经管之家App
让优质教育人人可得
立即打开


本文英文版: https://github.com/zartbot/blog/issues/9
昨天NVidia发布了Groq 3 LPU和对应的LPX ComputeTray. 并且但是我们也发现了这一次GTC完全没有讲Rubin CPX了, 这背后的逻辑是什么? 从供应链紧张时各种物料平衡的角度如何来看待问题? 异构的AFD如何实现的, 片上SRAM如何放置那些参数超过1T的大规模MoE模型? 整体的性能收益如何? 互连结构是如何的?
话说那颗互连的FPGA用到了很多年前做的NetDAM的一些技术, 也是我在写《谈谈那个被NV看上值20B的Groq》这篇文章的时候提到的, 后面我会详细展开说说这个事情, 话说Jensen是不是得付一下钱?

本文目录如下:
对于Groq的微架构, 我们在文章《谈谈那个被NV看上值20B的Groq》有过详细介绍, 这里稍微展开一下 Groq 一直强调的确定性执行相关的话题.
传统的HPC系统和多核心CPU/GPU架构在内存和网络资源上存在动态共享和竞争, 导致不确定性(non-determinism),GPGPU的内存层次结构看上去太厚了, 虽然某种层度上降低了编程的一些复杂度, 但是很多时候还是面临一些不可控的因素. 不确定性的来源主要包含几个方面:
这对于一个超大规模的机器学习系统来说构成了一个巨大的挑战. 这种不确定性使得精确的并行协调变得非常困难. 在需要紧密耦合的并行任务中, 处理器A不知道处理器B的数据何时能到, 只能通过昂贵的同步机制(如屏障, 锁)来等待, 造成大量时间浪费. Groq认为, 与其在不确定的系统中通过复杂的软件来"管理"不确定性, 不如从硬件层面就构建一个确定性的系统.
Groq的解决方案: 其核心是将单个TSP芯片内部的确定性(determinism), 通过一套精心设计的软硬件机制, 扩展到整个由数千个TSP组成的系统. 确定性执行包括如下两个方面:
这也是我一直在强调整个系统建模的时候, Little‘s Law和Kingman公式的重要性. Kingman’s公式是排队论中对于一个通用的单服务器队列模型 G/G/1, 其平均队列延迟为:
其中为到达速率, 为服务速率,即平均服务时间的倒数, 为系统的使用率. 为到达时间的变异系数,为服务时间的变异系数. 变异系数CV为标准差除以均值. 然后我们可以根据然后取不同的变异系数做出一个图来.
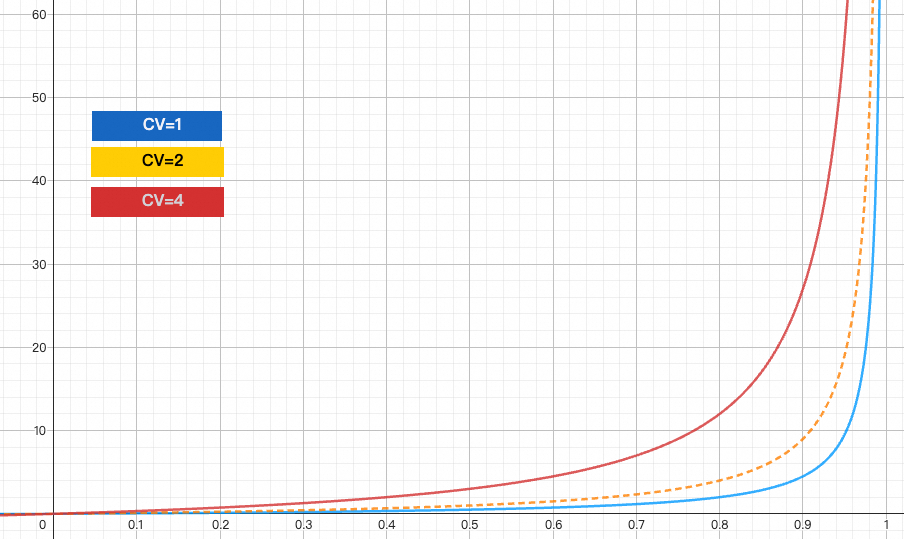
我们注意到为了使整个系统的平均服务等待时间变短, 那么就需要进一步去降低网络和计算的变异系数(,). 这对于模型的EP并行是非常有必要的. 后面我们将详细展开分析.
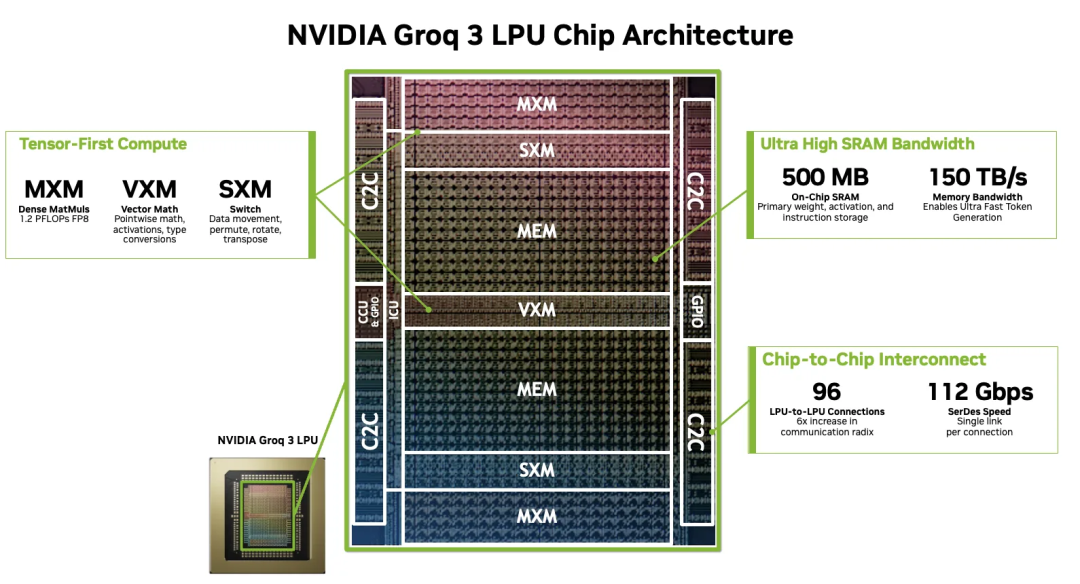
Groq 3的芯片架构如下图所示:
好奇的你一定会问怎么突然到第三代了? 和前两代的架构有什么区别呢?
整个芯片依旧是延续Groq的确定性执行微架构, 包含MXM(矩阵乘法单元), VXM(向量计算单元), MEM(内存功能单元)和SXM(数据交换单元).
