工作量 |
| 文本分析 | 从TF-IDF到BERT,从主题模型到知识图谱 | 让数据"说话",产出顶刊级别的深度洞察 |
讲师实力背书:
国内顶尖高校博导陈老师
- 北京大学博士&优秀博士后,发表论文100+(第一作者60+)
- 主持国家自然科学基金面上项目、国家重点研发计划课题
- 授权国家发明专利20+项,国自然函评专家
- 深谙学术痛点:懂科研、懂数据、更懂如何让技术为研究赋能
- 深谙科研全流程:从数据获取到深度分析,从方法选择到论文写作,手把手带你避坑
- 与JG学术培训独家合作Python师资培训以来受到了广泛好评
课程核心亮点(16大模块,24小时干货):
Part1:爬虫技术全栈
- 静态/动态页面抓取(Requests/BeautifulSoup/Xpath)
- 反爬对抗实战:模拟登录、IP代理池、验证码识别(OCR+云识别)
- 分布式爬虫架构(Scrapy框架)
- AI辅助爬虫:自然语言描述需求,AI自动生成可运行代码
Part2:文本分析从入门到精通
- 传统方法:TF-IDF、Word2Vec、TextRank关键词提取
- 深度学习:RNN/LSTM/TextCNN/BERT模型实战
- AI辅助文本分析:
- 文本嵌入特征提取 → 分类/回归/聚类
- 零样本分类(无需标注数据!)
- 知识图谱自动构建
- 领域大模型微调(法律/医疗/金融文本专属模型)
40+实战案例覆盖:
- 知网论文爬取、微博舆情分析、京东商品评论挖掘、豆瓣情感分析、年报数据提取、法律文本知识图谱...
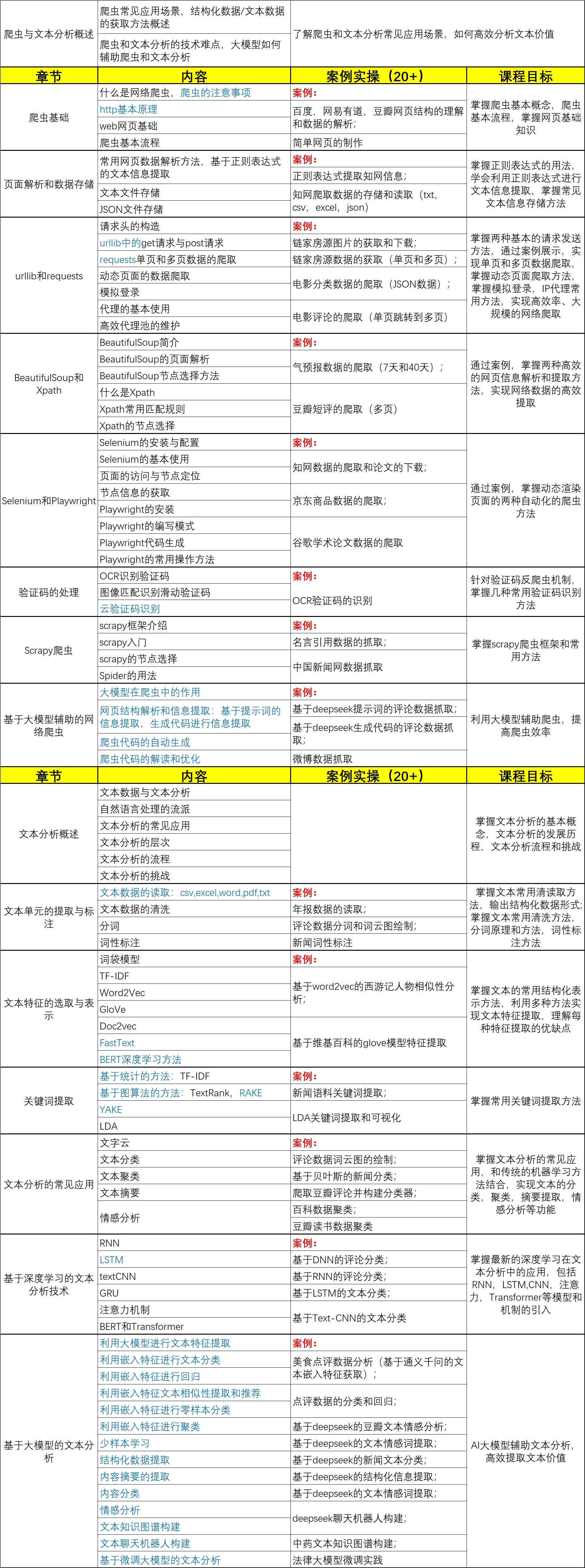
课程大纲:
科研竞争已进入"AI辅助"时代,
不会用AI的Python学术实战就像不会用知网查文献——不是能不能做的问题,是效率被碾压的问题!
立即咨询占座:获取早鸟福利
尹老师
电话:13321178792
QQ:42884447
WeChat:JGxueshu

主办单位:经管之家官方学术培训品牌JG学术培训
爬虫是船,分析是桨。没有桨的船,只能随波逐流。AI时代,做驾驭数据的掌舵人!


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