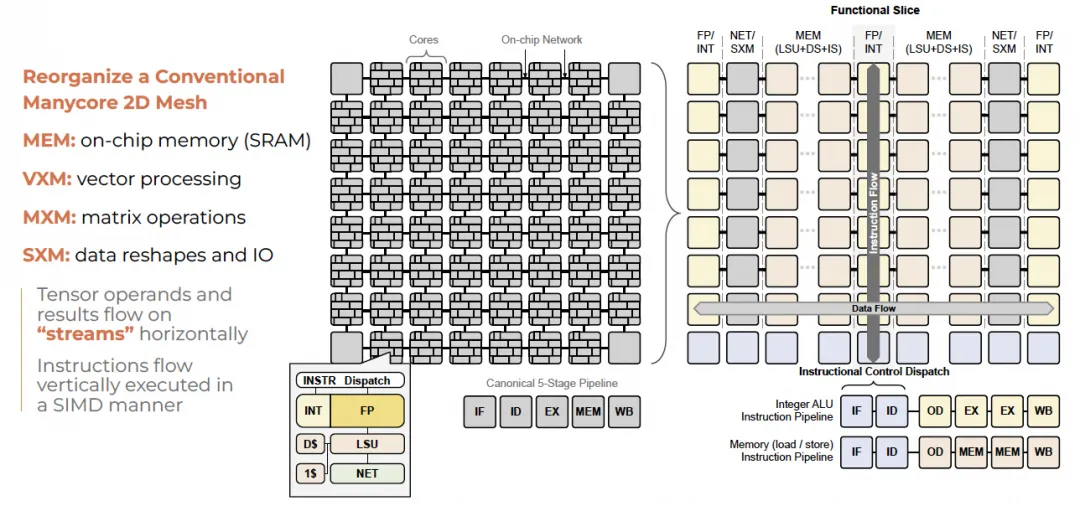
MXM-SXM-MEM-VXM单元构成了一个pipeline, 通常这个流水线被称为一个SuperLane. 然后数据流只在东西向并行执行. 在南北方向构成一个并行的SIMD向量执行.

在第一代Groq的架构中, 每块芯片有220MB的SRAM, 然后构成一个有80TB/s带宽的Scratchpad Memory. 第二代芯片没有具体的数据, 但是我们看到Groq曾经透露过, 主要还是扩大芯片互连的Serdes数量, 并尝试在构建ScaleUP机柜.

在第三代中, 相对于第一代, SRAM的容量和带宽都增加了, 支持500MB的SRAM容量并支持150TB/s的带宽. 大概的估计是从第一代320B的VectorSize提升到了768B, 然后频率可能伴随着NV能够拿到更先进的工艺也有所提升.
从互连上分析, Groq 3 支持了96个Chip-to-Chip互连的接口, 采用了112G Serdes. 也就是说单卡支持10Tbps单向的带宽, 然后整个ComputeTray 8卡, 按照内存带宽双向计算也就是Datasheet中标注的ScaleUP 20TB/s带宽. 整个ComputeTray的架构如下:

对于现场实物照片的标注如下:

ComputeTray内部的互连结构猜测如下:
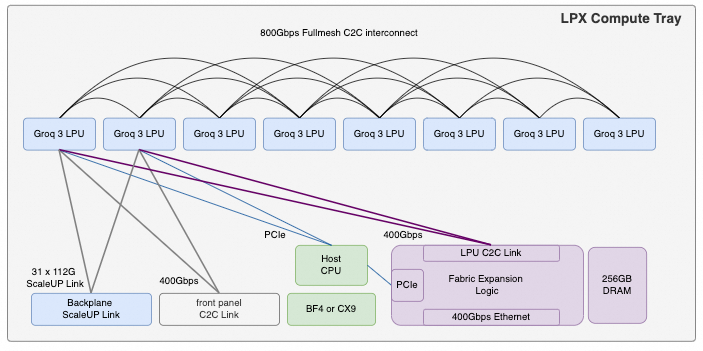
整个LPX机柜支持32个ComputeTray. 因此每个Groq 3 LPU 需要提供31个C2C Link连接其它的Tray. 然后在ComputeTray内部需要800Gbps的Fullmesh连接, 则需要使用56个C2C Link. 前面板预留了32个LPU C2C link用于多个LPX机柜之间的互连, 平均每个LPU 提供了4个C2C Link(400Gbps). 而剩下的4个C2C Link(400Gbps)则用于连接Fabric Exapansion Logic那块FPGA. 然后LPU和Fabric Expansion Logic需要PCIe作为控制链路连接到Host CPU. 另外一个BF4 DPU 或者CX9 用于连接其它FrontEnd网络.
这种互连方式也符合Groq 使用Dragonfly拓扑的特征, 对于单颗Groq 3 LPU而言, 有5.6Tbps带宽用户ComputeTray内部的Fullmesh连接, 3.1Tbps用于整个Rack-Level的互连, 400Gbps用于跨Rack互连, 剩下400Gbps用于连接Fabric Expansion Logic.
下面是ComputeTray的详细DataSheet:
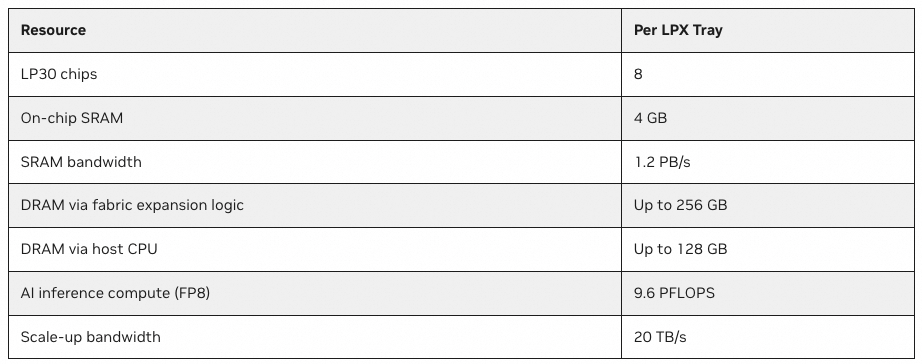
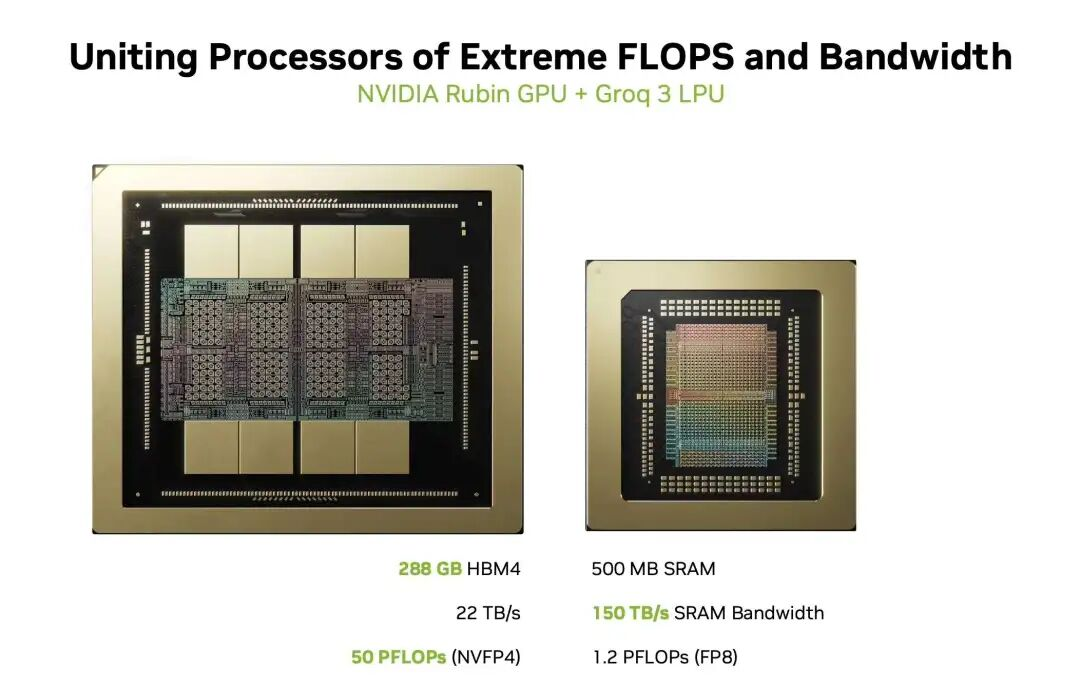
由于每颗芯片的FP8 算力为1.2PFLOPS, 单个ComputeTray算力为9.6PFLOPS. 然后单颗Groq 3 LPU SRAM为500MB(带宽150TB/s), 因此累计8颗为4GB(带宽1.2PB/s). 需要注意的是Fabric Expansion Logic支持256GB DRAM, 这对于支持超过1T参数的模型AFD是必须的, 具体的作用我们将在稍后的章节详细介绍这颗芯片.
对于Scale-UP的带宽为20TB/s, 它是按照单颗芯片96个112Gbps C2C Link来计算的,即单芯片单向 10Tbps, 双向20Tbps. 8颗芯片累计为20TB/s.
整个机柜包含 32 个ComputeTray, 猜测背板采用CableTray来连接多个ComputeTray,并且仅使用112G Serdes难度应该低于Oberon机柜的CableTray.

然后我们来仔细计算一下这些Datasheet, 单个ComputeTray FP8算力为9.6PFlops, 因此累计整个机柜32个Tray应该为307PFLOPS. 但是官方的宣传为 315PFLOPS, 那么还有8PFLOPS是从哪儿来的? 单个ComputeTray SRAM容量为4GB,带宽为1.2PB/s, 累计整个机柜为128GB, 累计带宽为38.4PB/s, 按照40PB/s倒推每个ComputeTray应该为1.25PB/s, 这些数据有些不匹配的情况, 希望Nvidia能够改正一下.
累计整个机柜256颗LPU为128GB, 但是累计带宽应该为 38.4PB/s, 对于Scale-UP Bandwidth的计算为简单按照单个ComputeTray 20TB/s * 32得到的.
在2025年12月末, 我曾经详细分析过Nvidia收购Groq后如何整合它的技术, 期间也谈到了我 5 年前的一个工作 NetDAM, 对于 NetDAM 的狭义定义就是 Network Direct Attached Memory, 也就是说将 Memory 通过ASIC直接Attach在以太网控制器上就属于这个范畴. 而Nvidia 这颗 Fabric Expansion Logic也确实这么做了, 对比一下两颗芯片的结果如下:
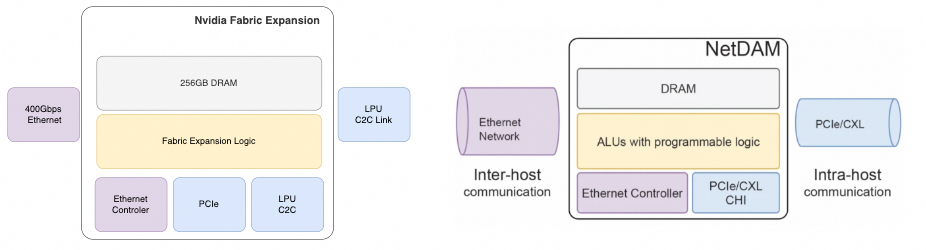
实质上Nvidia 这颗芯片就是完全使用了 NetDAM 几年前的技术. 如果说连接到其它的处理器上而不是标准的PCIe/CXL是两者的区别, 其实NetDAM早就 claim 了直接连接各种芯片.
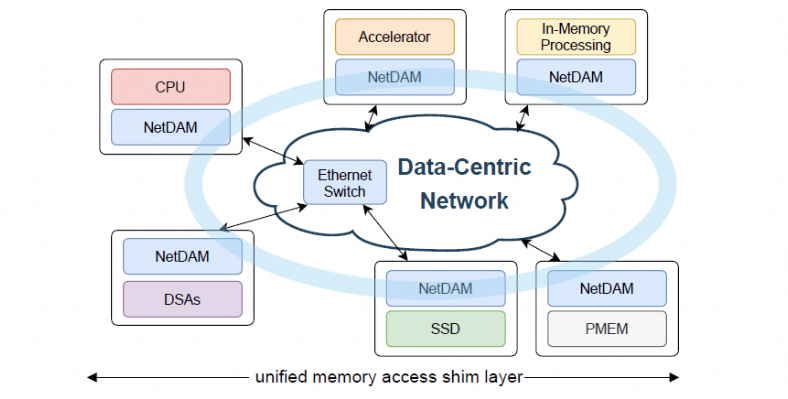
Jensen要不要给我充个值呢?
回到正题, 为什么Nvidia 需要在LPX ComputeTray上放置这块芯片作为 Fabric 扩展使用呢? 首先整个 Groq 的处理域是一个确定性执行的, 而网络通常受到拥塞和延迟/抖动的影响. 正如 NetDAM 论文所讲, 在 Host 边界需要提供一个“大坝(Dam)”来吸收inter-host的突发和抖动, 并给内部提供确定性的内存访问.
具体如何使用这颗芯片, 我们将在稍后的章节介绍AFD的时候展开.
首先, 您肯定要有这样的疑问, 既然GPU已经是异构加速计算了, 为什么还要进一步使用一颗异构的Groq LPU?
首先我们需要对整个 workload 进行详细的分析, 特别是Agentic LLM推理的workload.
现在的Agentic LLM通常是你给它一个复杂任务, 比如"帮我写个爬虫程序抓取天气数据", 它会自己上网查资料、写代码、运行代码、调试错误, 这个过程需要来来回回几十甚至上百步. 尽管每个单独工具调用或者反馈都很短(通常数百个Token), 但是上下文会逐轮累积, 并增加到极长的长度. 也就是说整个agentic LLM的工作特征是Context长度通常很长(>100K), 并且需要多轮交互, 每次交互过程如下:
随着Context在多轮交互中越来越长, 实际上它会对内存容量有更高的需求, 因此我们也可以认为该阶段是一个Memory Capacity Bound 的约束. 当然Prefill阶段本身也是一个Compute Bound的运算过程.
在Decoding阶段, Attention相关的计算依旧需要需要维持整个Context, 因此同样有Memory Capacity Bound 的约束. 由于内存容量的约束, 通常很多操作在很小的batchsize下运行, 并且在MoE阶段, 通常一个 token 需要 8 个Expert参与运算, Expert参数加载这些操作也会带来巨大的内存访问. 因此这个阶段也是一个Memory Bandwidth Bound的过程.
总体来看:
另一方面, 传统的 TPS SLO 是针对聊天场景人的阅读速度而定的. 对于Agent执行它仅需很短的时间读取模型返回的tool call调用, 因此多轮交互场景中我们需要显著提高 Decode 阶段的 TPS 才能加速Agent的整体执行时间. 也就是说对于AI Factory的 SLO 要求是既需要整体的高吞吐(TPS per MW), 也需要每个用户更高的TPS(TPS per User).
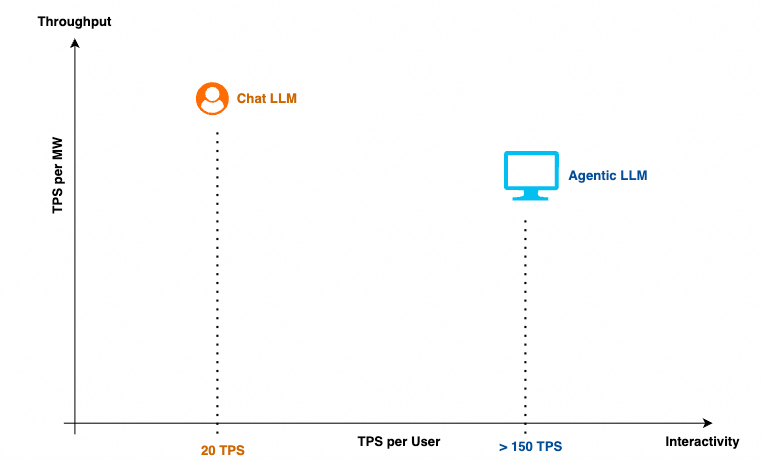
这里我们稍微展开解释一下Agent为什么需要高的per-user TPS. 假设TTFT为3s, 通常Agent每轮执行的时间为100ms, 如果TPS = 20, 通常我们按照Decode需要500个token计算, 则Decode的时间为 25s. 如果一个Agent任务需要10轮, 则整体的执行时间为( 3 + 25 +0.1) * 10 = 281s. 如果TPS = 100, 则Decode时间为 5s 整体执行时间为 81s. 因此100TPS或者150TPS将成为Agent LLM的SLO最低要求. Nvidia的Blog也谈到了这个问题:
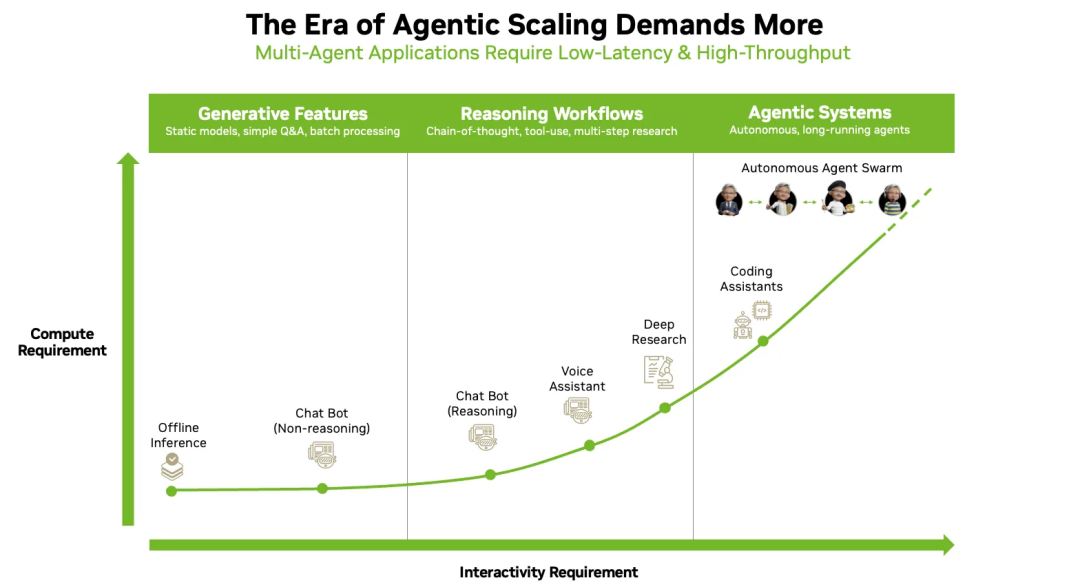
如果全部用基于HBM的Rubin GPU, 通常需要考虑到GPU的效率, 特别是在Decoding阶段由于BatchSize较小导致GEMM运算效率较低的问题, 通常会以牺牲一些per-session 延迟为代价, 用相对较高的batchsize来获得更高的吞吐. 而这种代价对于Agentic LLM是无法满足的. 当然我们可以用很低的batchsize来为需要极致TPS的用户提供服务, 但是由于整体吞吐很低导致AI Factory 成本极高, 这些成本需要转嫁给用户.
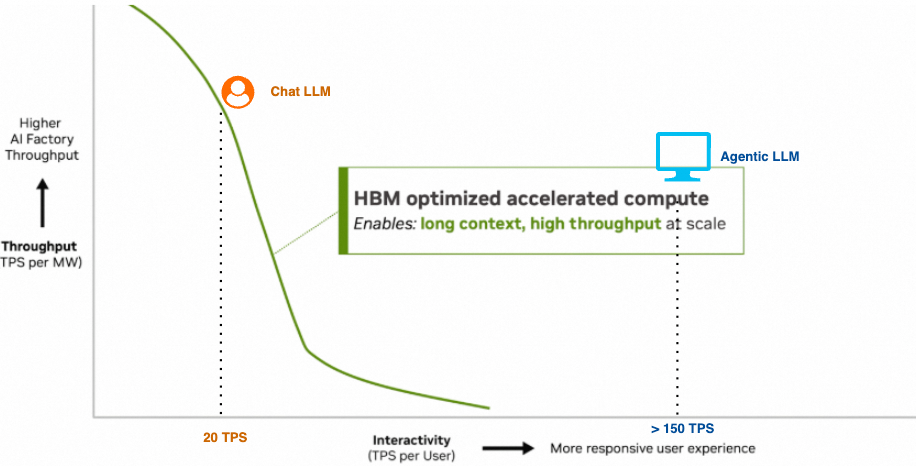
如果全部用基于SRAM的Groq LPU, 虽然这类处理器可以做到 per-session 极低的推理延迟(输出超过1000TPS), 但是基于SRAM的整个系统内存容量是受限制的, 因此整个系统的并发能力较差, 吞吐上依旧不满足AI Factory的需求.
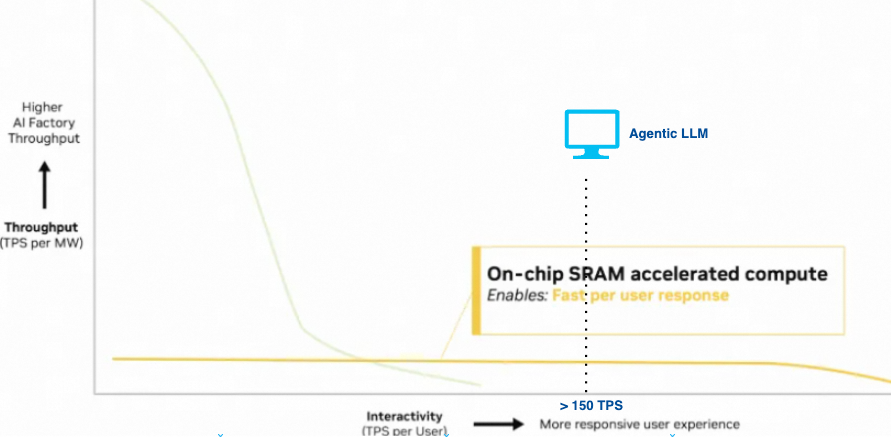
我们来充分对比两种芯片的特征: Rubin具有更高的算力和更大的内存容量, Groq具有更大的内存带宽.
一个很自然的想法就是, 如何结合两种芯片. Rubin 的大算力和大容量HBM可以解决Prefill的约束, 同时HBM的内存容量和算力解决Decoding阶段的Attention计算也是没有问题的. 而对于Decoding阶段的FFN 让具有更大带宽的Groq 3 LPU处理. 如图所示:
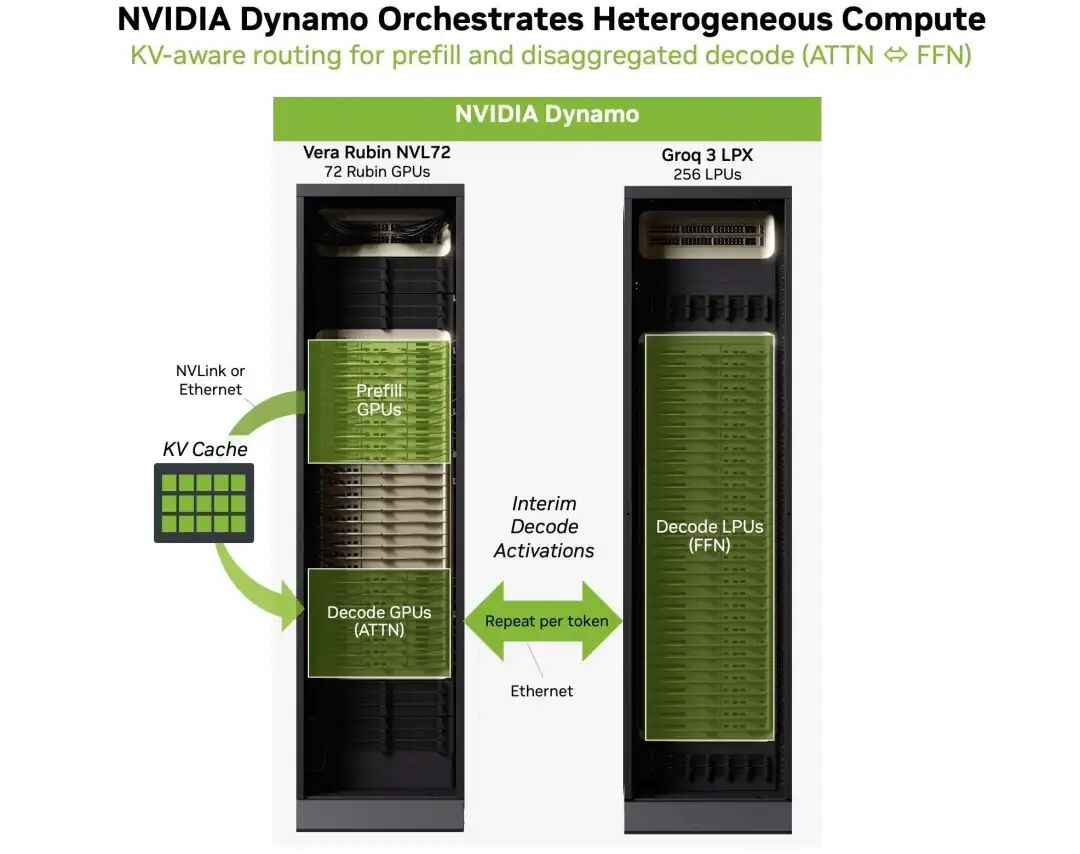
这样的配合方式理论上可以显著提升性能, 如下图所示:
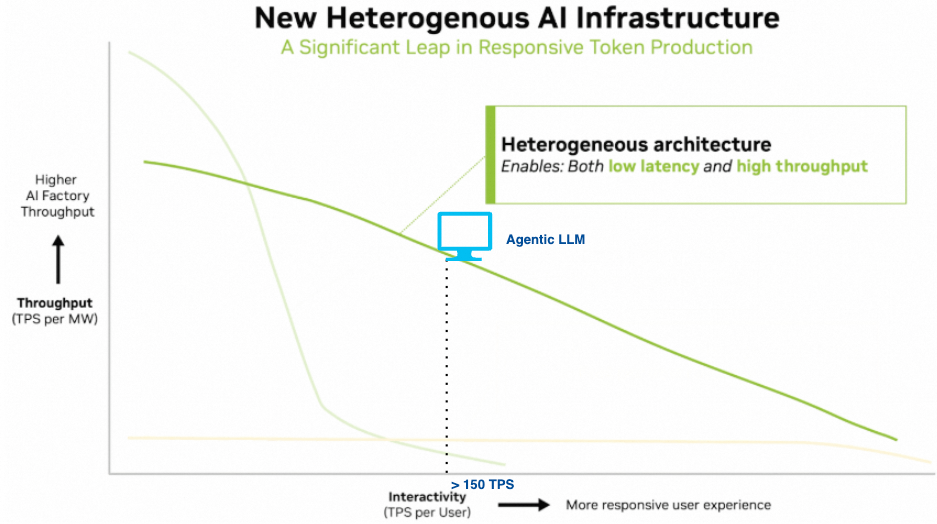
但是我们注意到这是一种理论上的Trade-off, 实际的性能收益如何呢?
Nvidia官方博客只写了一个简单的AFD图:
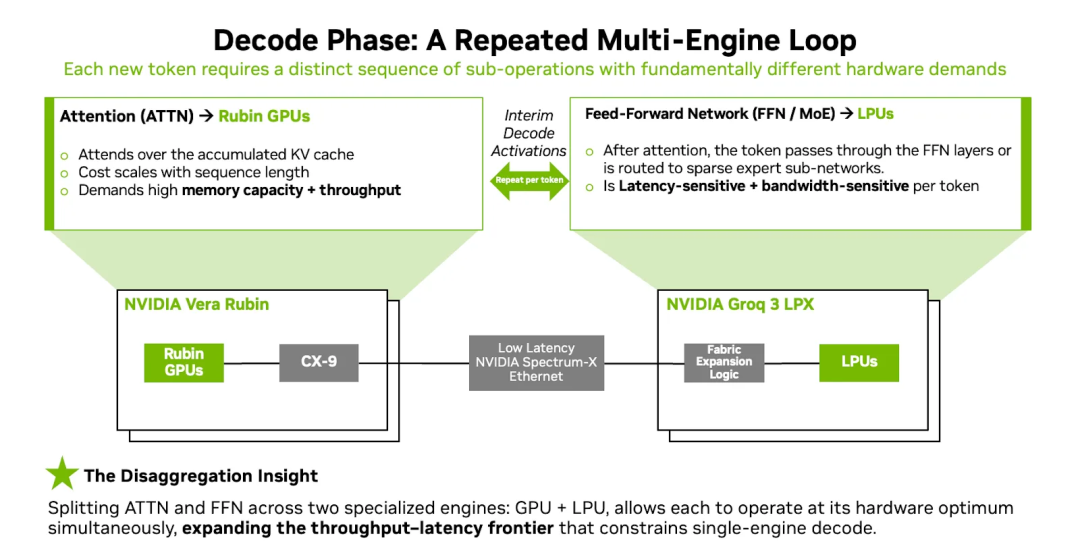
我们以DeepSeek-V3的MoE为例, 单个专家有44.05M个参数, 按照FP8计算即44.05MB, 每层有256个路由专家和1个共享专家, 累计 58 层, 总参数需要 656.6GB, 如果单纯的按照Groq 3 LPU的SRAM来计算, 单个机柜 128GB 是无法放置一些超过 1T 参数的 MoE 模型. 因此一些做网络的同学普遍的观点是需要10个机柜2560卡才能存放这么多专家的参数. 然而解决这个问题的关键在Fabric Expansion Logic 上的256 GB DRAM.
然后我们来估计一下单个专家的计算时间, 由于受到Groq 3 算力1.2PFLOPS 和 SRAM 带宽 150TB/s的约束, 这个算子又是Memory Bandwidth Bound的, 那么总数据量为264MB, 访问内存的延迟为1.68 us. 也就是说整个算子的计算时间大概为2us.
Groq 3上有一个用于缓存token的FIFO, 如下图所示图片
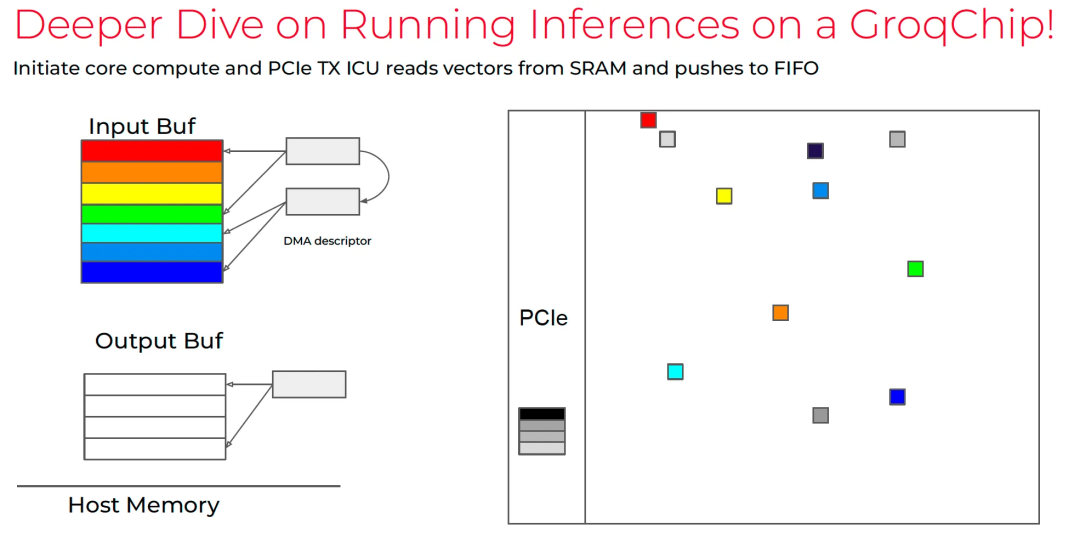
整个数据交互流程如下:
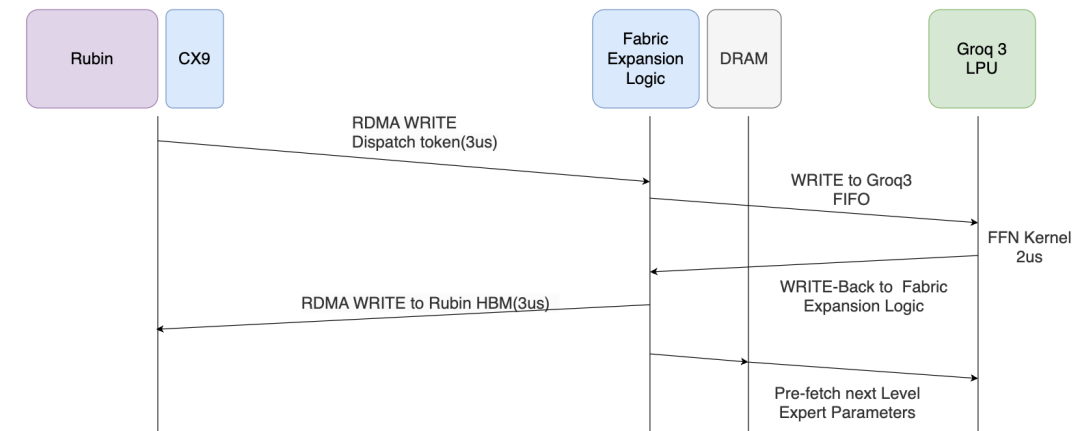
首先Rubin需要通过 IBGDA 去 dispatch token 到Groq 3上的FIFO. 在这里必须要使用IBGDA, 因为如果使用IBRC延迟会更高, 这里我们假设一个很理想的情况传输仅需要3us, 然后是Groq 3 LPU 计算时间2us, 数据返回写入Rubin也需要3us. 整个过程大概10us左右.
接下来我们讨论一下EP策略, 由于一个LPX机柜有256个Groq 3 LPU, 因此可以做到EP-256. 对于Shared Expert可以在Rubin上自己计算. 其实这里对于Expert Loadbalance还有一些考虑, 可能某些Expert的计算时间还需要加上 Groq 3 LPU 的 Serving 队列时间. 我们此时假设一个最优的全流程时间为15us, 并且假设在Groq内部我们还可以用其中几块 LPU 来处理Combine的操作, 为了方便计算, 我们假设整个EP通信和FFN计算时间为 20us.
有一个需要特别注意的问题, 此时由于整个计算+通信延迟已经非常低了, 对于网络中潜在的拥塞控制(incast导致的延迟抖动)和Hash冲突导致的延迟抖动需要特别的处理, 否则网络上的抖动会进一步影响到完成时间.
然后我们利用我以前开发的一个工具《ShallowSim》[1]来仿真计算Rubin的MLA计算时间, 由于Expert参数都存到Groq 3 LPU了, Rubin有足够大的内存来存放更长的KVCache. 但是为了更低的延迟, 在Rubin上BatchSize需要更小, 我们以Batchsize = 16为例进行仿真, MLA 算子消耗时间,以及按照61层加上FFN的时间(20us)计算TPS如下表所示:

如果按照Batch Size = 4 计算:

这仅是不开Speculative Decoding情况下的TPS, 如果打开我们假设在小batchsize的场景有2~3倍的TPS, 也就是说如果我们要满足端到端TPS > 100, 那么整个Forward计算的延迟需要维持在 30ms 以内(TPS = 33, 此时每层的时间大约为490us.
对比使用纯Rubin的解决方案, 如果按照传统的Two-Batch Overlap计算, TPS会降低一半左右, 因此被迫需要用更小的BatchSize来满足TPS的SLO. 因此才会有Jensen讲的2X的吞吐收益.
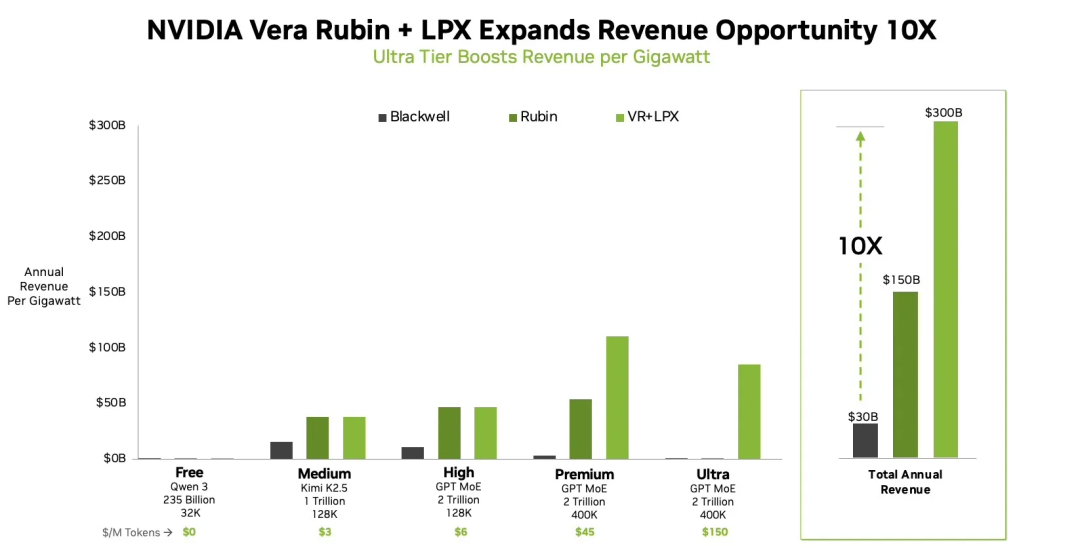
但是还有一个瓶颈点我们没有考虑, 由于Groq 3 LPU SRAM容量有限, EP-256我们无法放置, 因此需要在Groq-3 LPU内部加载一部分层的专家, 计算完一层再从Fabric Expansion Logic的DDR上Prefetch后面一层的Expert参数. 我们按照DDR5-6400计算, 单根内存的带宽为51.2GB/s, 4根总共204.8GB/s, 那么连接Groq 3 LPU的最大带宽1.6Tbps, 平均每Groq LPU带宽仅200Gbps, 如果我们使用MRDIMM 12800, 则平均每Groq LPU带宽为400Gbps, 一个专家需要传输44MB的参数, 即在400Gbps带宽下需要800us, 因此这个瓶颈点还是需要多个LPX-Rack才能缓解.
另一方面, 由于刚收购Groq, 专门做一块Fabric Expansion Logic ASIC也需要很长的时间, 因此当前time-to-market的方案只能选择FPGA. 而单块FPGA又受到总Serdes数和DDR控制器数量的限制, 我估计 Nvidia 在交付 LPX ComputeTray 时还需要 2 块FPGA 共计 8 通道的 DDR5 控制器才能满足异步加载专家参数的延时需求.
Nvidia的官方博客还讲述了Groq LPU的另一个使用场景: 推测解码
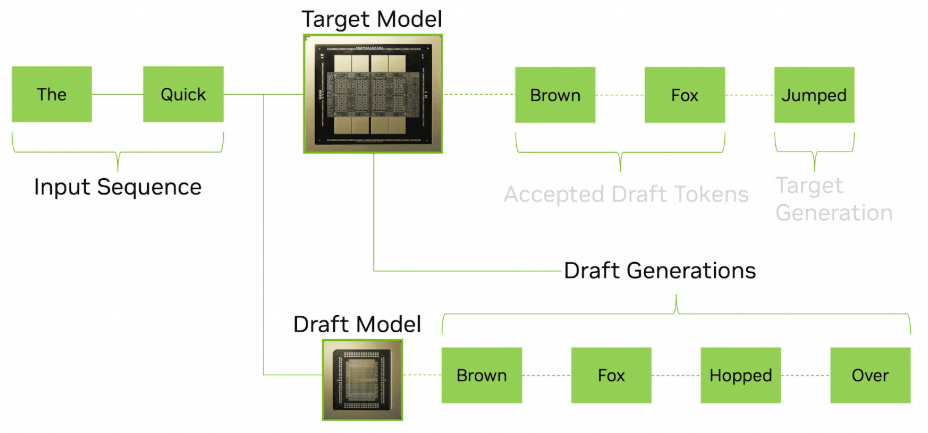
我们以Eagle-3算法为例, 通常推测解码的模型是一个很小规模的模型, 整个算法如下图所示:
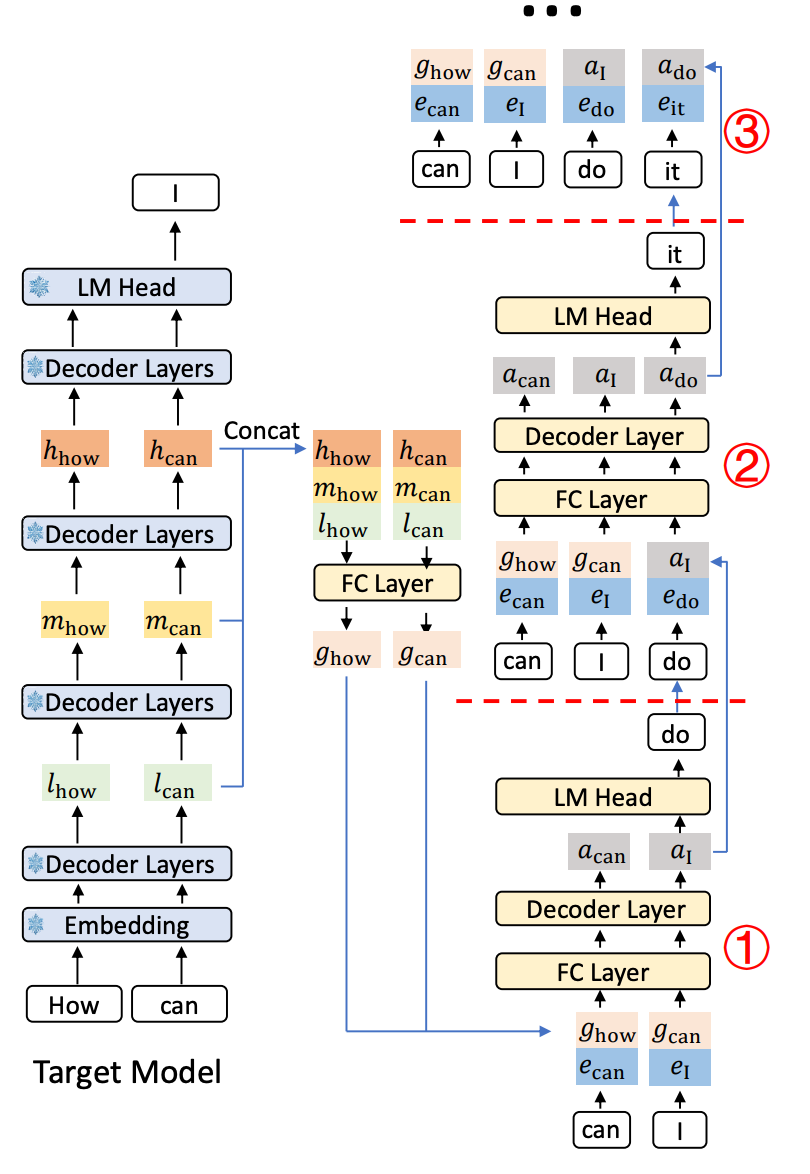
目标模型已经生成了 How Can I, 在生成 “I”的时候, 我们不光记下这个词, 还从AI的大脑里把与 "How" 和 "can" 相关的早、中、晚期思考过程(低、中、高层特征)都抽了出来. 然后把这些不同阶段的思考过程 "揉" 在一起, 得到一个更精华的特征 和 .
然后利用草稿模型处理, 我们把刚刚得到的精华特征 和新生成的词 "I" 的信息(词嵌入 )一起喂给它. 它经过一番计算, 得到一个中间结果 , 这个结果通过目标模型的 "翻译器"(LM头), 就猜出了下一个词是 "do".
现在我们要猜 "do" 后面的词. 可是 "do" 只是我们的猜测, 还没经过大AI的确认, 所以我们拿不到它对应的 "精华特征" . 怎么办呢? EAGLE-3用了一个巧妙的替代方案: 直接用上一步生成的那个中间结果 来假装是 "I" 的精华特征 . 然后, 把这个假装的 (也就是 ) 和新猜出来的词 "do" 的信息 () 一起喂给小助手, 它又一番计算, 得到 , 进而猜出下一个词 "it".
整个Eagle-3的草稿模型是很小的, 通常只有3~4GB, 因此可以完全在Groq 3 LPU上放置. 由于整个LPX机柜有256卡, 其实我们还可以多放置几份Draft Model来提高并行处理.
当HBM和DDR供应都非常紧张时, 同时北美电力和数据中心供应也紧张时, 如何在有限的供应链支持下更多的产生Tokens, 这也是Jensen需要解决的一个难题. DDR的涨价以及Agentic LLM对CPU实例也有大量的内存需求. 因此Rubin CPX伴随着DDR涨价相对于Rubin+HBM的成本差异也在快速缩小, 并且Rubin CPX也没有NVLink, 从占用机房面积/电力消耗以及对DDR供应链的影响来看, 已经没有存在的必要了.
然后Decoding的一些节点使用Groq 3 LPU也可以降低一些对HBM依赖和对电力的开销.
同时我们也注意到Vera CPU 和BF4 STS存储服务器也构建了机柜级的高密度解决方案, 这样也可以进一步降低数据中心的占地面积以及共享一些液冷/供电的供应链进一步降低成本.
基于整个供应链约束下, 虽然看上去每个形态都在采用像大型机一样的机柜, 但是我们也能理解Jensen正在努力的去解决供应链的短缺来应对 token 使用量爆发性的增长.
在第二章我们可以看到 Fabric Expansion Logic(FEL) 是一个暂时的 time-to-market 方案, 我个人估计需要到 Groq 3.5(L35)支持 nvfp4 后, 针对参数量 > 1T 的模型才有比较明显的收益, 否则从FEL DDR 加载参数到 Groq 3 LPU中还是会受到带宽的约束, 使用nvfp4可以降低一半的带宽, 当然最终的解决方案还是要到Feynman 这一代, 将Groq LPU的C2C总线切换到Nvlink, 并且在CX10上支持NVlink同时添加FEL的功能挂载 DDR6 才能满足需求.

参考资料 [1] ShallowSim: https://github.com/zartbot/shallowsim


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




